Instagram은 2010년 10월에 서비스를 시작한 후 2011년 12월까지 불과 1년 만에 1,400만 명이 이용할 정도로 거대한 서비스로 성장했습니다. 이러한 스케일에 대응할 수 있는 시스템을 구축한 것은 단 3명의 엔지니어였습니다. 어떻게 이렇게 적은 인력으로 거대 시스템을 구축했는지에 대해, 전문 엔지니어인 레오나르도 크리드 씨가 해설하고 있습니다.
How Instagram scaled to 14 million users with only 3 engineers
How Instagram scaled to 14 million users with only 3 engineers
Instagram's guiding principles and tech stack explained simply
engineercodex.substack.com
레오나르도 크리드는 Instagram이 3명의 엔지니어로 안정적으로 거대한 서비스를 제공할 수 있었던 이유로서 아래의 3가지 원칙을 지켰기 때문이라고 말합니다.
・사물을 매우 단순화한다
・바퀴의 재발명은 하지 않는다
・가능한 실적이 있는 확실한 기술을 사용한다
초기의 Instagram의 인프라스트럭처에는 Ubuntu Linux가 사용되고 있어, Amazon이 운영하는 클라우드 서비스의 AWS 위의 EC2에서 작동했습니다. 한편, 프런트엔드 측은 2010년에 iOS 앱으로 출시되었습니다. Swift가 등장하는 2014년 이전의 릴리스로 인해 프런트 엔드는 Objective-C와 UIKit 등을 이용하여 구축한 것이 아닐까 크리드 씨는 추측하고 있습니다.

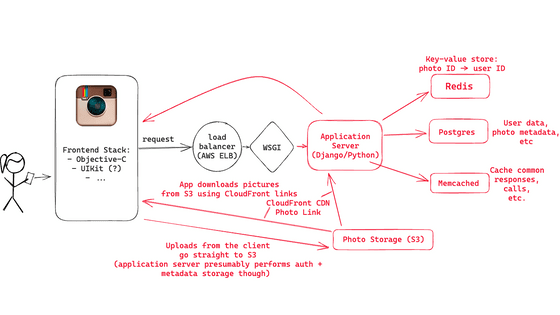
앱의 요청은 먼저 로드 밸런서에 도착합니다. Instagram의 백엔드에는 3개의 NGINX 인스턴스가 설치되었으며 가동 상황에 따라 로드 밸런서가 적절한 애플리케이션 서버로 요청을 전달합니다.
Instagram의 애플리케이션 서버는 Python의 장고로 작성되었으며 WSGI 서버로 Gunicorn을 사용했습니다. 그리고 Fabric을 이용하는 것으로 동시에 많은 인스턴스로 커멘드를 병렬 실행 가능하게 해, 코드의 배치를 고속화하고 있었다는 것.
애플리케이션 서버는 Amazon High-CPU Extra-Large 머신에서 실행되며 25대 이상 설치되었습니다. 서버가 상태 비저장이기 때문에 요청 수가 많은 경우에는 머신을 추가하여 대응할 수 있었습니다.

애플리케이션 서버가 사용자의 메인 피드를 생성할 때 다음 데이터가 필요합니다.
· 최신 관련 이미지 ID
· 해당 이미지 ID와 일치하는 실제 이미지 데이터
· 해당 이미지에 해당하는 사용자 데이터
이러한 데이터를 수집하여 메인 피드의 데이터를 생성하는 프로세스를 가속화하기 위해 Instagram에서는 다양한 방법이 이용되고 있었습니다.
◆ Postgres 데이터베이스
Postgres 데이터베이스에는 사용자 및 사진 메타데이터 등 Instagram 데이터의 대부분이 저장되어 있으며 Postgres와 Django 간의 연결에서는 PgBouncer를 사용하여 연결 풀이 이루어집니다. 2012년 시점에서 Instagram에는 초당 25장 이상의 사진과 90건 이상의 "좋아요!"가 투고되었기 때문에, 그 액세스량에 대응하기 위해 수 천의 "논리"샤드가 몇 개의 물리 샤드에 매핑되었다는 것.
인스타그램은 위의 액세스가 심각했기 때문에, 다른 논리 샤드로 데이터를 처리했을 경우라도 시간에 따라 재정렬할 수 있는 채로 중복되지 않는 ID를 생성하는 기술을 만들어 냈습니다. Instagram 공식 해설에 따르면 ID는 아래 내용으로 구성되어 있습니다.
· 밀리 초 단위의 시간을 41 비트
· 논리 샤드 ID를 나타내는 13 비트
· 자동 증가 시퀀스의 10 비트
이것들을 조합하는 것으로, 샤드 각각에 있어서 1밀리 세컨드마다 1024개의 중복되지 않는 ID를 생성할 수 있어, 또한 시간순으로 재정렬할 수 있게 되어 있습니다.
◆ 이미지 스토리지
이미지 스토리지에는 Amazon S3를 이용하고 있어 몇 테라바이트의 데이터가 보존되었다는 것. S3에 저장된 데이터는 Amazon CloudFront를 통해 전송되었습니다.
◆ 캐시
인스타그램에서는 Redis를 사용해 약 3억 장의 이미지와 투고한 유저와의 매핑을 보존해, 메인 피드나 액티비티 피드의 이미지를 취득할 때에 어느 Postgres 샤드에 액세스 하면 좋은지 알 수 있습니다. Redis는 복수의 서버로 샤딩되고 있어 모든 데이터를 메모리상에 보존하는 것으로 액세스 속도를 향상하고 있었다고 합니다. 해시화를 구사함으로써 3억 개의 매핑 데이터를 5GB의 영역에 저장하는 것이 가능했습니다.
또한 Django의 캐시에는 6개의 Memcached 인스턴스를 이용하고 있었다는 것. 2013년에는 초당 수십억 개의 요청을 처리하기 위해 Memcached를 어떻게 확장했는지에 대한 논문을 발표했습니다.
이렇게 하여 사용자가 팔로우하는 사람들의 최신 이미지를 피드로 열람할 수 있게 된 것입니다.

Postgres와 Redis는 모두 마스터 및 복제본 설정에서 실행되며 Amazon EBS 스냅샷을 사용하여 백업을 자주 생성하는 것 외에도 백엔드에서는 Gearman을 사용하여 작업을 적절한 시스템으로 나누며, 모든 팔로워에게 새로운 이미지 게시와 같은 활동을 알리는 등의 비동기 작업이 배분되었습니다.

푸시 알림의 경우 오픈 소스 범용 Apple 푸시 알림 서비스 공급자 pyapns를 사용했습니다.
또, 에러의 감시에 대해서는 오픈 소스 Sentry 나 Munin, Pingdom을 사용하고 있었다고 합니다. Sentry는 Python 오류를 실시간으로 감지했으며 Munin은 시스템 전체의 통계를 그래프로 표시하여 이상을 경고하는 역할을 했습니다. Pingdom은 외부에서 서비스를 모니터링하는 데 사용되었습니다.
이러한 기술을 활용함으로써 Instagram은 단 3명의 엔지니어로 1,400만 명을 지원하는 서비스를 제공할 수 있었다는 것입니다.

'트렌드 이슈 · 토픽' 카테고리의 다른 글
| 「표정 바꾸기」나 「흔들림 보정」 등 Pixel 8 시리즈에 탑재되는 카메라 기능 정리 (0) | 2023.10.05 |
|---|---|
| "인도제 아이폰 품질은 끔찍하다"라는 거짓 소문이 중국 소셜 미디어에서 퍼지고 있다 (0) | 2023.10.05 |
| NFT는 죽어 버려, 대부분 무가치하게 되고 있다는 지적 (0) | 2023.10.04 |
| 구름의 훨씬 위에서 발생하는 붉은 번개, 「레드 스프라이트」를 포착한 이미지를 NASA가 공개 (0) | 2023.10.04 |
| Steam상에서는 어떤 게임이 인기인지 「게임 타이틀」로 분석, 수익성이 높은 단어란? (0) | 2023.09.08 |
| iOS 사용자는 Android 사용자보다 앱 스토어에서 돈을 쓰는 경향이 있어, "사용자로서의 가치가 7.4배 높다"고 평가 (0) | 2023.09.08 |
| 미국 국방성이 UFO 정보 정리 사이트를 개설, 정체 불명의 비행 물체를 기록한 동영상이 다수 (0) | 2023.09.07 |
| 유전자 편집 기술 「CRISPR」을 사용하여 암세포를 건강한 세포로 바꾸는 실험에 성공 (3) | 2023.09.07 |



