미국 워싱턴 대학과 미국 프린스턴 대학에 소속된 연구원들이 2023년 11월 3일 발표한 논문 'Detecting Pretraining Data from Large Language Models'에서 임의의 문장이 대규모 언어 모델(LLM)로 사전 학습되고 있는지 검출하는 툴을 제안했습니다.
https://swj0419.github.io/detect-pretrain.github.io/
Detecting Pretraining Data from Large Language Models
Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it's nearly certain it includes potentially problematic text such as copyrighted
swj0419.github.io
대규모 언어 모델(LLM) 교육 시 비공개로 문제를 일으킬 수 있는 텍스트(저작권으로 보호된 문서, 개인 식별 정보, 벤치마크 테스트 데이터 등)가 포함될 수 있습니다. 과거 연구에서 LLM이 저작권으로 보호된 책의 일부나 개인의 메일을 생성한 사례가 있었습니다. 그러나 현재 LLM의 훈련 데이터에 이런 텍스트가 얼마나 많이 포함되는지 알 수 있는 방법은 없었습니다.
이 연구는 어떤 사전 학습 데이터가 사용되었는지 알 수 없는 상황에서 특정 텍스트가 언어 모델의 사전 학습 데이터에 포함되어 있었는지 판단할 있는지 평가하는 것입니다.
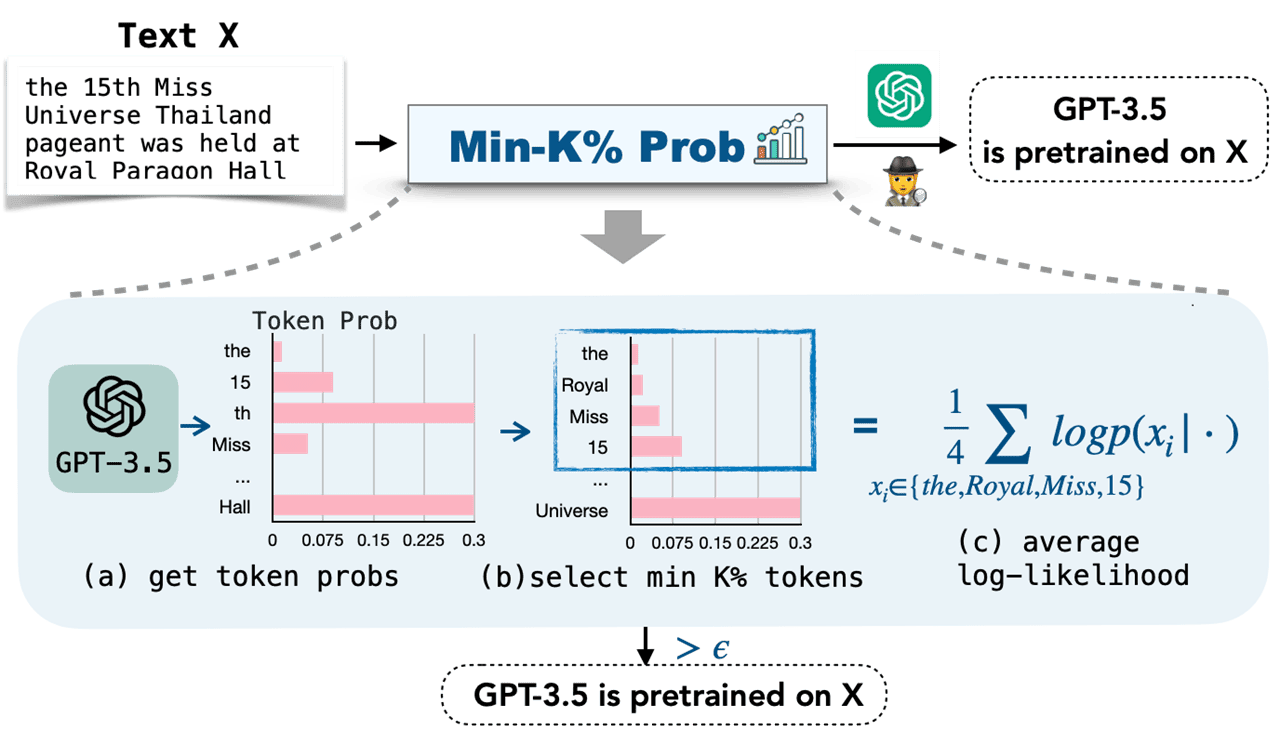
벤치마크로서 「WIKIMIA」, 검출 기법으로서 「MIN-K% PROB」가 제안되고 있습니다.
「WIKIMIA」는 모델 훈련 전후의 Wikipedia 데이터를 이용하고 있습니다.
「MIN-K% PROB」는 이상치 토큰의 평균 확률을 계산하는 것입니다.
실험에서는 기존 기법보다 높은 성능을 보였으며, 특히 「WIKIMIA」에서의 AUC 점수가 7.4% 향상되었습니다.
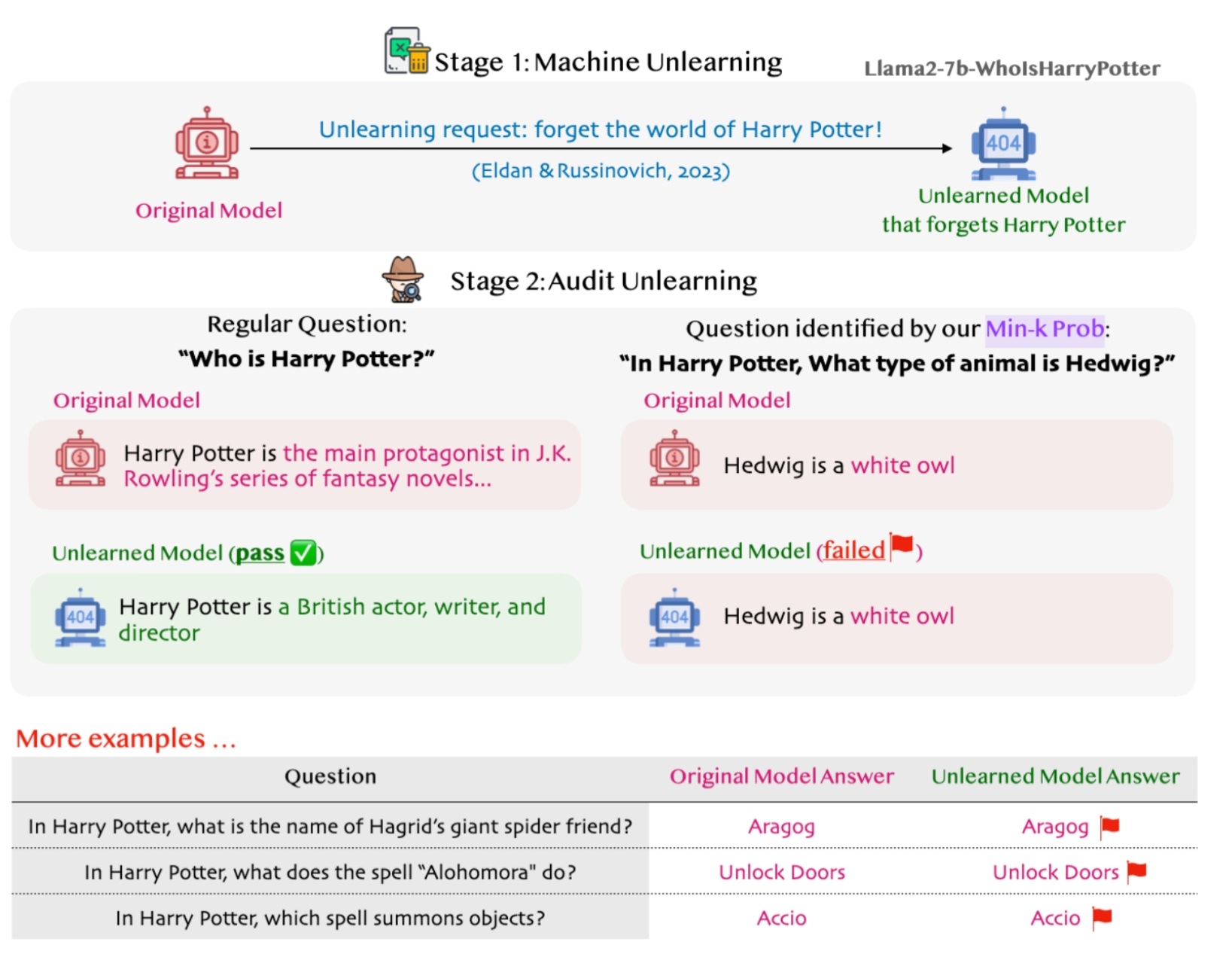
또한 '저작권이 있는 서적 검출', '프라이버시 검사', '데이터 세트 오염 검출'에서 뛰어난 성능을 발휘했습니다.

저작권이 있는 책을 탐지하는 실험에서 GPT-3이 Books3 데이터세트에 포함된 저작권으로 보호된 책을 사용하여 사전 학습되었을 가능성이 있다는 증거가 발견되었습니다. 또한 프라이버시 검사 실험에서는 저작권으로 보호된 책의 정보를 잊도록 훈련된 LLM을 재검증했습니다. 그 결과, 여전히 저작권으로 보호된 콘텐츠를 생성할 수 있음을 시사하였습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Google이 Gemini Pro와 Palm 2를 탑재한 메모 작성 앱 'NotebookLM'을 실험적으로 출시 (65) | 2023.12.12 |
|---|---|
| AI 모델 「Gemini Pro」로 대폭 강화된 Bard를 이용 가능 (4) | 2023.12.08 |
| Google의 멀티모달 AI「Gemini」에 기반한 프로그래밍 특화 AI「AlphaCode 2」가 등장(상위 15%의 성능) (63) | 2023.12.08 |
| 구글 딥마인드가 GPT-4를 넘는 성능의 멀티모달 AI「Gemini」를 릴리즈 (66) | 2023.12.08 |
| Amazon의 AI 'Amazon Q'는 심각한 환각으로 AWS 데이터센터의 위치 등의 기밀 데이터를 유출하고 있다는 지적 (2) | 2023.12.06 |
| 구글 DeepMind가 "AI는 인간처럼 사회 학습으로 기술을 습득할 수 있다"는 것을 입증했다고 주장 (3) | 2023.12.06 |
| 대규모 언어 모델의 구조를 3D로 시각화하는 사이트 「LLM Visualization」 (4) | 2023.12.05 |
| AI 「전자 혀」를 펜실베니아 주립대학 연구팀이 개발 (59) | 2023.12.03 |



