
스탠퍼드 대학의 크리스토퍼 레 교수가 이끄는 연구팀이 GPU를 최대한 활용하여 일정 시간당 연산량을 극대화하기 위한 도메인 고유 언어(DSL : 도메인 특화 언어라고도 하며, 특정 태스크용으로 설계된 컴퓨터 언어) 「ThunderKittens」 를 출시했습니다.
ThunderKittens: A Simple Embedded DSL for AI kernels · Hazy Research
ThunderKittens: A Simple Embedded DSL for AI kernels
good abstractions are good.
hazyresearch.stanford.edu
이 연구팀은 NVIDIA H100을 사용하여 GPU 사용률을 극대화하기 위해 노력했습니다. H100은 Tensor 코어를 사용하는 반정밀 행렬 곱셈 계산의 성능이 989TFLOPS이며, 다른 모든 계산 능력의 합계인 약 60TFLOPS를 크게 웃돌고 있습니다. 즉, H100의 GPU 사용률은 대부분 Tensor 코어의 사용률에 의존합니다.
연구팀은 모든 GPU 사이클에서 Tensor 코어가 일을 할 수 있도록 'WGMMA 명령', '주소 생성', '공유 메모리', '점유율'이라는 4가지 부분을 집중적으로 개선했다는 것.
・ WGMMA 명령
H100에는 「warp group matrix multiply accumulate(WGMMA)」 라고 불리는 새로운 명령 세트가 추가되어 있습니다. WGMMA 명령어를 사용하면 스트리밍 멀티프로세서(SM)의 128개의 스레드가 협조적으로 동기화되어 공유 메모리에서 직접 행렬 연산을 수행합니다. 연구팀의 마이크로벤치마크에 의하면 WGMMA 명령을 사용하지 않으면 GPU 사용률은 약 63%에서 한계에 달해버린다는 것.
그러나 WGMMA 명령을 사용할 때 공유 메모리에 데이터를 어떻게 배치해야 하는지에 대한 문제는 매우 복잡하며, NVIDIA 문서가 잘못되어 있는 경우도 있어서 적절하게 데이터를 배치할 수 있을 때까지 연구 팀은 매우 힘들었다고 합니다. 그렇다고 해도, WGMMA 명령을 사용하지 않으면 GPU 사용률의 37%가 날아가기 때문에, 아무래도 무시할 수는 없는 문제였습니다.

• 주소 생성
H100은 Tensor 코어와 메모리가 모두 매우 빠르게 작동하기 때문에 데이터를 fetch 하기 위한 메모리 주소를 생성하는 것만으로도 칩 리소스를 상당히 소비합니다. NVIDIA가 준비하고 있는 Tensor Memory Accelerator(TMA)라는 명령을 사용하는 것으로 글로벌 메모리나 공유 메모리로 다차원 텐서 레이아웃을 지정해, 그 텐서의 일부를 비동기로 fetch 하는 것이 가능합니다. TMA를 사용하면 주소 생성 비용을 크게 줄일 수 있습니다.
• 공유 메모리
공유 메모리의 단일 액세스의 레이턴시는 약 30 사이클로 비교적 작고, 지금까지는 다른 부분이 병목이었기 때문에 간과되고 있었지만, 이번과 같은 「최대의 최적화」 에 임할 경우, 이러한 작은 대기 시간에도 신경을 써야 했습니다.
연구팀은 레지스터와 공유 메모리 간의 데이터 이동을 가능한 한 줄이면서 데이터를 이동해야 할 경우에는 WGMMA 명령이나 TMA 명령을 사용하여 비동기적으로 공유 메모리와 레지스터 간 데이터를 이동시켰습니다.
• 점유율
점유율이란 GPU가 실행할 수 있는 최대의 Warp 수에 비해 실제로 실행한 Warp 수가 어느 정도인가 하는 수치입니다. H100에서는 칩의 비동기 기능이 강화되고 있어 메모리의 fetch나 행렬 곱셈의 실행, 공유 메모리의 삭감의 실행, 레지스터에서의 연산의 동시 실행 등 하드웨어를 바쁜 상태로 유지하는 방법이 있기 때문에, 그 이전의 세대 하드웨어보다 점유율이 낮아도 성능을 높일 수 있다는 것.
하지만 점유율이 높은 쪽이 하드웨어의 실제 성능이 향상되기 쉬운 것은 틀림없습니다. 또한, A100이나 RTX 4090등의 하드웨어에서는 H100과 비교해 동기 명령 디스패치에의 의존도가 높기 때문에 점유율의 향상이 중요합니다.
위의 요소를 개선하기 위해 연구팀은 CUDA 내에 포함하기 위한 도메인 고유 언어(DSL)로서 "ThunderKittens"를 설계 및 릴리스했습니다.

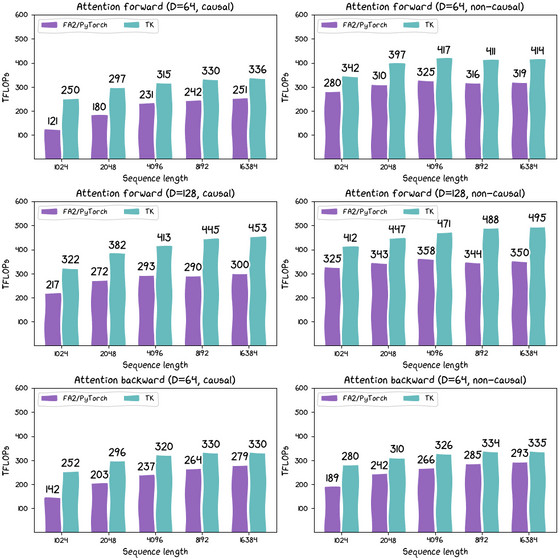
실제로 PyTorch의 FA2 를 사용한 경우와 ThunderKittens(TK)를 사용한 경우에 Flash Attention의 계산 능력이 얼마나 다른지를 계측한 결과는 아래 그림과 같다. 보라색은 PyTorch의 FA2이고 하늘색은 ThunderKittens의 계산 능력을 보여줍니다. 평균적으로 ThunderKittens는 약 30%의 성능 향상에 성공했습니다.]
또한, Linear Attention의 계산에 있어서는 ThunderKittens는 약 215TFLOPS로 계산을 실행할 수 있어, 기존의 방법에 비해 「큰 폭」 의 고속화를 달성할 수 있었습니다.

ThunderKittens의 코드는 GitHub에 오픈 소스로 공개되어 있습니다.
https://github.com/HazyResearch/ThunderKittens
GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels
Tile primitives for speedy kernels. Contribute to HazyResearch/ThunderKittens development by creating an account on GitHub.
github.com
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Microsoft가 동영상의 더빙 및 실시간 자막 번역 AI 기능을 엣지에서 공개 (3) | 2024.05.23 |
|---|---|
| Microsoft가 Copilot+PC용 언어 모델 「Phi-Silica」 의 일반 제공을 발표 (3) | 2024.05.23 |
| 애니메이션 특화 데이터 세트 「Sakuga-42M」이 등장 (4) | 2024.05.21 |
| GPT-4o의 중국어 토큰은 포르노와 스팸으로 오염됨 (5) | 2024.05.21 |
| OpenAI가 「GPT-4o(옴니: omni)」 를 발표 (4) | 2024.05.17 |
| Google이 오픈 소스 비주얼 언어 모델 'PaliGemma' 공개 (5) | 2024.05.16 |
| Google이 영상과 음성을 이해하고 질문에 답하는 AI 에이전트 「Project Astra」 를 발표 (5) | 2024.05.16 |
| Google이 학습 진화 AI 모델 「LearnLM」 을 발표 (5) | 2024.05.16 |



