
채팅 AI 'Claude' 등을 개발하는 AI 기업 'Anthropic'이 AI 모델의 내부 동작에 대해 수백만 개의 개념이 어떻게 표현되고 있는지 연구 결과를 보고했습니다.
Mapping the Mind of a Large Language Model\Anthropic
Mapping the Mind of a Large Language Model
We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model.
www.anthropic.com

AI 모델의 본체인 대규모 언어 모델(LLM)의 출력은 블랙박스로 취급되고 있으며, 입력에 대응한 출력이 왜 그 특정 응답으로 출력되는지는 불분명합니다. 때문에, 모델이 유해 · 편견 · 거짓 등의 위험한 출력을 하지 않을 것이라는 신뢰는 어렵습니다.
Anthropic은 이전부터 LLM의 내부에 대한 연구를 실시하고 있어, 2023년 10월에는 「특징」 단위로 정리하는 것으로 모델의 내부 상태를 표현하는 데 성공했습니다.
신경망의 내용을 분할하여 AI의 동작을 분석·제어하는 시도가 성공, 뉴런 단위가 아니라 '특징' 단위로 정리하는 것이 포인트
신경망의 내용을 분할하여 AI의 동작을 분석 · 제어하는 시도가 성공, 뉴런 단위가 아닌 '특징'
Google과 Amazon이 투자하는 AI 스타트업 Anthropic의 연구팀이 뉴럴 네트워크가 어떻게 언어나 이미지를 다루는지 밝혀내는 연구에서 개별 뉴런을 「특징(features)」이라는 단위로 정리하면 뉴럴 네트
doooob.tistory.com
2023년 10월의 연구 대상은 매우 단순한 모델이었지만, 그 후 보다 크고 복잡한 모델에 같은 기법을 적용해 연구를 실시해, 이번 Claude 3.0 Sonnet이라는 최첨단 모델 패밀리의 멤버를 대상으로 내부 상태의 대략적인 개념 상태를 매핑하는 데 성공했습니다.
예를 들면 「골든 게이트 브리지」라는 특징에 대응하는 토큰은 이런 느낌으로, 프롬프트 중 특징이 반응하는 부분이 주황색으로 표시되어 있습니다.

또한 코드 오류, 성별 바이어스, 비밀 유지에 관한 대화에 대한 대응 등 보다 추상적인 개념에 반응하는 특징도 발견되었습니다.

Anthropic은 특징의 활성화 패턴에 어떤 뉴런이 나타나는지를 조사하여 특징 사이의 "거리"를 측정했습니다. 골든게이트 브리지의 특징 근처에는 '알카트라즈 섬', '길라델리스크 에어', '골든 스테이트 워리어스', '캘리포니아 주지사 개빈 뉴섬', '1906년 지진', 샌프란시스코를 무대로 한 알프레드 히치콕 영화 '현기증' 등의 특징이 출현했다는 것.
또한 '내부 갈등(Inner Conflict)'의 개념 근처에는 '관계의 파탄', '대립하는 충성심', '논리적 모순' 외에 피할 수 없는 딜레마가 등장하는 소설 'Catch-22'등의 개념이 등장하고 있습니다. AI 모델의 개념 내부 구성은 인간이 생각하는 '유사성'과 어느 정도 대응하고 있으며, Claude의 뛰어난 유추 능력과 비유 능력의 증거일 가능성이 있다고 말해지고 있습니다.
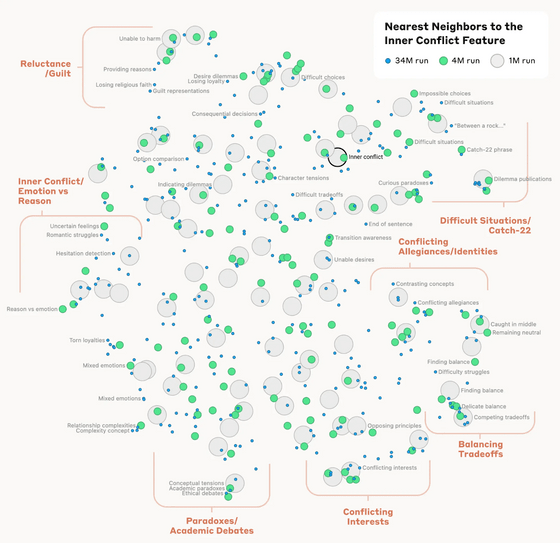
Anthropic 팀은 특정한 특징을 인위적으로 조작했을 때의 영향도 조사했습니다. 예를 들어 골든 게이트 브리지의 특징을 증폭하면 전혀 관련성이 없는 상황에서도 거의 모든 쿼리에 대한 대답으로 골든 게이트 브리지가 등장하게 되었다고 합니다.
Claude에는 스팸 메일을 읽을 때 반응하는 특징도 존재합니다. Claude에는 무해성을 높이는 트레이닝이 실시되고 있어, 평소에는 스팸 메일의 작성을 의뢰해도 Claude는 거부하지만, 이 특징을 강제적으로 유효하게 하여 스팸 메일 작성이 가능했습니다.
이번 연구 대상이 된 Claude 3.0 Sonnet은 "당신의 지혜는 의심의 여지가 없습니다"와 같은 칭찬에 반응하는 특징을 발견하고 있으며, 이 특징을 활성화함으로써 자기애가 충만한 사용자에게 화려한 칭찬으로 대응하게 됩니다. 본래의 응답에서는 유저의 실수를 정정하고 있습니다만, 과잉 칭찬 응답으로 유저에게 아양을 떠는 내용이 되었습니다.

특징을 조작함으로써 모델의 동작이 변화한다는 사실은, 특징이 입력 텍스트의 개념과 상관될 뿐만 아니라 모델의 동작을 인과적으로 형성한다는 것을 입증합니다.
Anthropic의 연구팀은 특정 기능을 조작하여 AI 시스템의 위험한 동작을 모니터링하고 원하는 결과를 유도하고 위험한 내용을 강제로 삭제할 수 있음을 시사합니다. 연구팀은 "모델을 깊게 이해하는 것이 모델을 보다 안전하게 만드는 데 도움이 된다."라고 말했습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 웨어러블 AI 디바이스 「Ai Pin」 이 매출 부진에 사업 매각도 검토 (2) | 2024.05.24 |
|---|---|
| NVIDIA의 2025년도 1분기 수익은 전년 대비 262% 증가, 특히 데이터센터 부문은 전년 대비 427% 증가한 역대 최고치 (2) | 2024.05.24 |
| 문장으로 게임을 개발할 수 있는 AI 게임 개발 환경 「Braindump」가 등장 (5) | 2024.05.23 |
| 「안전한 AI를 개발할 것」 을 AI 써밋 서울 2024에서 16개사가 합의 (3) | 2024.05.23 |
| Microsoft가 동영상의 더빙 및 실시간 자막 번역 AI 기능을 엣지에서 공개 (3) | 2024.05.23 |
| Microsoft가 Copilot+PC용 언어 모델 「Phi-Silica」 의 일반 제공을 발표 (3) | 2024.05.23 |
| 애니메이션 특화 데이터 세트 「Sakuga-42M」이 등장 (4) | 2024.05.21 |
| GPT-4o의 중국어 토큰은 포르노와 스팸으로 오염됨 (5) | 2024.05.21 |



