
3 개의 요점
✔️ 훈련 데이터에 존재하지 않는 이미지를 생성합니다. 보외법(Extrapolation)
✔️ 현시점으로 세계에서 가장 고해상도 이미지를 생성할 수 있는 GAN
✔️ 이미지를 패치(분할해서 잘게 쪼갠 것) 단위로 생성하여 계산량 절감
참고 1 : 보외법
보외법
해석학용어. 외삽법(外揷法)이라고도 한다. [그림]에서와 같이, 곡선 위의 2점 A, B와 이 2점으로 한정된 부분 위에 몇 개의 점을 알고 있을 때, A, B로 한정된 부분 위의 다른 점 P의 위치를 추정하는 보간법(補間法)에 대하여 A, B로 한정된 밖의 부분의 점 Q의 위치를 추정하는 것을 보외법이라 한다.
terms.naver.com
참고 2 : GAN(생성적 적대 신경망)
GAN(생성적 적대 신경망)
GAN은 생성적 적대 신경망(Generative Adversarial Network)의 약자로, 차세대 딥러닝 알고리즘으로 주목받고 있다. 진짜 같은 가짜를 생성하는 모델과 이에 대한 진위를 판별하는 모델의 경쟁을 통해 진짜 같은 가짜 이미지를 만들 수 있다. 기존에 인간이 정제한 데이터를 바탕으로 학습하는 지도 학습 방식에서 벗어나 스스로 답을 찾는 비지도학습 방식을 사용해 인공지능(AI) 연구의 새로운 장을 열었다는 평가를 받지만, 악용 가능성에 대한
terms.naver.com
요약
GAN에는 한 가지 한계가 있다고 알려져 있습니다. 그것은 훈련 데이터에 없는 이미지의 생성은 불가능하다는 점입니다.
이 훈련 데이터의 생성 범위(훈련 데이터가 샘플링될 것이라고 가정되는 범위)의 외부 생성을 보외법(Extrapolation)이라고 합니다. 하지만 이번에 소개하는 COCO-GAN에서는 이 불가능을 가능하게 하는 결과를 보여주고 있습니다.
결과는 그것뿐만이 아닙니다.
현재 GAN은 Progressive GAN(PGGAN)과 BigGAN 등 현실의 이미지와 분간이 안 될 정도로 고해상도 이미지의 생성이 가능해졌습니다. 그러나 GAN은 고화질 이미지를 생성할 수 있는 반면, 그 훈련에 매우 긴 시간이 소요됩니다. 1 Progressive GAN 훈련을 위해 NVIDIA에서 가장 빠른 GPU인 Tesla V100을 하나 이용하여 2주가 소요됩니다 (1024 × 1024의 CelebA-HQ 데이터셋의 경우)
COCO-GAN은 패치(분할해서 잘게 쪼갠 것) 단위로 생성하는 참신한 접근방식으로 훈련시간과 생성시간을 단축하고 있습니다. 또한 COCO-GAN은 현재 세계에서 최고의 고화질 이미지를 생성하는 GAN이기도 합니다. 무서운 것은, COCO-GAN이 고안한 방법은 아주 간단하지만 그 위력이 매우 크고, 이 발상만으로 추정, SOTA(State of the Art), 계산량 감소, 파노라마 이미지 생성의 4가지를 한 번에 달성해 버렸습니다.
그러면 한번 알아봅시다.
이 논문의 주요 아이디어와 공헌
주요 아이디어는 한 가지입니다. 아래 그림으로 제안된 기법을 살펴보겠습니다.
이미지를 패치 단위로 분할하여 생성
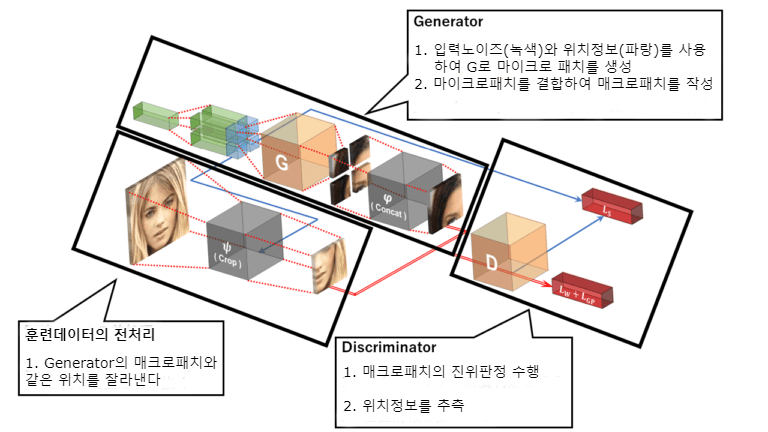
지금까지의 GAN과 다른 점은 이미지 전체를 한 번에 생성하는 것이 아니라 마이크로 패치를 생성하여 합성 매크로 패치를 만들고, 매크로 패치마다의 GAN훈련을 하는 것입니다. 결국 전체 이미지를 생성하는 일은 훈련 동안에는 없고, 테스트 단계에서만 아래와 같이 마이크로 패치로 이미지 전체분을 생성하여 합성합니다.

공헌
이 논문의 공헌은 4가지가 있습니다.
|
1. 훈련 데이터 범위 외의 데이터를 생성하는 보외법 실현 |
실험 결과
실험 결과 1 : 훈련 데이터 범위 외의 데이터를 생성하는 보외법 실현

위 그림은 생성된 침실의 이미지이며, 고화질의 이미지가 생성된 것을 확인할 수 있습니다. 그러나 놀라운 것은 고해상도뿐만이 아닙니다. 이 이미지는 어느 큰 그림에서 잘라진 일부입니다.
아래가 원래 생성된 이미지입니다.

위 그림의 빨간색 선의 내부가 잘라진 부분입니다. 본래는 위 그림과 같이 해상도가 384 × 384의 이미지입니다.(잘라진 부분은 훈련 데이터와 같은 해상도 256 × 256)
논문 저자는 이 그림의 외부 경계를 넘어서 훈련 데이터 외부 생성을 Beyond-Boundary Generation라는 이름으로 제안하고 있습니다. 이렇게 훈련 데이터에 존재하지 않는 부분을 생성 가능하게 한다는 것은 보통 어려운 일이 아닙니다. (패치 단위 훈련만으로는 바깥쪽이 약간 부자연스러워지기 때문에, 저자는 논문 부록에서 외부를 자연스럽게 하는 테크닉을 설명하고 있습니다.)
Generator는 훈련 데이터 범위에 취득 분포가 가까워지도록 훈련을 진행합니다. 훈련 데이터 범위 밖의 분포를 획득한다는 것은 훈련 데이터에 얽매이지 않고, 각 생성 데이터의 정합성은 지키면서 학습을 진행한다는 것입니다. 이 결과는 GAN의 커다란 돌파구가 될 수 있습니다.
인간은 초원에 있는 개와 집안에 있는 고양이를 각각 볼 때 개와 고양이가 동시에 초원에 있는 것을 상상할 수 있습니다. 이것은 우리가 훈련 데이터의 선입관에 얽매이지 않고, 정합성은 지키며 상상할 수 있기에 가능한 일입니다. GAN에서도 이와 같은 일이 가능할지도 모른다는 것을 시사하고 있습니다.
실험 결과 2 : GAN으로 세계에서 가장 고화질의 이미지를 생성

위 그림은 생성된 연예인의 이미지입니다 (CelebA). 매우 고해상도인 이미지를 생성하고 있음을 분명히 알 수 있습니다. 질적으로 높은 것은 분명하지만 양적으로도 SOTA를 달성하고 있습니다.
아래는 정량평가를 실시하고 있는 표를 보여줍니다.

평가 지표는 FID(Fréchet Inception Distance)라는 훈련 데이터 생성 이미지와 분포 간 거리(얼마나 생성 이미지가 훈련 데이터에 가까운가)를 비교합니다.
COCO-GAN은 CelebA-HQ 이외의 데이터 세트에서 SOTA를 달성하고 있습니다. 이 결과는 패치마다 생성하는 차원이 작기 때문에(4 × 4의 경우 16차원이고, 256 × 256의 경우는 65,536차원) 탐색을 용이하게 하며 옆의 패치와 일관성을 갖지 말라는 기하학적 제약을 두기 때문에 최적화하기 쉬운 것이라고 생각됩니다.
실험 결과 3 : 파노라마 이미지 생성

위 그림은 파노라마 이미지를 720°까지 확장시켰을 때 생성 결과입니다. 360° 이상까지 아무것도 변하지 않기 때문에 이 실험은 도대체 뭐야? 싶을지도 모릅니다. 일반 GAN에서는 이미지가 순환하고 있다(한 바퀴 돌고 다시 한 바퀴 돌아도 같은 풍경)는 것은 학습할 수 없습니다. 그러므로 일반적인 GAN에서 파노라마 이미지를 순환시켜 생성할 때는 특수처리가 필요합니다. 그러나 COCO-GAN에서는 위치 정보를 각도(sin과 cos)로 표시하여 순환성을 획득하는 것이 가능합니다. 이것이 가능하면 뭐가 좋은가 하면 VR 등으로 제한된 계산 자원에서 고해상도 시야 생성이 요구됩니다. 그래서 COCO-GAN을 사용함으로써 순환성을 유지하면서 적은 계산으로도 시야 생성이 가능해진다고 저자는 용도를 언급하고 있습니다.
결론
GAN데이터셋이 선입견에 묶여 있기 때문에 보외법이 어렵다는 논문이 ICLR2020에 게시되었을 뿐인데 외삽(外揷)을 이루어 낸 논문으로 매우 큰 공헌을 하게 되었습니다. 앞으로는 GAN일반화의 이정표가 될 것으로 기대됩니다. 딥러닝은 이제 한계라는 소문에 절망하고 있을 틈은, 이제 우리에게 없을지도 모릅니다.
COCO-GAN : Generation by Parts via Conditional Coordinating
(Submitted on Mar 2019 in Proc of ICCV)
written by Chieh Hubert Lin, Chia-Che Chang, Yu-Sheng Chen, Da-Cheng Juan, Wei Wei and Hwann-Tzong Chen.
accepted by the International Conference on Computer Vision, ICCV 2019
ICCV 2019 Open Access Repository
Chieh Hubert Lin, Chia-Che Chang, Yu-Sheng Chen, Da-Cheng Juan, Wei Wei, Hwann-Tzong Chen; The IEEE International Conference on Computer Vision (ICCV), 2019, pp. 4512-4521 Humans can only interact with part of the surrounding environment due to biological
openaccess.thecvf.com
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| 메타 학습의 단점을 극복? CACTUs의 등장 (0) | 2020.01.08 |
|---|---|
| 알리바바, 고객 서비스 만족도를 대화 로그로 예측 (0) | 2020.01.07 |
| 일본의 AI사업을 견인하는 인기 기업 랭킹 5선 [2020년판] (0) | 2020.01.06 |
| 단어의 삽입/삭제를 이용한 새로운 문장생성 기법이 등장 (0) | 2020.01.03 |
| 생성 이미지를 마음대로!? 새로운 GAN 프레임워크 'VCGAN' (0) | 2020.01.02 |
| AI학습을 더 인간 답게? 학습 경험을 살린 MTL학습법의 등장! (0) | 2020.01.01 |
| 3차원 모션 추정! 이미지 속 인간의 움직임을 3차원으로 재현! (0) | 2019.12.31 |
| Minecraft에서 강화학습?! 데이터셋 'MineRL'의 탄생 (0) | 2019.12.27 |



