기능성 자기공명영상(fMRI)은 뇌의 활동 부위를 비 침습적으로 측정하는 방법입니다. 이 fMRI로 측정한 뇌의 기능 활동으로부터 Stable Diffusion을 사용해, 피험자가 본 화상을 재구축하는 데 성공했다는 논문을, 오사카대 대학원 생명 기능 연구과의 타카기 유 조교가 발표했습니다.
Stable Diffusion with Brain
Stable Diffusion with Brain Activity
Accepted at CVPR 2023 Yu Takagi* 1,2 , Shinji Nishimoto 1,2 1. Graduate School of Frontier Biosciences, Osaka University, Japan 2. CiNet, NICT, Japan
sites.google.com
High-resolution image reconstruction with latent diffusion models from human brain activity | bioRxiv
High-resolution image reconstruction with latent diffusion models from human brain activity
Reconstructing visual experiences from human brain activity offers a unique way to understand how the brain represents the world, and to interpret the connection between computer vision models and our visual system. While deep generative models have recent
www.biorxiv.org
인간이 눈이나 귀로 무언가를 인지하거나 떠올릴 때, 뇌세포 활동이 활발해집니다. 뇌세포의 활동이 활발해지면 그 부위의 혈류가 증가합니다. fMRI는 이 혈류 증가로 인한 약간의 자기 변화를 포착함으로써 뇌의 활동 부위를 시각화할 수 있는 장치로, 수술을 필요로 하지 않는 비침습적 측정이 가능합니다.
시각으로 무언가를 포착한 사람의 뇌의 기능 활동으로부터, 그 사람이 얻은 시각 체험을 재현하려는 시도는 지금까지의 연구에서도 행해져 왔습니다. 시각체험은 초기 시각령(visual cortex : 시신경으로부터 흥분을 받아들이는 대뇌피질의 부분)에서 다루어지는「영상 특징」과, 보다 고차원의 시각령에서 다루어지는「문장적 의미 특징」으로 구성됩니다만, 다카기 조교의 연구는 이 2개를 조합하고, Stable Diffusion을 사용하여 이미지화를 실현한 것입니다.
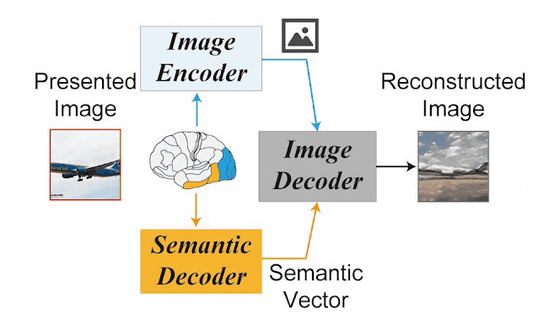
다음은 Stable Diffusion의 구조를 나타낸 그림입니다. 화상(X)를 화상 인코더(ε)로 읽어 들여 잠재 표현(z)으로 변환하고, 노이즈를 부가시키는 확산 프로세스를 통해 Zt 로 변환. 이 Zt 를 UNET 인코더를 통과시켜 확산 프로세스의 반대, 즉 노이즈를 제거합니다. 이때 입력한 텍스트를 텍스트 인코더 CLIP(τ)를 사용해 특징량(c)로 변환합니다. 이 c로 노이즈 제거의 방향성을 조정함으로써 새로운 잠재 표현(Zc) 을 생성하고, 이 Zc 를 화상 디코더(D)에 읽어 들여 새로운 화상(X')을 생성합니다.

그리고 타카기 조교의 연구가 아래로, fMRI로 측정한 초기 시각령의 활동(영상 특징)으로부터 잠재 표현(z)을 취득해, 화상 디코더에 읽어 들여 화상(Xz)를 생성합니다. 이 이미지의 크기 조정 복사본을 Stable Diffusion의 이미지 인코더에 로드하고 확산 프로세스를 거쳐 잠재 표현(Zt)을 생성합니다. 그리고, 고차원 시각령의 활동(문장적인 의미 특징)으로부터 선형 모델에 의해 얻은 텍스트 표현에서 텍스트 인코더로 특징량(c)을 획득. UNET 인코더에서 Zt 와 c에서 잠재 표현(zc)를 생성하고 이를 디코더에 통과시켜 이미지(Xzc)를 생성합니다. 이 Xzc는 피험자가 본 이미지를 Stable Diffusion을 사용하여 재구성한 이미지가 됩니다.

실험에서 피험자에게 제시된 이미지가 빨간색 테두리의 Ground Truths이고,
그 피험자의 초기 시각령에서 생성한 이미지가 Z,
고차원 시각령의 뇌 활동에서 텍스트 인코더로 생성한 이미지가 C,
최종적으로 Stable Diffusion에 의해 생성된 이미지가 Zc입니다.
빨간색 프레임의 이미지와 Zc를 비교하면 확실히 피험자가 본 이미지를 근접하게 재구성하고 있다는 것을 알 수 있습니다.

다만, 개인별로 뇌의 형태나 구조가 다르기 때문에, 한 명의 개인으로부터 만든 모델을 직접 타인에게 적용할 수는 없다는 것.
다음은 4명의 피험자에게 좌측의 이미지를 보여준 후, Stable Diffusion을 통해 생성한 것입니다. 어딘가 공통점이 있는 것 같으면서도 다른 이미지가 생성되고 있다는 것을 알 수 있습니다. 그러나, 개인차를 보정하는 기법은 몇 가지 제안될 수 있으며, 피험자를 어우르는 모델의 적용은 일정 정밀도로 가능하지 않을까 하고 타카기 조교는 기대하고 있습니다.

또한 타카기 조교는 잠재 확산 모델의 특정 구성 요소를 뇌 활동 부위에 매핑하여 잠재 확산 모델의 각 구성 요소를 뇌신경 과학의 관점에서 정량적으로 해석하려는 시도도 실시하고 있습니다.
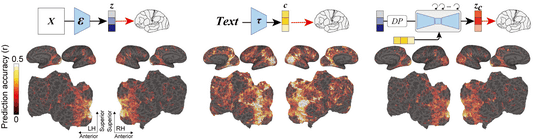
기존의 연구에서도 기계 학습을 사용하여 fMRI의 데이터로부터 화상을 생성하는 것을 목표로 한 연구는 있었지만, 그 훈련이나 파인 튜닝이 필요했습니다. 그러나 타카기 조교의 기법에서는 fMRI의 측정 결과로부터 잠재 표현을 작성하기 위한 선형 모델을 트레이닝하는 것뿐으로, Stable Diffusion도 버전 1.4의 모델을 그대로 이용하고 있습니다.
타카기 조교의 선형 모델의 트레이닝용 데이터 세트에는, 최대 1만 장의 이미지를 반복적으로 보고 있는 피험자의 뇌 활동 측정 데이터를 정리한「Natural Scenes Dataset」이 이용되었다고 합니다.
타카기 조교에 의하면,「무언가를 체험(지각)하고 있을 때의 뇌 활동과 그것을 생각하거나 꿈을 꾸고 있을 때의 뇌 활동에는 일정한 상동성이 있는 것으로 알려져 있어, 이 성질을 이용하여 '생각' 또는 '꿈의 내용'을 일정 정밀도로 해독할 수 있습니다 」라고 코멘트. 다만,「(이번 연구는) 지각한 내용과 뇌 활동의 관계성을 조사하는 것으로, 마인드 리딩이 아닙니다」라고 말하며, 사람이 생각하고 있는 것을 그대로 시각화하는 기술은 아니라고 강조.
그리고 타카기 조교는 "뇌의 정보를 충분히 해독하는 기술이 곧 실용화되는 것은 실현되기 어렵습니다. 이번 논문에서 다룬 것과 같은 디코딩 모델을 구축하기 위해서는 대형 fMRI 스캐너에 사람이 몇 시간이고 들어가 있어야 합니다. 디코딩 모델의 정확도도 아직 더 향상되어야 합니다. 뇌 활동을 해독하면 윤리와 프라이버시와 관련된 심각한 문제를 일으킬 수 있습니다. 우리는 뇌가 매우 민감한 개인 정보라고 생각하고 있으며, 사전 동의 없이 어떠한 형태의 뇌 활동 분석도 수행해서는 안 된다고 생각하고 있습니다."라고 코멘트.
'AI · 인공지능 > 이미지 생성 AI' 카테고리의 다른 글
| Stable Diffusion 설치없이 브라우저에서 동작 가능한「Web Stable Difusion」등장 (0) | 2023.03.18 |
|---|---|
| 「Blender + ControlNet」을 사용하여 애니메이션을 만드는 방법 (3) | 2023.03.18 |
| 「Midjourney V5」등장, 취약했던 '손'도 깨끗하고 실사와의 구별은 거의 불가능 (0) | 2023.03.17 |
| 채팅으로 이미지 생성이 가능한「Visual ChatGPT」를 Microsoft가 개발 (0) | 2023.03.16 |
| 「Stable Diffusion」을 활용하여 RPG게임 배경 제작 (0) | 2023.03.06 |
| Stable Diffusion 개발사가 3D 애니메이션 생성 AI「Stability For Blender」를 발표 (0) | 2023.03.06 |
| 「Stable Diffusion」에서 단 1장의 이미지로부터「~ 같은 ○○」를 불과 수십초만에 생성하는 방법 (0) | 2023.03.02 |
| 직접 그린 그림과 같은 구도로 이미지를 생성하는「Scribble Diffusion」이 등장 (1) | 2023.03.02 |



