오픈 소스로 상용 이용도 가능한 대규모 언어 모델 「Falcon」이 등장, 오픈 소스 모델 중 최고의 성능

아랍 에미리트 연방의 수도 아부다비에 본사를 둔 연구 기관 "Technology Innovation Institute"가 오픈 소스 대규모 언어 모델 "Falcon"을 발표하고 기계 학습 관련 데이터 공유 사이트 "Hugging Face"에서 모델을 공개했습니다.
Falcon LLM - Home
https://falconllm.tii.ae/
Falcon LLM
Falcon LLM, a foundational large language model (LLM) with 40 billion parameters
falconllm.tii.ae
The Falcon has landed in the Hugging Face ecosystem
https://huggingface.co/blog/falcon
The Falcon has landed in the Hugging Face ecosystem
The Falcon has landed in the Hugging Face ecosystem Introduction Falcon is a new family of state-of-the-art language models created by the Technology Innovation Institute in Abu Dhabi, and released under the Apache 2.0 license. Notably, Falcon-40B is the f
huggingface.co
tiiuae/falcon-40b · Hugging Face
https://huggingface.co/tiiuae/falcon-40b
tiiuae/falcon-40b · Hugging Face
🚀 Falcon-40B Falcon-40B is a 40B parameters causal decoder-only model built by TII and trained on 1,000B tokens of RefinedWeb enhanced with curated corpora. It is made available under the Apache 2.0 license. Paper coming soon 😊. Why use Falcon-40B? I
huggingface.co
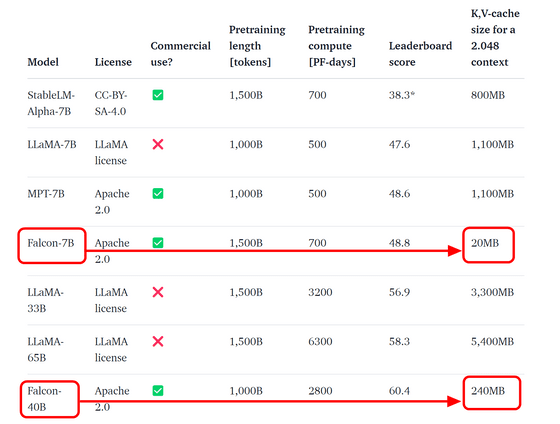
Falcon 모델은 400 억 개의 매개 변수를 가진 "Falcon-40B"모델과 70 억 개의 매개 변수를 가진 "Falcon-7B"모델의 두 가지가 출시되었습니다. 파라미터 수가 많은 40B 모델이 더 고성능이지만, 이를 동작시키기 위해서는 GPU 메모리도 90GB나 필요하고, 일반 사용자에게는 접근이 쉽지 않습니다. 한편, 7B 모델은 GPU 메모리가 15GB만 있으면 동작한다는 것.
주의점으로서, 이번에 릴리즈 된 40B 모델과 7B 모델은 사전 학습을 마친 단계이며, 제품으로서 이용하기 전에 파인 튜닝을 실시할 필요가 있다고 합니다. "실제로 성능을 시험해보고 싶지만 파인 튜닝은 좀 어려운데...'라고 생각할지도 모르겠습니다만, 그런 사람들을 위해서 실험적으로 채팅 형식의 데이터로 파인 튜닝한 「Falcon-40B-Instruct」, 「Falcon-7B-Instruct」도 준비되어 있습니다.
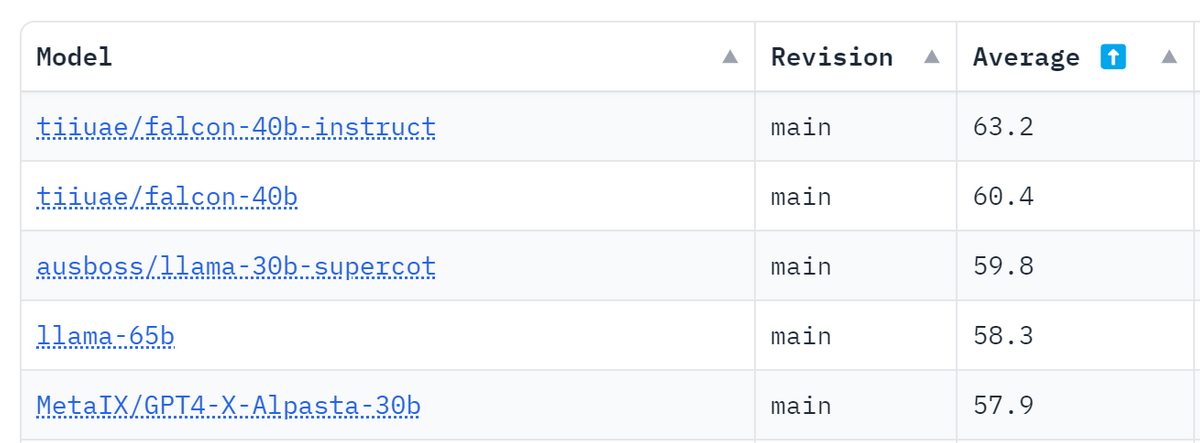
Hugging Face에는 오픈 소스 대규모 언어 모델끼리 스코어를 겨루는 「Open LLM Leaderboard」라는 랭킹이 준비되어 있어, 한눈에 어느 모델이 얼마나 뛰어난지를 확인할 수 있습니다만, 이번에 등장한 Falcon의 40B모델은 LLaMa계의 모델을 제치고 1위로 뛰어올랐습니다. 7B모델도 같은 모델 중에서 최고의 성능을 보여주고 있습니다.
Falcon의 품질이 높은 이유는 트레이닝에 사용한 데이터에 있습니다. 웹에서 수집한 대규모 데이터세트인 RefinedWeb을 기반으로 중복 제거 및 필터링을 통해 다른 코퍼스(구조화된 텍스트 묶음)와 유사한 품질까지 높였다고 합니다. 이 중복 제거 및 필터링된 데이터도 Hugging Face에 공개되어 있어, 누구나 자신의 언어 모델을 교육하는 데 사용할 수 있습니다.
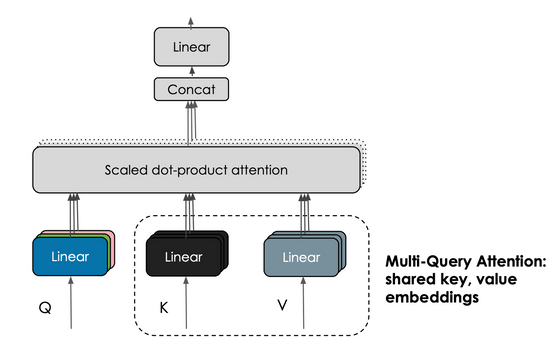
또한, Falcon의 또 다른 특징으로서 「멀티-쿼리 어텐션」을 들 수 있습니다. 기존의 트랜스포머 구조의 멀티 헤드 부분에서는 헤드마다 쿼리 키 값을 보존하고 있었지만, 멀티-쿼리 어텐션에서는 모든 헤드에 대해 쿼리 키 값을 공유하고 있습니다.
멀티-퀘리 어텐션을 채용하는 것으로 키와 밸류값의 캐시량을 최대 100분의 1까지 삭감할 수 있어, 동작에 필요한 메모리 양을 억제하는 것이 가능하다는 것.
Hugging Face는 실제로 Falcon-40B를 시도할 수 있는 페이지를 제공합니다. 아래는 간단한 채팅 테스트.
마침 이름이 Falcon 이니까,
데이비드 보위(영국 가수입니다)의 Falcon을 혹시 아냐고 물어봤더니, 자기가 그 Falcon이라고 ㅋㅋㅋ
이거 좀 웃겼음요 ㅋㅋㅋ
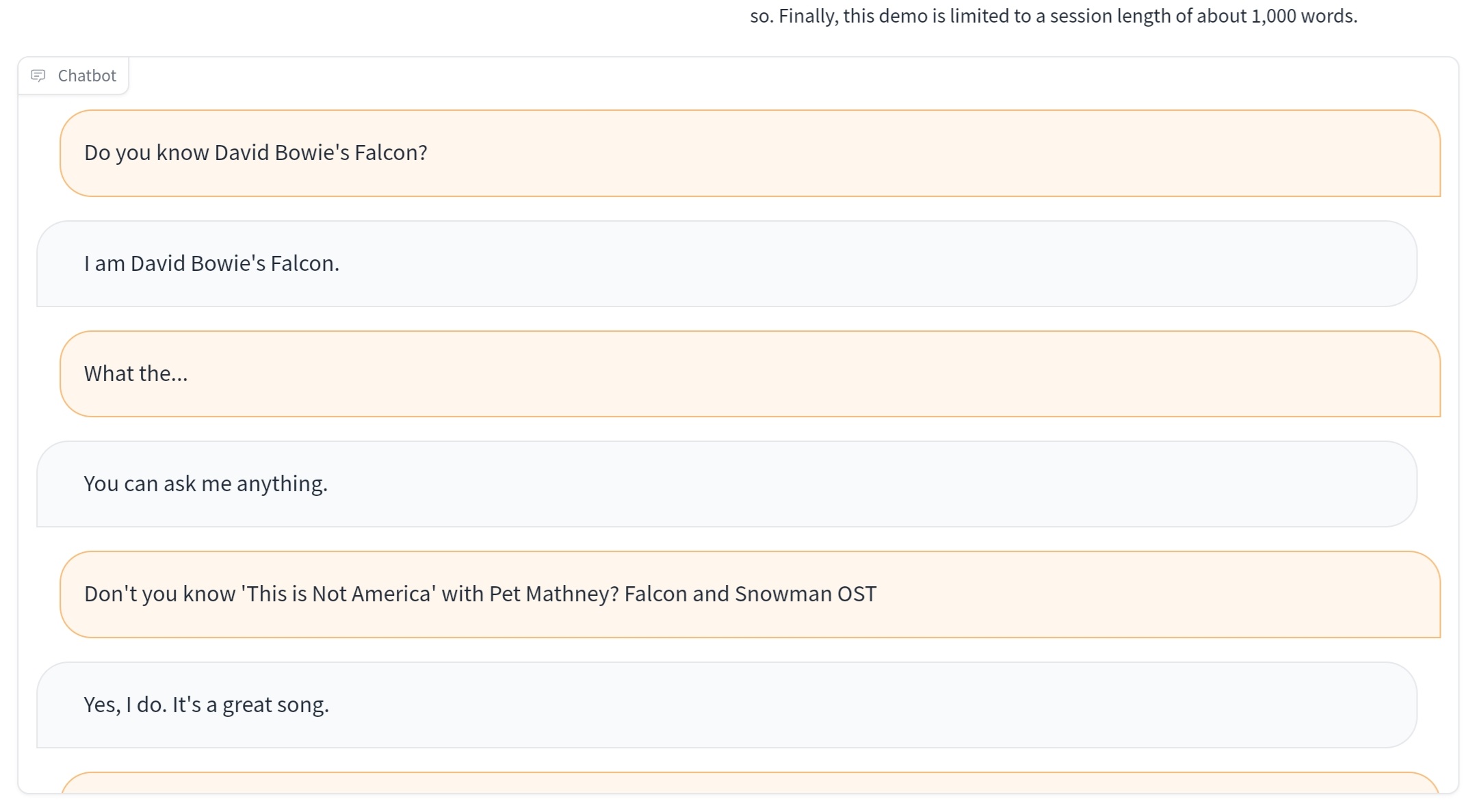
단답형 대답을 시전 하길래,
살짝 킹 받아서, "진짜 그 곡을 아는 게 맞냐? 가사 좀 알려줘 봐라"라고 부탁하니...
인터넷 연결이 안 돼서 못 찾겠다는 Falcon 녀석 ㅋㅋㅋ
너도 쉽게 찾을 수 있으니, 직접 찾아보랍니다. ㅋㅋㅋ

그래 내가 직접 찾을게...
