AI가 1장의 사진으로부터 고해상도 3DCG 모델을 생성해주는「Human-SGD」

사진에서 3DCG 모델을 만들려면 피사체를 여러 방향에서 다수 촬영해야 합니다. 쿠웨이트 대학, Meta, 메릴랜드 대학의 연구원이 단 한 장의 사진에서 고해상도 CG 모델을 생성하는 "Human-SGD"를 발표했습니다.
[2311.09221] Single-Image 3D Human Digitization with Shape-Guided Diffusion
https://arxiv.org/abs/2311.09221
Single-Image 3D Human Digitization with Shape-Guided Diffusion
We present an approach to generate a 360-degree view of a person with a consistent, high-resolution appearance from a single input image. NeRF and its variants typically require videos or images from different viewpoints. Most existing approaches taking mo
arxiv.org
Human-SGD
https://human-sgd.github.io/
Human-SGD
To generate a 360-degree view of a person from a single image, we first synthesize multi-view images of the person. We use off-the-shelf methods to infer the 3D geometry and synthesize an initial back-view of the person as a guidance. We add our input view
human-sgd.github.io
연구팀의 한 명인 Jia-Bin Huang 씨가 Human-SGD가 어떤 모델인지 설명하는 영상을 YouTube에 공개했습니다.
3D Human Digitization from a Single Image! - YouTube
라이더 재킷을 입은 여성의 사진이 1장.

이 사진으로부터 생성한 3DCG 모델이 이하. 사진은 정면에서 촬영한 것만입니다만, 360도의 어디에서 봐도 망가진 곳 없이 고정밀도의 3DCG 모델이 되고 있습니다.

폴로셔츠와 반바지 차림의 걷는 남자 사진

텍스처뿐만 아니라, 반바지의 옷자락이나 바지에서 삐져나온 폴로셔츠의 옷자락 등 세세한 형상도 재현되고 있습니다.

Human-SGD는 입력한 사진에서 모양과 텍스처를 생성하고 결합합니다.

생성하는 프로세스는 다음과 같습니다. Human-SGD는 사진의 실루엣에서 모양을 렌더링 하고 정면 사진에서 후면 사진을 자동으로 생성, 결합하여 렌더링 합니다.
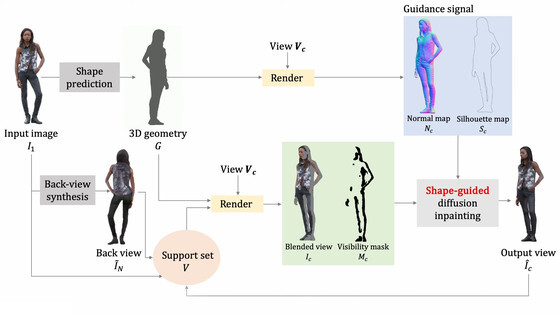
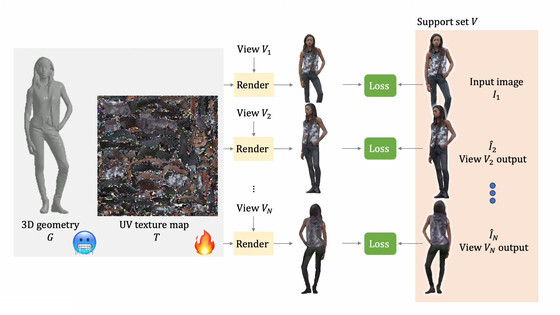
텍스처는 확산 모델로 생성되어 「미분 가능 렌더링」이라고 불리는 기술로 UV 매핑(2차원 그림을 3차원 모델로 만드는 3차원 모델링 프로세스)이 최적화된다고 합니다.
비교용으로 제시된 것이 아래의 사진.

2019년에 발표된 PIFu로 생성한 CG모델은 이런 느낌. 정면에서 보면 사진에 가깝지만, 옆에서 보면 정밀도가 떨어지고 얼굴 부분은 해상도도 낮다는 것을 알 수 있습니다.

2023년에 발표된 TEXTure는 텍스처의 해상도가 PIFu보다 높아졌습니다만, 바로 옆에서 보면 세세한 부분에서 노이즈가 매우 많습니다.

Magic-123은 모양이 지나치게 매끄럽게 되는 것으로 약간 인간을 벗어난 형상이 되고 있고, 텍스처도 무리하게 사진을 잘라 붙인 것 같은 인상.
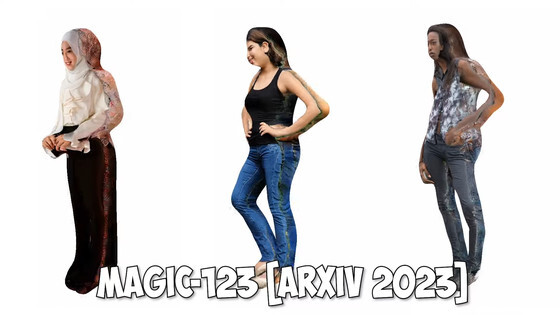
TeCH는 모양이 세세하게 묘사되고 있습니다만, 포즈가 앞으로 기울어지거나 가랑이가 어색하여 정밀도는 낮습니다. 텍스처도 노이즈가 많은 것처럼 보입니다.

HUMAN-SGD로 생성한 모델은 모양도 비교적 자연스럽고, 노이즈가 적은 텍스처가 무리 없이 구현되고 있습니다.

사진에 찍히지 않은 뒷면도 자연스럽고 붕괴가 적다는 인상.

다만, 연구팀에 의하면, 음영이 강한 사진은 텍스처의 생성에 지장을 초래하며, 기존의 방법에서는 보다 정밀하게 모양을 생성하는 것이 어렵기 때문에 추가 연구가 필요하다고 합니다.
