간단한 텍스트로부터 사실적인 동영상을 생성하는 확산 모델 「W.A.L.T」가 등장

스탠퍼드 대학과 Google 연구팀이 텍스트로 사실적인 동영상을 생성하는 확산 모델인 「W.A.L.T」를 발표했습니다. 실제로 「W.A.L.T」를 사용하여 생성한 동영상도 다수 공개되어 있습니다.
WALT(pdf 다운로드)
https://walt-video-diffusion.github.io/assets/WALT.pdf

Photorealistic Video Generation with Diffusion Models
https://walt-video-diffusion.github.io/
Photorealistic Video Generation with Diffusion Models
We present W.A.L.T, a transformer-based approach for photorealistic video generation via diffusion modeling. Our approach has two key design decisions. First, we use a causal encoder to jointly compress images and videos within a unified latent space, enab
walt-video-diffusion.github.io
「WALT」는, Google 등이 발표한 심층 학습 모델인 Transformer를 베이스로 한 동영상 생성 AI입니다. 연구팀의 아그림 굽타 씨는, WALT의 구조를 X(구 Twitter)에 포스팅하고 있습니다.

WALT는 먼저 Joint Casual 3D 인코더를 사용하여 공유 잠재 공간의 이미지 및 동영상을 압축합니다.

다음으로 기억 및 트레이닝의 효율을 높이기 위해, 잠재 공간에서의 공간적 · 시간적 공동 생성 모델링용으로 조정된 윈도 · 어텐션 · 아키텍처를 사용한다는 것.
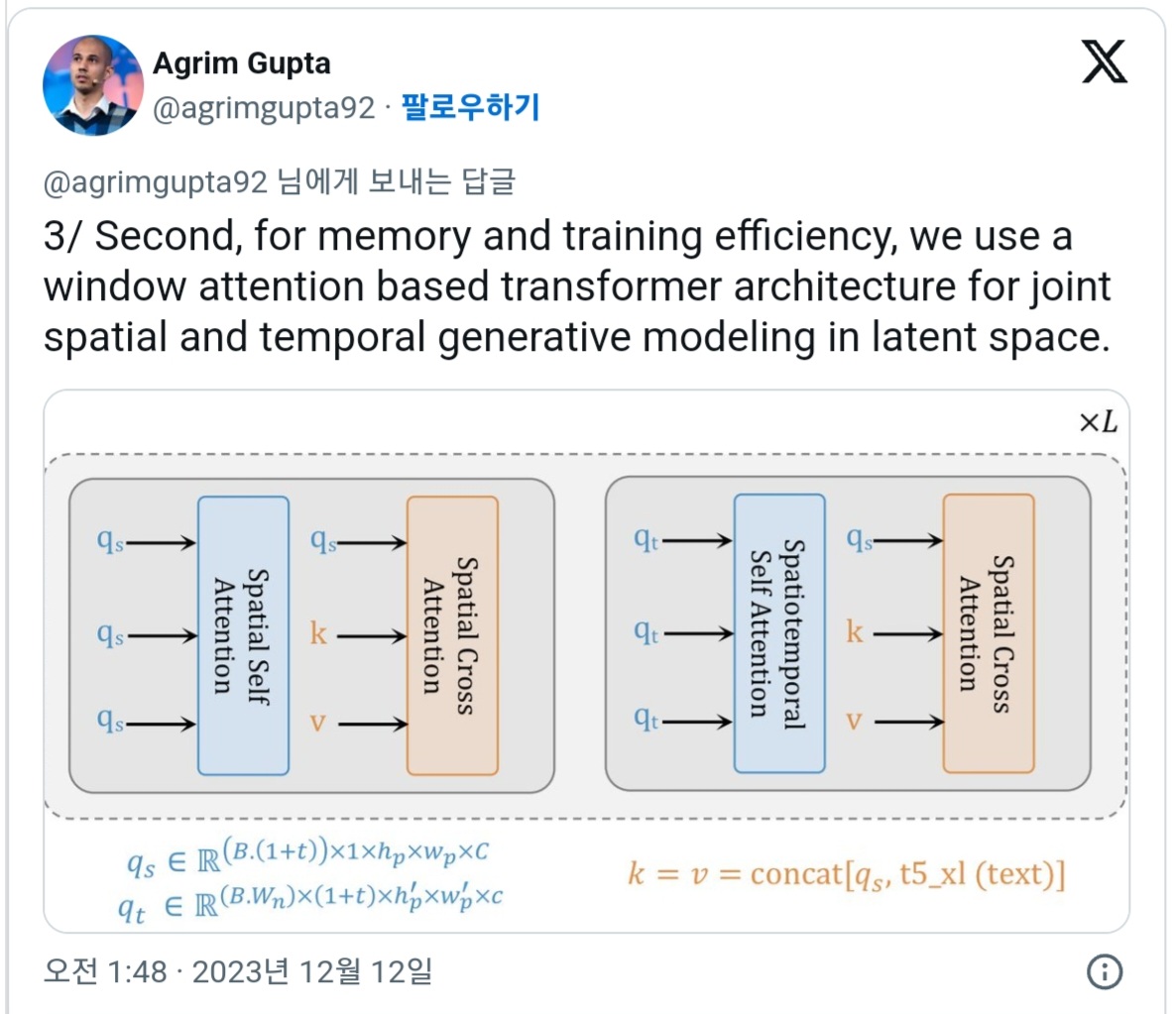
이를 통해 자연어 프롬프트로부터 사실적이고, 시간적으로 일관된 모션을 생성할 수 있습니다.

실제로 연구팀은 WALT를 사용하여 생성한 동영상을 다수 공개하고 있습니다.
https://walt-video-diffusion.github.io/samples.html