중국의 Tencent가 NVIDIA에 의존하지 않고 자사제 AI 인프라 학습 능력을 20% 강화
기업과 연구 기관이 사용하는 대규모 AI 인프라에는 대량의 연산 칩이 탑재되어 있어, 방대한 데이터를 병렬 처리할 수 있도록 구성되어 있습니다.
이번에 새롭게 중국의 주요 IT 기업인 Tencent가 AI 인프라 네트워크 처리를 개선하고 AI 학습 성능을 20% 향상시키는 데 성공했다고 발표했습니다.
Tencent boosts AI training efficiency without Nvidia’s most advanced chips | South China Morning Post
Tencent boosts AI training efficiency without Nvidia’s most advanced chips
Tencent said its focus on speeding up network communications to access idling GPU capacity resulted in a 20 per cent improvement in LLM training.
www.scmp.com
Tencent에 따르면 AI 인프라와 같은 대규모 HPC 클러스터의 전체 처리 시간 중, 데이터 통신 시간이 최대 50%를 차지한다고 합니다. 네트워크 처리 성능을 향상시켜 데이터 통신 시간을 단축하면 GPU 대기 시간이 줄어, 전체적인 처리 능력을 향상시킬 수 있습니다. 이러한 이유로 Tencent는 자체 AI 인프라의 네트워크 처리 성능을 향상시키기 위해 노력했습니다.
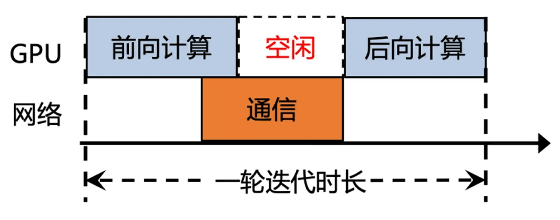
Tencent는 2024년 7월 1일에 새로운 네트워크 처리 시스템인 Xingmai 2.0을 발표했습니다. Xingmai 2.0을 채용한 AI 인프라에서는 기존과 비교하여 통신 효율이 60%, AI 모델의 학습 효율이 20% 향상된다는 것. Tencent의 테스트는 대규모 AI 모델의 학습 시간을 50초에서 40초로 단축할 수 있었다고 합니다.

Xingmai 2.0에는 Tencent가 개발한 통신 프로토콜 「TiTa2.0」 이 채용되어 있어 데이터의 효율적인 배분이 가능합니다. 또한 TiTa2.0은 데이터의 병렬 전송에도 대응하고 있다는 것. 또한 Xingmai 2.0은 신개발 네트워크 스위치와 광통신 모듈을 채택, 대역폭이 확대되어 단일 클러스터에서 10만 대 이상의 GPU를 관리할 수 있습니다.
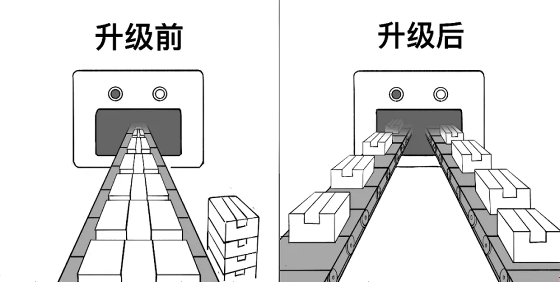
AI 계산 처리 분야에서는 미국 기업의 NVIDIA가 큰 존재감을 나타내고 있지만, 미국은 중국에 대한 고성능 반도체의 수출을 제한하고 있으며, 중국에 거점을 두는 기업이 NVIDIA제의 고성능 반도체를 얻는 것은 어렵습니다. 이 때문에 Tencent가 GPU의 증강이 아니라 네트워크 처리의 개선으로 AI 처리 성능을 향상할 수 있었던 것은 주목할 만한 부분입니다.
또한 South China Morning Post는 "AI 학습은 에너지를 대량으로 소비한다. AI 인프라의 처리 효율을 향상시키는 것은 에너지 비용 절감으로 이어지므로 가격 경쟁에서 매우 중요한 부분이다."라고 지적하고 있습니다.