1조의 텍스트 토큰, 34억개의 이미지, PDF, ArXiv의 논문 등을 포함한 오픈 소스 데이터 세트 MINT-1T

클라우드 컴퓨팅 서비스를 제공하는 Salesforce의 AI 연구 부문 Salesforce AI Research가 1조의 텍스트 토큰을 포함한 오픈 소스 멀티 모달 데이터 세트 ' MINT-1T '를 공개했습니다.
GitHub - mlfoundations/MINT-1T: MINT-1T: A one trillion token multimodal interleaved dataset.
https://github.com/mlfoundations/MINT-1T
GitHub - mlfoundations/MINT-1T: MINT-1T: A one trillion token multimodal interleaved dataset.
MINT-1T: A one trillion token multimodal interleaved dataset. - mlfoundations/MINT-1T
github.com
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
https://blog.salesforceairesearch.com/mint-1t/
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
We are excited to open-source 🍃MINT-1T, the first trillion token multimodal interleaved dataset and a valuable resource for the community to study and build large multimodal models.
blog.salesforceairesearch.com
AI 개발에는 엄청난 양의 텍스트와 이미지가 포함된 데이터세트가 필요하며, 고품질 데이터세트가 오픈소스로 공개되는 것은 AI 분야의 발전에 큰 이점이 됩니다.
MINT-1T 멀티 모달 데이터 세트는 1조의 텍스트 토큰이나 34억 장의 이미지가 포함되어 있다는 것 외에 PDF나 프리프린트 서버인 ArXiv의 논문 등, 지금까지의 데이터 세트에는 활용되지 않았던 데이터도 포함되어 있습니다.
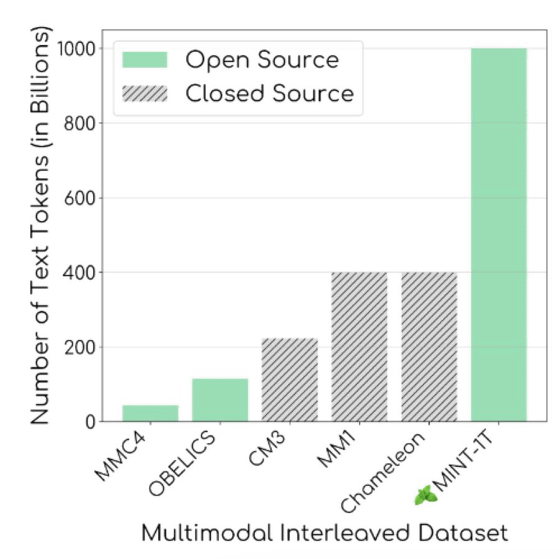
아래 그림에서 알 수 있듯이 OBELICS 및 MMC4와 같은 기존 오픈 소스 데이터 세트의 토큰 수는 최대 1150억이며, MINT-1T는 토큰 수가 크게 증가하고 있습니다.
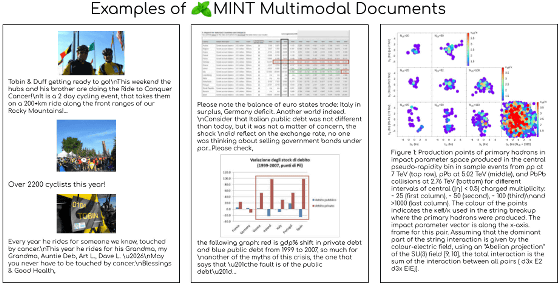
다음은 MINT-1T에 포함된 문서의 샘플입니다. 이미지와 함께 텍스트가 병기되어 있어 다양한 그래프나 히트 맵등도 포함되어 있습니다. MINT-1T 큐레이션의 주요 원칙은 규모와 다양성이라고 합니다.
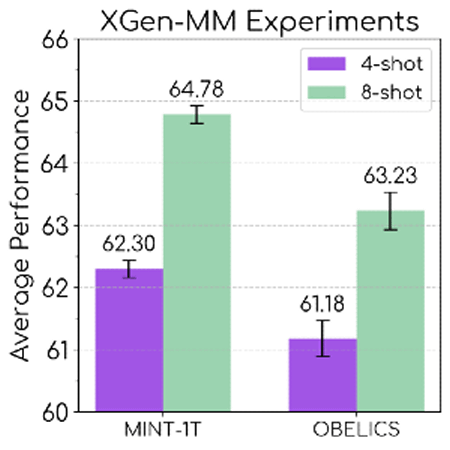
아래 그래프는 Salesforce AI Research가 개발한 AI 모델의 XGen-MM을 사용하여 MINT-1T에서 트레이닝한 경우(왼쪽)와 OBELICS에서 트레이닝한 경우(오른쪽)의 퍼포먼스를 비교한 결과입니다. MINT-1T로 훈련하는 것이 전반적인 성능을 향상하고 있음을 알 수 있습니다.