Meta가 대규모 언어 모델「LLaMA」를 발표, GPT-3에 필적하는 성능

Meta의 AI 연구 조직인 Meta AI Research가 대규모 언어 모델 LLAMA(Large Language Model Meta AI) 를 2023년 2월 24일에 발표했습니다. Meta AI Research에 따르면, LLaMA는 OpenAI의 GPT-3 보다 파라미터 수가 훨씬 적고, 단위 GPU에서도 동작할 수 있는 한편, 벤치마크 테스트의 일부에서는 GPT-3을 웃돌았다고 합니다.
LLaMA: Open and Efficient Foundation Language Models - Meta Research
LLaMA: Open and Efficient Foundation Language Models - Meta Research | Meta Research
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to...
research.facebook.com
Meta unveils a new large language model that can run on a single GPU [Updated] | Ars Technica
Meta unveils a new large language model that can run on a single GPU [Updated]
LLaMA-13B reportedly outperforms ChatGPT-like tech despite being 10x smaller.
arstechnica.com
LLaMA의 매개 변수 수는 70 억 ~ 650 억이며, Wikipedia 및 Common Crawl , C4등, 일반적으로 공개되고 있는 데이터 세트로 학습하고 있다는 것. Meta AI Research의 연구원인 Guillaume Lample 씨는 "GPT-3 및 DeepMind의 Chinchilla , Google의 Palm 과 달리 LLAMA는 공개된 데이터 세트만 사용하며 오픈 소스와 호환되는 재현 가능한 작업을 수행합니다. 기존 모델의 대부분은 공개되지 않거나 문서화되지 않은 데이터를 사용하여 학습합니다."라고 코멘트.
또한 Meta AI Research에 따르면 파라미터 수 130억의 LLAMA-13B를 단독 GPU로 실행하여 BoolQ, PIQA, SIQA , HellaSwag , WinoGrande , ARC , OpenBookQA 라는 8 개의 벤치마크로 '상식적 추론'을 측정한 바, 일부 테마에서는 파라미터 수 1,750억의 GPT-3를 웃도는 성능을 나타냈다는 것.
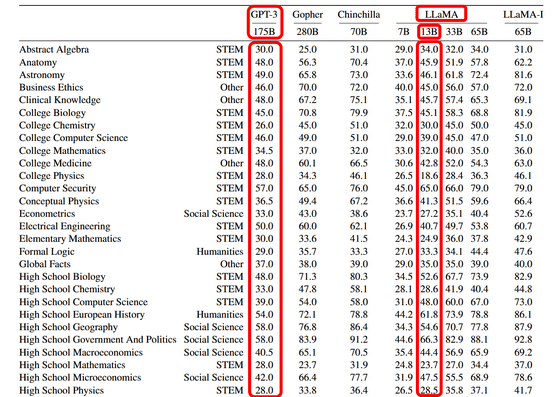
파라미터 수는 기계 학습 모델이 입력 데이터를 기반으로 예측 및 분류를 수행하는 데 사용하는 변수(매개 변수)의 양으로, 모델의 성능을 좌우하는 중요한 요소입니다. 파라미터 수가 클수록 더 복잡한 작업을 처리하여 안정적인 출력을 생성할 수 있지만, 파라미터 수가 많을수록 모델 자체의 크기도 커지고 동시에 필요한 컴퓨터의 리소스도 많아집니다.
"GPT-3보다 압도적으로 적은 파라미터 수로 GPT-3와 동등한 성능을 나타냈다"라는 LLAMA-13B는 GPT-3보다 비용 성능이 우수하다고 할 수 있습니다. 또한 GPT-3는 AI에 최적화된 가속기를 여러 대 사용하지 않으면 동작하지 않는 반면 LLAMA-13B는 단독 GPU에서도 문제없이 동작했기 때문에 소비자 수준의 하드웨어 환경에서도 ChatGPT와 같은 AI를 구동할 수 있습니다.
Meta AI Research는 LLaMA를 '기본 모델'로 간주하고 향후 이 LLaMA가 Meta의 자연 언어 처리 모델의 기반이 되어, '질문 응답, 자연 언어의 이해 또는 독해, 현재의 언어 모델의 능력과 한계의 이해'와 같은 자연 언어를 연구하는 데 도움이 되어, 응용 프로그램을 잠재적으로 강화할 것으로 기대하고 있습니다.
덧붙여, 현시점에서 LLaMA의 일반 공개는 예정되어 있지 않지만, LLaMA에 의한 간략한 추론 모델의 일부가 GitHub에 공개되어 있으며, 완전한 코드와 신경망으로 학습시킨 가중치는 Google 폼을 통해 Meta AI Research에 연락하면 다운로드도 가능하다고 합니다.
GitHub - facebookresearch/llama: Inference code for LLaMA models
https://github.com/facebookresearch/llama