OpenAI가 개발한 ChatGPT를 비롯하여 다양한 AI가 인간 수준의 대화를 하게 되었습니다. 이러한 채팅 AI가 어떤 기술로 이루어져 있는지 AssemblyAI의 엔지니어인 매크로 람포니 씨가 최대한 쉽게 해설하고 있습니다.
The Full Story of Large Language Models and RLHF
The Full Story of Large Language Models and RLHF
Large Language Models have been in the limelight since the release of ChatGPT, with new models being announced seemingly every week. This guide walks through the essential ideas of how these models came to be.
www.assemblyai.com
ChatGPT 출시 이후, 사용자 1억 명을 찍기까지 걸린 기간은 고작 2개월로, 터무니없는 속도로 보급되어 갔습니다.
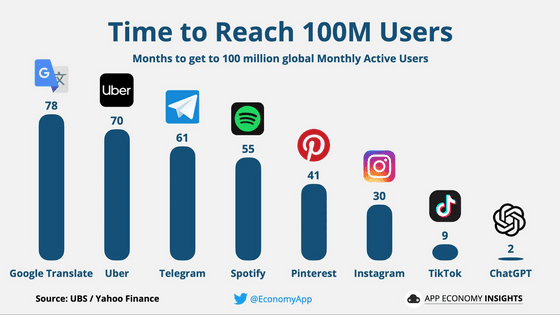
ChatGPT의 히트 이후 다양한 채팅 AI가 등장하고 있지만, 이 채팅 AI는 '언어 모델'이라는 기술로 탄생했습니다. 언어 모델이란 특정 문장에 대해 특정 문자가 이어질 확률을 계산하는 모델입니다. 예를 들어, "The color of the sky is(하늘 색은)"이라는 문장에 대해 "blue(파란색)"이라는 단어가 이어질 확률은 계산이 가능합니다.
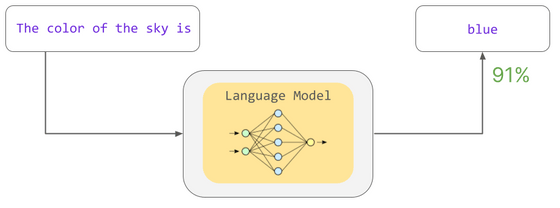
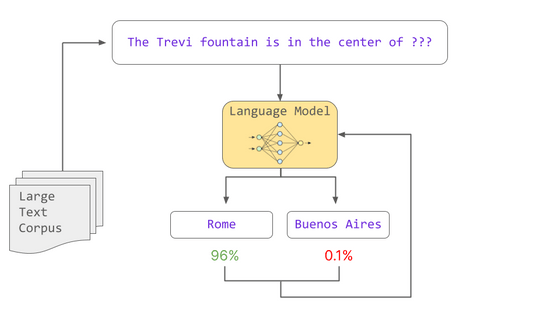
이러한 확률은 교육 도중 학습한 통계 패턴을 기반으로 합니다. 모델 트레이닝은 문장에서 '누락된 단어는 무엇인가'라는 확률 계산을 통해 언어 모델이 문법과 단어 관계 등 다양한 언어의 패턴을 학습하도록 합니다. 이렇게 학습한 모델을 「사전 학습이 끝난 모델」이라고 부릅니다.
사전 학습만으로도 어느 정도의 출력은 할 수 있습니다만, 사용 용도에 따른 적절한 데이터로 추가 학습을 실시하는 파인 튜닝을 실시하면 다양한 태스크를 높은 정밀도로 실행하는 것이 가능하게 됩니다.
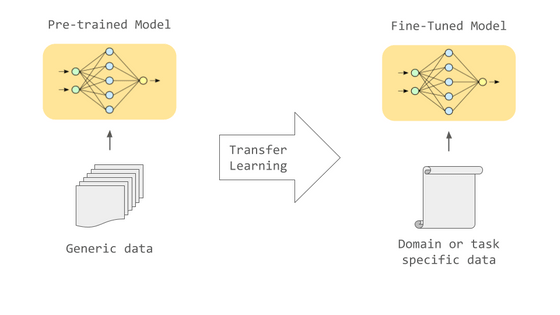
예를 들어 기계 번역을 하고 싶을 경우, 2개의 언어 대역의 데이터를 사용해 파인 튜닝하는 것으로, 텍스트를 효과적으로 번역할 수 있게 됩니다. 또, 의료 분야나 법률 분야 등 특정 분야의 데이터를 이용해 파인 튜닝하면 그 분야 고유의 단어 사용이나 구문을 잘 처리하는 것이 가능하게 됩니다.
이러한 언어 모델의 성능은 언어 모델을 구성하는 신경망의 크기에 크게 영향을 받습니다. 신경망은 인간의 뇌 구조가 바탕이 되어 다수의 뉴런이 접속된 구조로 되어 있습니다. 각각의 뉴런 사이의 접속 강도는 「파라미터」로 나타나고 있어, 보다 파라미터의 수치가 높을수록 뉴런의 결합이 강해, 이전 뉴런에 입력된 신호가 다음 뉴런으로 확실히 전해지는 구조입니다.
이러한 뉴런 간의 연결 수인 파라미터 수가 많을수록 다양한 통계 패턴을 내부에 유지할 수 있어, 언어 모델의 성능이 높아지는 경향이 있다는 것이 판명되었습니다. 반면에 파라미터 수에 따라 교육에 필요한 데이터 수와 시간이 증가합니다. 이 파라미터 수가 1억을 넘는 거대 모델을 대규모 언어 모델이라고 합니다.

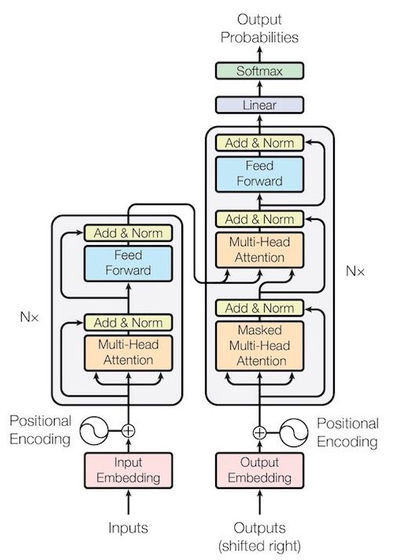
언어 모델은 신경망이 기본이지만 단순한 신경망은 아닙니다. 2023년 6월 시점에서 활약하고 있는 언어 모델은 모두 2017년에 등장한 "Transformer"라는 구조를 가진 신경망을 이용하고 있습니다. 자연 언어 처리 분야에서 태어난 Transformer는 대량의 데이터를 병렬로 처리할 수 있는 효율성으로 AI 분야에 혁명을 일으켰습니다. 효율적으로 데이터를 처리할 수 있게 되었기 때문에, 보다 대규모의 데이터 세트로 대규모 언어 모델을 트레이닝할 수 있게 되었다는 것입니다. 또한, 텍스트 데이터상에 있어서는 독보적인 문맥 이해 능력을 보이고 있어, 거의 모든 자연언어 처리 태스크의 표준적인 선택지가 되었습니다.
Transformer의 문맥 이해 능력은 주로 「단어 임베딩(word embedding)」과 「어텐션(Attention)」이라는 2개의 요소에 의해 성립되고 있습니다. 「단어 임베딩」은 단어를 의미 · 구문적 특성을 바탕으로 벡터화하여 취급하는 것으로, 언어 모델에 특정 문맥과 단어와의 관계를 이해하는 능력을 부여합니다. 한편 「어텐션」은 문장 내의 단어 각각에 대해 어텐션 스코어를 계산하는 구조로, 언어 모델은 어텐션의 구조를 통해 "입력된 태스크를 해내려면 어느 단어를 중시해야 하는가"를 비교 검토할 수 있게 되었습니다.
Transformer 기반 언어 모델은 인코더와 디코더의 구조를 활용하여 문장을 처리합니다. 인코더는 문장을 기하학적/통계적으로 의미 있는 수치로 인코딩할 수 있으며, 디코더는 그 수치를 바탕으로 문장을 생성할 수 있습니다. 작업에 따라 인코더와 디코더 중 하나만 사용할 수 있습니다. 예를 들어, GPT 모델은 디코더만을 채택하고 새로운 문장을 생성하는 작업에 특화되어 있습니다.
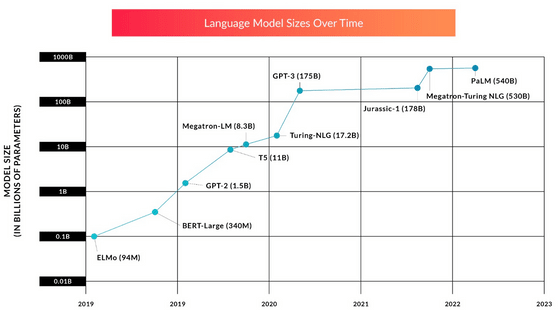
Transformer의 출현 이후 대규모 언어 모델의 개발은 모델의 파라미터 수를 늘리는 방법에 중점을 뒀습니다. 최초의 GPT 모델이나 ELMo 모델은 수백만에서 수천만 파라미터였지만, 곧바로 수억 파라미터를 가지는 BERT나 GPT-2가 등장해, 2022년경에는 수천 억의 파라미터수를 자랑하는 대규모 언어 모델이 등장하고 있습니다. 모델이 대규모화됨에 따라 교육에 필요한 데이터의 양과 시간도 증가하고 있으며, 자세한 금액은 공개되지 않았지만 사전 학습만으로도 수백억 원이 든다는 견적이 나옵니다. 게다가 대규모 언어 모델의 대부분은 트레이닝이 불충분하다고 판명되고 있어, 현재의 페이스로 모델의 확대가 계속된다면, 모델 사이즈가 아닌 트레이닝 데이터의 부족이 AI 성능 향상의 병목으로 작용할 가능성이 있습니다.
파라미터 수가 늘어나면 단순히 응답 성능이 올라갈 뿐만 아니라 대규모 언어 모델이 완전히 새로운 기능을 획득한다는 것도 밝혀졌습니다. 일정 파라미터 수를 초과하면 대규모 언어 모델은 교육 중, 자연어 패턴을 반복적으로 관찰하는 것만으로 다른 언어 간의 번역 및 코드 작성 능력을 비롯한 다양한 작업을 수행할 수 있습니다. 기존에는 적절한 데이터로 파인 튜닝하지 않으면 실행할 수 없었던 명령을 파라미터 수만 늘렸다고 갑자기 실행 가능하게 된다는 것은 경이로운 부분입니다.
그러나 언어 모델의 기술은 좋은 것만 가져온 것은 아닙니다. 언어 모델의 코딩 능력이 악성코드 생성에 이용된다거나, AI 생성 콘텐츠를 이용하여 SNS상에서 광고 선전을 한다거나, 훈련 중에 입력된 프라이버시를 침해하는 데이터를 응답에 포함시켜 버린다거나, 정신적 지원을 요청하는 채팅에 유해한 답변을 하는 등의 위험이 있습니다.
언어 모델에 대한 우려점은 다수 존재하고 있지만, 언어 모델의 작성에 있어서는 아래의 셋을 목표로 하는 것이 원칙이라고 말해지고 있습니다.
・유용성
필요에 따라 사용자의 의도를 명확히 하기 위한 질문을 하면서 지시에 따라 태스크를 실행하는 능력.
・진실성
사실에 기초한 정확한 정보를 제공하고 언어 모델 자체의 불확실성과 한계를 인식하는 능력.
・무해성
편견이 있거나 악(독)이 들어가거나, 불쾌하거나 하는 반응을 피하고, 또 위험한 활동에의 지원을 거부하는 능력.
이 3가지를 달성하는 데 있어서, 2023년 6월 시점에 가장 적합하다고 여겨지고 있는 것이
「인간의 피드백에 의한 강화 학습(RLHF : Reinforcement Learning with Human Feedback)」입니다.
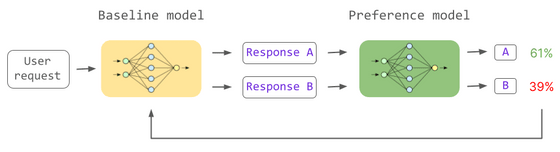
RLHF에는 아래의 왼쪽에 있는 일반 언어 모델과 오른쪽에 녹색으로 표시되는 두 개의 입력을 받아 "인간이 어떤 답변을 선호하는가?"를 결정하는 모델이 등장합니다. 일반 언어 모델이 '더 많은 사람이 선호하는 답변'을 학습하게 되면 태스크에 대한 답변의 품질이 향상됩니다.
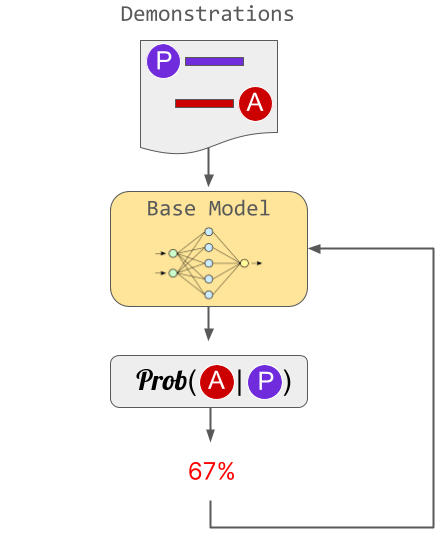
ChatGPT에서는 3단계로 나누어 RLHF가 진행되었습니다. 첫 번째 단계에서는 인간의 견본을 '이상적인 답변'으로 모델을 교육했습니다. 이 접근법은 인간이 견본을 작성해야 하기 때문에 업스케일링하기가 어렵다는 문제가 있습니다.
두 번째 단계에서는 인간이 언어 모델로 생성한 여러 대답의 우열을 가리고, 대답과 투표 결과를 보상 모델에게 학습시킵니다. 이렇게 보상 모델은 "어떤 응답이 인간 취향인지"를 판단하는 능력을 익혔습니다.
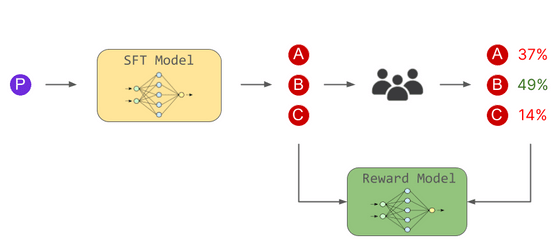
그리고 세 번째 단계에서는 보상 모델을 기반으로 언어 모델이 인간 선호 답변을 출력하도록 훈련합니다. 이 2단계와 3단계는 복수회에 걸쳐 여러 번 행해졌습니다.
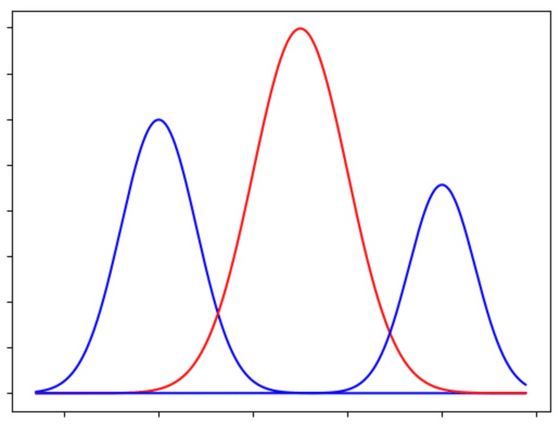
RLHF를 수행하지 않으면 인터넷의 옥석이 가려지지 않은 혼잡한 문장들 속에서 답변이 생성됩니다. 그러면 옥석의 분포 범위가 너무 넓어 응답이 안정되지 않을 가능성이 존재한다는 것입니다. 예를 들면 정치가에 대해 질문했을 경우, Wikipedia를 기초로 한 중립적인 회답을 할 가능성도 있지만, 게시판등이 과격해진 시점을 바탕으로 극단적 발언을 해 버릴 가능성도 있다는 것입니다.
RLHF에서는 인간의 시점을 주입함으로써 모델에 바이어스(편향)를 주어 생성 범위를 좁히고 있다고 생각할 수 있습니다. 대답의 다양성과 안정성과 일관성은 절충 관계에 있으며, 하나만 획득할 수 없습니다. 물론 검색엔진 등의 정확하고 신뢰성이 요구되는 분야에서는 일관되게 안정된 응답이 바람직하기 때문에 RLHF를 실시해야 합니다만, 창조적인 작업의 헬퍼 용도로 RLHF를 사용한다면 다양성을 기본으로 한 새롭고 흥미로운 개념의 탐구를 오히려 방해받을 수도 있다는 것입니다.
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| ChatGPT 등 수많은 고성능 AI를 낳은 구조 「Attention」 에 대한 상세한 해설 영상 (67) | 2024.04.17 |
|---|---|
| OpenAI의 Sora에 사용된 기술 간단 리뷰 (54) | 2024.04.14 |
| 문과도 도전? 비즈니스 관점에서 본 프롬프트 엔지니어링 요약 (2) | 2023.08.01 |
| ChatGPT를 사용하여 10년 만에 백만장자가 되는 공식, 「기업가로서의 청사진」 (6) | 2023.06.14 |
| Meta의 세분화 모델 Segment Anything Model(SAM) 논문 간단 리뷰 (0) | 2023.04.07 |
| GPT-4 총평 : 성능, 응용 사례, 안전 대책 및 리스크를 전망 (0) | 2023.03.24 |
| ChatGPT와 Stable Diffusion을 낳은「기계 학습 소프트웨어」의 10년간의 흐름을 전문가가 해설 (0) | 2023.01.18 |
| 이미지 생성 AI는 크리에이터 이코노미를 증강할 것인가, 아니면 파멸시킬 것인가? (0) | 2023.01.11 |



