
3개의 요점
✔️ 정지 이미지 속 인물의 3차원 모션을 복원
✔️ 온라인 상에 존재하는 대량의 라벨 없는 데이터를 사용하여 비 지도 학습을 실시
✔️ 3DPW라는 데이터셋을 사용하여 실험을 하여 state of the art를 획득
최근 사람의 동작을 3차원으로 복원하는 작업이 다양한 산업 분야에서 이뤄지고 있습니다. 예를 들어 스포츠 업계에서는 선수의 폼 체크나 경기의 리플레이 영상 등에 이미 도입되어 있습니다. 그러나 사람의 동작을 3차원으로 복원하기 위해서는 다양한 장비와 우수한 엔지니어가 필요하며, 많은 비용이 들기 때문에 '손쉽게 할 수 없다'라는 과제를 안고 있습니다. 이번에는 이 과제를 해결할 가능성을 지닌 연구를 소개하고 싶습니다.
이번 연구의 목적은 한마디로 표현하면 '스틸 이미지 속 인물의 3차원 모션을 복원하는 것'입니다. 구체적으로는 그림 1과 같이 비디오 중 어느 시점 프레임에서 과거, 현재, 미래의 일련의 동작을 복원합니다. 저자는 이 도전적인 목표를 달성하기 위해 ResNet을 바탕으로 한 모델을 구축하고 제안했습니다.

또한, 이렇게 이미지와 비디오를 데이터셋으로 사용하는 연구는 종종 '라벨 데이터셋의 부족'이라는 문제가 자주 발생합니다. 특히 이번에 사용할 데이터셋은 비디오의 프레임 한 장 한 장마다 3차원 자세와 형상에 대한 라벨을 붙여야 할 필요가 있어, 이 라벨링 주석 비용은 엄청난 것입니다. 그래서 저자는 인스타그램 게시물을 비롯한 온라인상의 라벨 없는 대량 데이터셋을 사용하여 비지도 학습을 수행하는 솔루션을 제안했습니다.
제안된 방법
데이터
먼저 입력 데이터지만, 이것은 '비디오 중 어느 시점의 프레임(2차원 정지영상)'입니다. 또한 입력 데이터 라벨은 3차원 라벨 데이터, 2차원 라벨 데이터, 라벨 없는 데이터의 3가지가 존재하며, 각각 다음과 같이 되어 있습니다.
|
모델
다음으로 모델에 대한 설명입니다. 그림 2는 논문의 저자가 제시한 모델입니다.

우선, 입력 데이터는 ResNet에 의해 학습이 이루어지며 특징량 φ를 출력합니다. 다음으로, 특징량 φ를 f (movie)에 입력하면 사람의 실제 움직임을 표현하는 특징량인 Φ를 출력합니다. 마지막으로, 특징량 Φ를 f (t-Δt) , f (3D) , f (t + Δt)에 입력하면 과거, 현재, 미래 일련의 3차원 메쉬 구성에 필요한 파라미터인 Θ (t-Δt) , Θ (t) , Θ (t + Δt)를 출력합니다. 또한 hallucinator에 의해 사람의 움직임을 표현하는 특징량을 생성하고 실제 특징량인 Φ와 비교합니다.
반 지도 학습
반 지도 학습 은 라벨 데이터와 라벨 없는 데이터를 모두 이용한 학습법입니다. 이번 연구에서는 다음과 같은 순서로 학습을 실시합니다.
|
OpenPose는 이차원 정지 이미지의 인간 자세 정보(관절)를 높은 정밀도로 검출할 수 있는 모델입니다. 이러한 순서로 학습을 실시하여, 양이 적은 라벨 데이터뿐만 아니라 인터넷에 대량으로 존재하는 라벨 없는 데이터도 유효하게 활용할 수 있습니다.
실험
데이터셋
먼저 이번 실험에 사용된 데이터 세트에 대해 소개하고 있습니다.
Human3.6M (H36M)
3차원 라벨 데이터셋. 약 6시간 반 영상. 이번 실험에서는 모델의 학습 및 정확도 평가에 사용한다.
3DPW
3차원 라벨 데이터셋. 이번 실험에서는 모델의 정확도 평가에만 사용한다.
Penn Action (Penn)
2차원 라벨 데이터셋. 분량은 약 1시간 미만. 15 스포츠 경기 장면이 담겨있다. 이번 실험에서는 모델의 학습 및 정확도 평가에 사용한다.
NBA
2차원 라벨 데이터셋. 분량은 약 30분 미만. NBA에서 16경기 분량의 3점 슛 장면이 담겨있다. 저자가 작성함. 이번 실험에서는 모델의 학습 및 정확도 평가에 사용한다.
VLOG people
라벨 없는 데이터셋. 분량은 약 4시간. VLOG lifestyle dataset의 일부. 이번 실험에서는 모델의 학습에만 사용한다.
Insta Variety
라벨 없는 데이터셋. 분량은 약 1일. 인스타그램 게시물 중 #instruction과 #swimming, #dancing 등의 해시태그(84종류)가 붙은 게시물을 수집. 저자가 작성함. 이번 실험에서는 모델의 학습에만 사용한다.
이상의 6가지 데이터셋을 이번 실험에서 사용합니다.
실험
이번 연구에서는 다음과 같은 두 가지 실험을 실시하고 있습니다.
|
그러면 위의 두 실험 내용을 각각 정리해 보겠습니다.
스틸 이미지 속 인물의 3차원 메쉬 모델의 복원
스틸 이미지에 찍혀있는 인물의 3차원 메쉬 모델의 복원을 진행합니다. 실제 입력과 출력은 아래 그림에 나타냅니다.

첫 행의 이미지가 입력이고, 2행의 3차원 메쉬 모델이 각각의 입력에 대응한 출력입니다. 또한 3행의 메쉬 모델은 2행의 메쉬 모델을 다른 관점에서 본 것입니다. 아래 표는 실험 결과입니다.
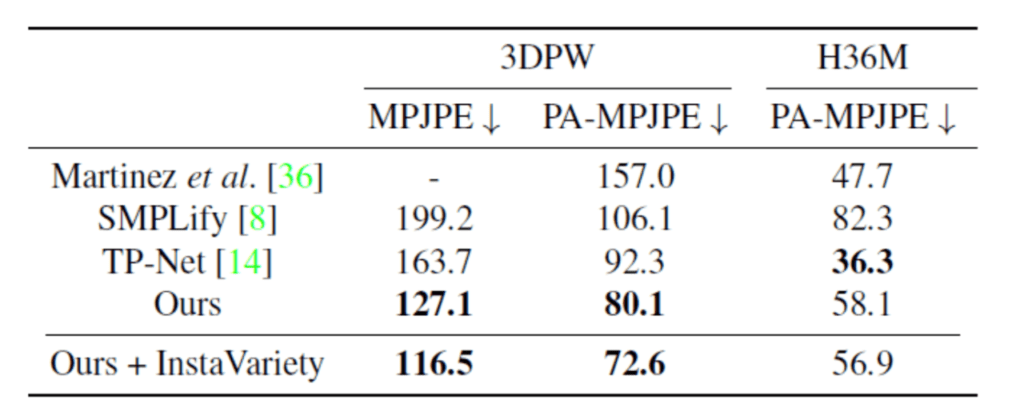
MPJPE라는 것은 각 관절점의 오차(단위 : mm)의 평균을 나타내며, 이것이 작을수록 정확도가 좋다고 말할 수 있습니다. PA-MPJPE는 물체의 크기와 위치, 회전 등의 요소를 고려하여 각 접점에서의 오차(단위 : mm)를 측정하고 이를 평균한 것이며, 이 또한 작을수록 정확도가 좋다고 할 수 있습니다. 또한 Ours는 라벨 데이터셋 만을 사용한 지도 학습이며, Ours + InstaVariety는 라벨 데이터셋 이외에 라벨 없는 데이터셋인 Insta Variety를 사용한 비 지도 학습입니다. 표를 보면, 3DPW 데이터셋에서 state of the art를 획득했고, TP-Net의 정확성보다 제안된 기법이 앞선다는 것을 알 수 있습니다.
스틸 이미지 속 인물의 3차원 모션 복원
스틸 이미지에 찍혀있는 인물의 3차원 모션을 복원합니다. 실제 입력과 출력을 아래 그림으로 나타냅니다.

첫 행의 이미지가 입력이고, 2행의 3차원 메쉬 모델이 각각의 입력에 대응한 출력입니다. 또한 3행의 메쉬 모델은 2행의 메쉬 모델을 다른 관점에서 본 것입니다. 아래는 실험 결과입니다.

스틸 이미지 속 인물의 3차원 모션 복원을 시도한 것은 이번 연구가 처음이며, 기존 연구가 존재하지 않기 때문에 비교 기준이 존재하지 않습니다. 그래서 현재의 프레임워크에서 과거와 미래의 프레임 워크를 예측했을 때의 예측 성능(Const)과 가장 가까운 이웃에 의한 예측 결과(NN)를 기준으로 설정했습니다. 또한 Ours 1은 hallucinator에 의해 생성된 인간의 움직임을 표현하는 특징량과 실제의 특징량 Φ의 오차가 제안 모델의 오차 함수에 포함된 모델이며, Ours 2는 포함하지 않은 모델입니다. 표를 살펴보시면 제안된 방법이 과거와 미래의 프레임워크 예측 정확도에서 우수한 결과를 내는 것을 알 수 있습니다.
정리
이번에는 '스틸 이미지 속 인물의 3차원 모션 복원'을 시도한 연구를 소개했습니다. 이번 연구에는 두 가지의 공헌이 있습니다.
|
우선 '스틸 이미지 속 인물의 3차원 모션 복원'을 처음 시도한 것은 매우 큰 공헌입니다. 이 연구는 스포츠 업계뿐만 아니라 다양한 산업 분야에서 응용할 수 있습니다. 예를 들어, 보안 카메라가 취득한 이미지에 적용함으로써 범죄자의 3차원 모션을 복원하는 것이 가능해져, 범죄 발생 시 수사를 지원할 수 있습니다. 또한 여러 기술 장인의 움직임을 녹화한 비디오에 적용하여 장인들의 움직임을 3차원으로 관찰하는 것이 가능해져, 기술 계승을 지원할 수 있습니다. 이외에도 다양한 응용을 생각할 수 있습니다.
다음 두 번째 공헌입니다만, 비 지도 학습이 3차원 자세 추정에 효과가 있는 것으로 나타났다는 것도 매우 큰 공헌입니다. 특히 이번 연구에서는 3차원 자세를 추정하는 작업에서 라벨 없는 데이터셋에 3차원 자세 정보가 아닌 2차원 자세 정보를 사용하여 라벨 및 정밀도의 향상을 도모했습니다. 라벨 없는 데이터에 부여하는 라벨이, 라벨 있는 데이터보다는 정보량이 작아도 정밀도 향상에 연결되는 중요한 지식이며, 다른 작업에의 응용 가능성도 높습니다. 3차원 자세 추정과 같이 라벨 정보량이 많이 필요하고 부여하기 어려운 유사한 작업에 응용 가능성이 높기 때문에 꼭 도전해 볼 가치가 있습니다.
이번 연구에 사용한 데이터셋과 모델의 소스코드는 다음 사이트에서 공개되고 있습니다.
akanazawa/human_dynamics
Project for paper "Learning 3D Human Dynamics from Video" - akanazawa/human_dynamics
github.com
Learning 3D Human Dynamics from Video
written by Angjoo Kanazawa, Jason Y.Zhang, Panna Felsen, Jitedra Malik
(Submitted on 20 Aug 2019)Accepted to CVPR2019
Subjects : Computer Vision
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| 메타 학습의 단점을 극복? CACTUs의 등장 (0) | 2020.01.08 |
|---|---|
| 알리바바, 고객 서비스 만족도를 대화 로그로 예측 (0) | 2020.01.07 |
| 일본의 AI사업을 견인하는 인기 기업 랭킹 5선 [2020년판] (0) | 2020.01.06 |
| 단어의 삽입/삭제를 이용한 새로운 문장생성 기법이 등장 (0) | 2020.01.03 |
| 생성 이미지를 마음대로!? 새로운 GAN 프레임워크 'VCGAN' (0) | 2020.01.02 |
| AI학습을 더 인간 답게? 학습 경험을 살린 MTL학습법의 등장! (0) | 2020.01.01 |
| 훈련 데이터에 없는걸 만든다고!? 최신식 GAN : COCO-GAN (0) | 2019.12.28 |
| Minecraft에서 강화학습?! 데이터셋 'MineRL'의 탄생 (0) | 2019.12.27 |



