라벨링
스탠퍼드 대학 컴퓨터 과학 학과의 Michael Bernstein 부교수는 자신이 관련된 AI 프로젝트에서 데이터 라벨링에서 얻은 교훈을 살린 데이터 라벨링 방법을 설명하고 있습니다.
Labeling and Crowdsourcing - Data-centric AI Resource Hub
Asking someone to perform an annotation task, such as labeling an image with text or classifying it into a certain category, may seem simple. However, the huge number of different interpretations of the task makes it difficult for machine learning practiti
datacentricai.org
Bernstein 부교수에 의하면, 데이터 라벨링에 있어서 일관성이 손상되어 버리는 것은, 라벨러(라벨 부착 작업자)의 능력 부족이라기보다, 라벨링 업무 관리자가 적절하게 라벨링을 관리/운영하고 있지 않기 때문이라고 합니다.
이러한 라벨링에 있어서의 관리 불신은, Ng(응) 교수의 프레젠테이션에서도 구체적 사례를 들어 설명되고 있습니다. 예를 들면 다음과 같은 2마리의 이구아나가 찍혀 있는 화상에 대해서(슬라이드 좌측), 「이구아나를 감싸서 나타내라」라고 지시를 내릴 경우, 슬라이드 우측과 같이 3가지로 해석될 수 있습니다. 이 경우에 있어서, 항상 동일하게 해석할 수 있도록 지시를 내리기 위해서는 복수의 이구아나가 찍혀 있을 때와 이구아나가 겹쳐있을 때의 대처도 지시하지 않으면 안 됩니다.

이와 같은 라벨링 작업에서 관리 불신을 해소하기 위해, Bernstein 교수는 라벨링의 전체 프로세스를 명확하게 정의하고 라벨러에 의해 라벨링에 차이가 발생하지 않도록 하는 게이티드 인스트럭션(Gated Instruction) 기법을 추천하고 있습니다. 이 기법은 다음의 6개 항목을 실행합니다.
- 태스크를 설계하기 전에 스스로 많은 예제에 라벨을 붙여본다.
- 라벨링 근로자에게 공정한 보상과 대우를 준다.
- 항상 작은 파일럿으로 시작한다.
- 라벨링 실수는 작업자의 스킬 부족이 아니라 관리자의 지시에 문제가 있다고 생각한다.
- 피드백하면서 라벨링을 교육한다.
- 적은 인원으로 더 많은 풀타임을 고용하도록 한다.
게이티드 인스트럭션에 대한 자세한 내용은 이 논문을 참조하십시오.
데이터 강화
캘리포니아 공과대학교 소속의 Anima Anandkumar 교수는 데이터 증강에 관한 기사를 공개하고 있습니다. 이 기사에서는 먼저 학습 데이터 전반에서 볼 수 있는 다음과 같은 세 가지 불완전성을 나열합니다.
Data Augmentation - Data-centric AI Resource Hub
The lack of volume and diversity of data in raw datasets can hold back AI system performance. Read about systematic approaches to filling in information gaps in your dataset through artificially generated data.
datacentricai.org
- 도메인 갭 : AI 모델의 훈련에 사용하는 학습 데이터와 실세계에서 실제로 예측되는 데이터는 다른 경우가 많다.
- 데이터 바이어스 : 수집된 학습 데이터는 수집된 모집단에 사회적 편향이 있을 때 바이어스를 포함한다.
- 데이터 노이즈 : 라벨링이 모호하거나 지저분하면 라벨에 노이즈가 발생한다.
위 제약을 극복하기 위해 학습 데이터를 보완하는 것은 효과적입니다. 이러한 데이터 향상에는 다음의 두 가지 기술이 있습니다.
- 자기 교사 학습 : 라벨이 있는 데이터와 라벨이 없는 데이터를 사용하여 교사가 있는 학습과 동등 이상의 학습 효과를 실현하는 기법. 라벨이 없는 데이터는 라벨이 있는 데이터를 회전하거나 잘라내어 생성됩니다.
- 합성 데이터 : 특정 도구를 사용하여 학습 데이터를 생성하는 기술.
Anandkumar 교수에 따르면 데이터 중심의 AI 관점에서 데이터 확장을 수행할 때 라벨링이 바뀌는 경계가 명확해지도록 학습 데이터를 준비해야 합니다. "라벨링이 변화하는 경계"를 개의 이미지 인식을 예를 들여 설명하면, 개의 이미지에 어떠한 가공을 더하면 더 이상 개로 인식되지 않게 되는, 그 개와 개가 아닌 것의 경계선을 의미합니다.
이상과 같은 라벨링의 경계에 주목한 연구 사례로서, Anandkumar 교수는 SimCLR (A Simple Framework for Contrastive Learning of Visual Representations의 약칭)을 들고 있습니다. 2020년 제프리 힌턴 교수 등이 발표한 SimCLR의 논문에 따르면 전략적 데이터 증강을 실시한 결과, 힌턴 교수가 발표하고 일약 주목을 받았던 이미지 인식 모델 AlexNet에 비해 학습 데이터량이 100 분의 1 정도로 같은 모델의 성능을 크게 능가하는 모델을 개발할 수 있었습니다.

기술적 부채(빚)의 원인으로서의 데이터와 그 대처법
Google Brain 디렉터인 D. Sculley는 데이터 부족으로 인한 기술적 부채에 대해 논의한 기사를 발표했습니다. 기술적 부채란 기술적 타협(버전업을 늦추는 등)의 결과, 이후의 리노베이션에서 발생하는 비용을 의미합니다. 일반적으로 IT 시스템은 기술적 부채가 발생하지 않도록 지속적인 유지보수가 필요합니다.
Data in Deployment - Data-centric AI Resource Hub
AI systems can be relatively easy to build, but difficult to maintain after deployment. Read about hidden technical debt and how data dependencies can affect long-term maintenance of your AI system.
datacentricai.org
AI 시스템에서 기술적 부채는 AI 모델에서 발생하는 것으로 생각되기 쉽지만, 실제로는 데이터 유지보수가 부족하기 때문입니다. 이 주장의 근거로 Sculley는 다음과 같은 두 가지를 언급합니다.
- AI 시스템에서 AI 모델이 차지하는 위치 : AI 시스템의 소스 코드 전체에서 AI 모델의 그것이 차지하는 것은 5% 이하(아래의 이미지에서 검은색 「ML Code」가 해당)이며, 대조적으로 데이터 관련 처리는 70%.
- 데이터야말로 AI 시스템의 코드 : (학습) 데이터가 AI 시스템의 동작을 결정하기 때문에 데이터는 그야말로 소스코드 그 자체이다.(Ng 교수도 지적)
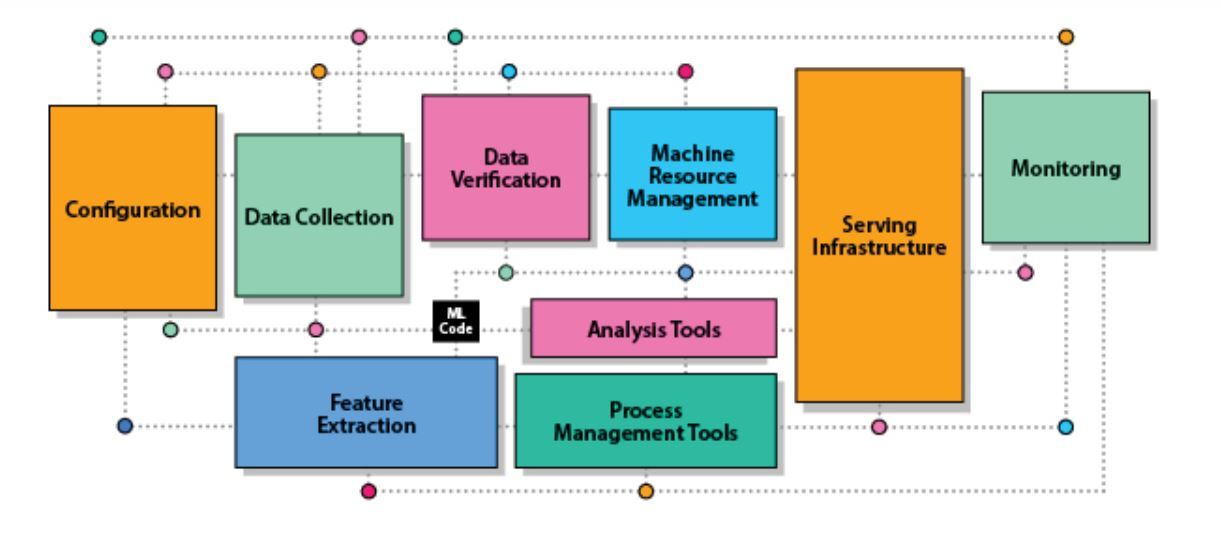
데이터로부터 기술적 부채가 발생하지 않도록 하는 데이터 관리 기법으로서, Sculley 씨는 다음과 같은 3가지를 들고 있습니다.
- 데이터 품질 감사 및 모니터링 : 데이터를 수동/자동으로 모니터링하여 데이터의 품질 및 분포 변화를 조기에 발견합니다.
- 데이터 관련 문서 작성 : 데이터에 대한 투명성과 책임을 다하는 문서를 작성합니다. 이러한 문서의 사양에 관해서는 Microsoft Research 등의 연구팀이 2021년에 제창한 데이터시트가 있습니다.(※주석 1)
- 스트레스 테스트 작성 및 적용 : 현실에 있을 수 없거나 드문 데이터를 모아 스트레스 데이터 세트를 작성한 후 모델을 평가합니다. 이러한 스트레스 테스트를 통하여 학습 데이터에 의한 훈련에서 발생하지 않은 예외 입력에 대한 동작을 평가할 수 있습니다.
이상과 같이 데이터에 기인하는 기술 부채와 그 예방 방법을 설명한 후, 데이터를 지속적으로 유지하는 것이 결과적으로 AI 시스템의 품질을 저비용으로 유지하게 된다고 Sculley 씨는 역설합니다.
| 기입사항 | 개요 |
| 동기 | 데이터세트를 작성한 이유와 자금제공 등의 이해관계를 명기한다. |
| 구성 | 데이터의 종류(예를 들면, 텍스트 데이터인지, 화상인지), 데이터 수 등 데이터의 구성을 명기한다. |
| 수집 프로세스 | 데이터를 수집한 방법이나 수집에 사용한 툴 등을 명기한다. |
| 전처리/클리닝/라벨링 | 전처리/클리닝/라벨링을 수행한 방법을 명시한다. |
| 용도 | 데이터 세트의 용도와 사용해서는 안되는 작업이 있으면 명시한다. |
| 배포 | 데이터 세트를 언제 어떻게 누구에게 배포할지 명시한다. |
| 유지보수 | 데이터 세트를 언제 누가 어떻게 관리할지, 데이터의 관리 체제를 명시한다. |
요약
데이터 중심의 인공 지능은 주목받기 시작했기에 아직 체계적인 지식이나 노하우는 확립되지 않았습니다. 그러나 이 연구 성과를 꾸준히 업데이트할 것으로 보이는 Data-centric AI Resource Hub 등을 참조하여 최신 정보를 캐치업하는 것이 바람직할 것입니다.
또한 데이터 중심의 AI에서 현시점에 논의되고 있는 AI 시스템 품질은 '정밀도'같은 성능적 측면이 대부분을 차지하고 있습니다. AI 시스템 품질에는 성능 측면 외에 편향된 판단을 내리지 않거나, 바이어스가 포함된 결과를 출력하지 않는 등 윤리적 측면도 있습니다. 이러한 윤리적 측면은 데이터 준비와 유지보수를 개선함으로써 완화될 수 있다고 생각됩니다. 그러므로 AI 윤리에 있어서 데이터 중심의 노력도 앞으로 이루어질 것이라 생각됩니다.
관련글
새로운 AI 개발 사상「데이터 중심의 AI」입문
92%의 AI 실무자가 만난 「데이터 캐스케이드」 문제 머신러닝 모델의 오류가 누적되는 현상을 데이터 캐스케이드(Data Cascade) 현상이라고 합니다. 기존의 AI 연구 개발에서 중시되어 온 것은 AI
doooob.tistory.com
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| Meta의 세분화 모델 Segment Anything Model(SAM) 논문 간단 리뷰 (0) | 2023.04.07 |
|---|---|
| GPT-4 총평 : 성능, 응용 사례, 안전 대책 및 리스크를 전망 (0) | 2023.03.24 |
| ChatGPT와 Stable Diffusion을 낳은「기계 학습 소프트웨어」의 10년간의 흐름을 전문가가 해설 (0) | 2023.01.18 |
| 이미지 생성 AI는 크리에이터 이코노미를 증강할 것인가, 아니면 파멸시킬 것인가? (0) | 2023.01.11 |
| 새로운 AI 개발 사상「데이터 중심의 AI」입문 (0) | 2022.08.31 |
| 왜 AI는 언어와 예술 분야에서 빠르게 진화하는가? (0) | 2022.08.27 |
| AI 엔지니어의 장래성과 그만두는 이유 5가지 (0) | 2022.08.13 |
| [AI] 분류 - 재현율과 적합률 : 영화 '맨 인 블랙'을 이용한 설명 (0) | 2021.08.16 |



