
3개의 요점
✔️ 테이블 데이터를 자동으로 학습하여 높은 성능을 발휘하는 AutoML 프레임워크
✔️ 기존 AutoML 프레임워크 모델이 하이퍼 매개변수의 선택을 중시하는 반면,
이 방법은 여러 레이어를 사용하여 모델의 앙상블과 스태킹을 실시
✔️ 이 논문에서는 주요 AutoML 프레임워크의 비교를 실시
AutoML이란?
AutoML (Automated Machine Learning : 자동화된 기계 학습)은 그 이름과 같이 기계 학습 모델의 설계 · 구축을 자동화하는 기술 전반을 일컫는 용어입니다. 신경망의 구조를 자동으로 탐색하는 NAS(Network Architecture Search)나 모델의 하이퍼 매개 변수를 탐험하는 HPO(Hyper Parameter Optimization)도 AutoML의 일부라고 할 수 있습니다.
AutoML의 매력은 뭐니 뭐니 해도 특별한 머신러닝 및 딥러닝 지식이 없어도 강력한 머신러닝 모델의 구축이 가능하다는 것입니다. 또한 이미 머신러닝에 정통한 전문가에게 있어서도 모델 앙상블 기법, 하이퍼 매개 변수의 선택과 특징량 선택, 데이터 전처리 등의 작업은 높은 비용이 들기 때문에 AutoML을 사용함으로써 보다 효율적인 작업이 가능해집니다.
이번에 소개하는 AutoGluon-Tabuler를 보면 무려 한 줄의 코드만으로 원시 테이블 데이터(엑셀의 표와 같은 데이터)를 자동으로 전처리부터 학습까지 가능하게 해 버리는 매우 유용한 프레임워크가 등장하고 있습니다.
AutoML에 있어서 CASH란?
AutoML에서 CASH(Combined Algorithm Selection and Hyperparameter optimization problem)는 최적의 기계 학습 모델(algorithm) 및 해당 하이퍼 파라미터(hyperparameter)를 탐색하는 작업을 말합니다. 이 검색 공간은 대부분의 경우 비 연속적이기 때문에 계산 비용이 매우 높아진다는 특징이 있습니다. 예를 들어, 잘 알려진 하이퍼 매개 변수 탐색 방법으로 그리드 검색이 있지만, 이것은 모든 하이퍼 매개 변수의 조합을 전부 조사하는 방법으로 매우 비효율적입니다.
기존 AutoML 프레임워크와 달리 AutoGluon-Tabler는 CASH를 해결하는 것을 중요시하지 않습니다. 무슨 말인가 하면 앞서 본 바와 같이 CASH란 모델과 하이퍼 매개 변수의 탐색 작업이며, 모델에 입력하는 데이터의 전처리는 분석가가 직접 수행해야 합니다. 그러나 실제 기계 학습에서 가장 귀찮은 것이 이 부분입니다. AutoGluon-Tabuler는 고급 데이터 처리를 통해 이러한 문제를 해결하면서 신경망과 계층 구조를 가진 앙상블 기법을 통해 테이블 데이터의 학습에서 높은 성능을 실현하고 있습니다.
AutoGluon-Tablar
본 논문의 필자는 AutoML를 설계하는 데 있어서 다음과 같은 원칙을 지키는 것이 중요하다고 주장하고 있습니다.
1. 단순함
- 기계 학습에 대해 잘 모르더라도 원시 데이터로부터 직접 모델을 학습할 수 있는 것.
2. 견고
- 다양한 종류의 수많은 구조화 데이터를 처리할 수 있어서, 학습에 실패하지 않을 것.
3. 복원력
- 학습을 일단 멈춰도 다시 재개할 수 있을 것.
4. 예측 가능한 학습 시간
- 사용자가 학습에 걸릴 시간을 지정할 수 있을 것.
그러면 AutoGluon-Tabler가 어떻게 이러한 원칙을 달성하고 있는지 자세히 살펴보겠습니다.
fit API
지금 train.csv라는 테이블 데이터를 갖고 있고, 예측하고 싶은 라벨이 'class'라는 열에 들어 있다고 합시다. 이때 AutoGluon-Tabler에서는 다음과 같은 세 줄의 Python 코드만으로 학습과 예측이 가능합니다.
from autogluon import TabulerPrediction as task #AutoGluon의 로딩
predictor = task.fit("train.csv", label="class") #학습
predictions = predictor.predict("test.csv") #테스트 데이터에 대한 예측
이것만으로도 태스크가 분류인지 회귀인지, 분류라면 어떤 클래스의 분류인지를 자동으로 판정하고 다양한 모델을 앙상블 시켜 강력한 모델을 학습시킵니다. 이처럼 AutoGluon-Tabuler는 심플함을 달성한 누구나 사용하기 쉬운 프레임워크라고 할 수 있습니다.
데이터의 전처리
첫째, 학습 데이터가 어떤 작업을 위한 것인지 자동으로 판별합니다. 목표 변수가 포함된 열을 참조하고 그 값이 문자열이나 이산 값이면 '분류' 작업, 연속 값이면 '회귀' 작업이라고 판단합니다.
작업을 판별한 후 전처리는 크게 2단계로 나누어집니다. 먼저 모든 모델에 공통되는 처리를 실시한 후, 각 모델에 적합한 처리를 적용합니다. 전자에서는 카테고리 · 숫자 · 문자 · 시간 등의 데이터가 모두 범주형 변수로 변환됩니다. 또한 결손치에 관해서는 unknown이라고 라벨이 부여되기 때문에 학습 시에 관측되지 않은 변숫값이 나타나도 오류가 발생하지 않도록 되어있습니다. 이에 따라 견고성을 보장하고 있습니다.
모델
AutoGluon-Tabuler는 많은 선택에서 모델을 선택하는 것이 아니라 처음부터 이용할 모델을 정해두고 있습니다. 이를 통해 불필요한 모델을 탐색하는 번거로움을 없애고, 제한된 시간 내에 효율적인 학습이 가능합니다. 사용되는 것은 다음의 6가지 알고리즘입니다.
신경망(내용은 아래 참조)
LightGBM(부스팅 트리의 일종)
CatBoost (부스팅 트리의 일종)
랜덤 포레스트
ERT(Extremely Randomized Trees; 랜덤 포레스트의 변종)
k 근 방법
사용하는 알고리즘이 6개밖에 없다는 것은 기존의 AutoML 프레임워크에 비해 상당히 적습니다.
게다가 구현은 sklearn을 사용하고 있습니다.
Multi-Layer Stack Ensembling
※ 본 논문에서는 다음의 '신경망' 장이 먼저 나오지만, 이해도를 높이기 위해 앙상블 학습을 먼저 다루겠습니다.
앙상블 학습(ensembling)은 간단히 말하면 여러 모델들의 출력을 결합하는 방법으로, 일반적으로 각각의 모델 한 개 보다 성능이 개선되는 것으로 알려져 있습니다. AutoGluon-Tabuler가 사용하고 있는 것은 그중에서도 '스태킹'이라 불리는 방법이며, 여러 모델의 출력의 가중값을 최종 출력하는 것입니다. 스태킹 가중치는 선형 모델 등을 사용해 학습됩니다.
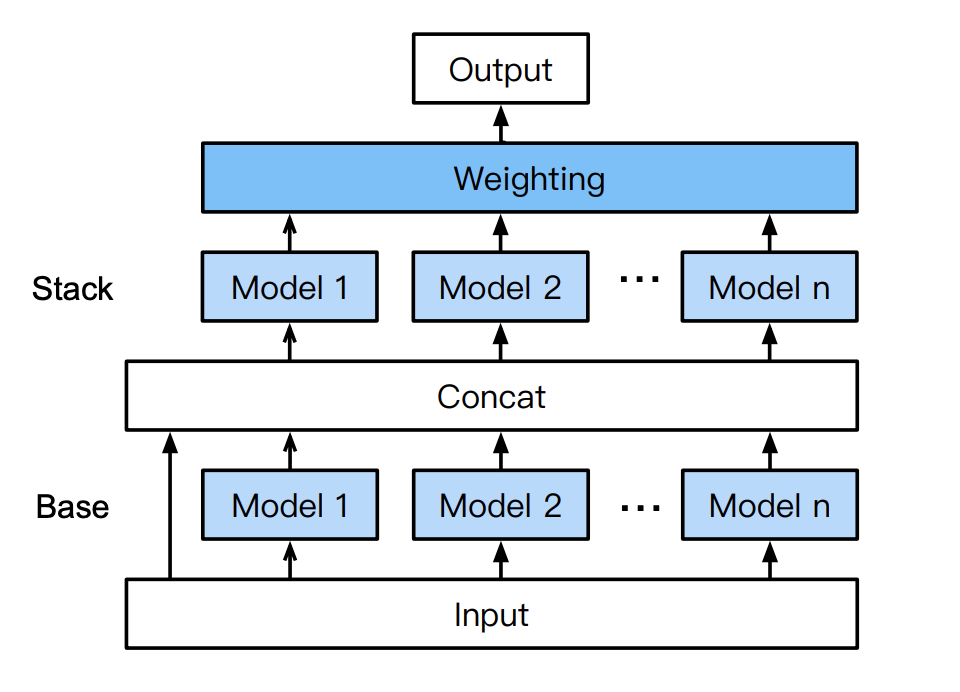
위 그림은 AutoGluon-Tabuler의 다층 스태킹(적층) 구조를 나타냅니다. 학습의 흐름은 다음과 같습니다.
1. n개의 독립적인 모델(6개의 알고리즘에서 선택)에 전처리를 한 데이터(input)를 입력
2. 1의 각 모델의 출력과 input을 결합시켜 1과 같은 알고리즘, 같은 하이퍼 매개 변수 모델에 입력
3. 2의 각 모델의 출력의 가중값을 최종 출력으로 하여, 오차를 계산하여 학습
기존 AutoML에서 사용되어 왔던 스태킹은 단순히 다른 모델 출력의 가중값을 계산하는 것이었지만(단층 스태킹) AutoGluon-Tabuler에서는 각 모델의 출력과 원래의 입력을 스킵 커넥션으로 결합하고 그것을 또한 각각의 모델에 입력하여 스태킹 하고 있습니다(다층 스태킹). 이 구조는 이미지 인식 작업에서 고성능을 발휘하고 있는 ResNet과 MobileNet 등의 구조(심플한 구조층 단방향 쌓기 + 스킵 커넥션)의 응용이라고 할 수 있습니다.
이렇게 함으로써 스태킹 할 때, 각 모델의 출력뿐만 아니라 원래의 입력 데이터도 고려할 수 있게 되어, 기존의 단층 스태킹보다 성능을 향상할 수 있는 것입니다.
신경망
이미지와 텍스트에 신경망이 자주 이용되고 잘 작동하는 이유는 신경망이 이러한 데이터에서 의미 있는 중요한 정보를 골라내는 것이 특기이기 때문입니다(예를 들면, 이미지를 처리하는 회선). 그러나 테이블 데이터는 각각의 열에 성별 · 연령 · 체중 · 신장 등 의미 있는(=각각의 성질이 다른) 변수가 포함되어 있기 때문에 다양한 변수를 선형합으로 혼합해 버리는 신경망보다 결정 트리계의 알고리즘이 더 테이블 데이터의 패턴 인식에 적합할 수 있습니다.
그러나 또 한편으로, 의사 결정 트리계 알고리즘의 앙상블에 적절하게 튜닝된 신경망을 추가하여 성능을 향상하려는 연구도(성격이 다른 알고리즘을 혼합하여 앙상블 모델 바이언스를 작게 할 수 있습니다), 테이블 데이터 학습의 정확도 향상 목표를 위해서도 신경망을 잘 활용하는 것이 과제였습니다. 다른 주요 AutoML 프레임워크도 신경망을 이용하는 것이 있지만, 대부분은 간단한 MLP(다층 퍼셉트론)를 이용하는 것에 머물고 있습니다.
그래서 AutoGluon-Tabuler는 아래 그림과 같은 구조의 신경망을 제안하고 있습니다.

카테고리 데이터와 수치 데이터를 정리해 Dense 층에 넣는 것이 아니라, 카테고리 데이터는 Embedding 층에 채우고, 수치 데이터는 Dense 층을 통과시켜 ReLU에서 활성화한 것을 결합합니다. 이렇게 하면 원래 카테고리 데이터였던 것과 수치 데이터였던 것이 선형합으로 혼합되기 전에 두 특징량을 신경망이 별도로 학습할 수 있습니다. 또한 여기서도 스킵 커넥션을 이용하는 것으로, 원래 테이블 데이터의 성질을 잊지 않게 하는(각 변수를 혼합해 버리는 것을 방지하는) 효과를 낳고 있습니다.
Repeated k -fold Bagging
먼저 k -fold에 대해 설명합니다. 데이터 세트를 k개의 그룹(fold)에 동일하게 분할하여 그중 1그룹(fold)을 테스트 데이터, 다른 그룹(fold)을 훈련 데이터로 하나의 모델을 학습합니다. 이를 k번 그룹 간 테스트 데이터를 순환하여 k 개의 모델을 만들고, 최종 예측치는(많은 경우) k개의 모델의 출력 평균값으로 합니다. 이른바 교차 검증법입니다.
Repeated k -fold Bagging이란, k -fold를 지정한 횟수(n회)만큼 반복하는 방법입니다. AutoGluon-Tabuler 학습 방법을 의사 코드로 살펴봅시다.

셋째 줄에서 시작되는 for문을 보면, 다층 적층 모델의 각 계층의 학습을 시작할 때마다 무작위로 데이터를 k 분할하도록 작성되어 있습니다. 이것을 n번 반복하라는 것이 for문의 지시입니다. 결국 하나의 층의 출력은 각각의 fold 출력의 평균이 되고 있습니다.
Repeated k -fold Bagging을 이용하여 fold에 포함된 데이터가 적은 경우에도 모델의 과학습을 방지할 수 있습니다.
AutoML 프레임 워크의 비교
- Auto-WEKA : AutoML의 원조. Java의 기계 학습 라이브러리인 WEKA에 대한 CASH를 베이스 최적화를 통해 해결하고 있습니다.
- Auto-Sklearn : 익숙한 Python의 기계 학습 라이브러리 scikit-learn에 대한 CASH를 해결합니다. 하이퍼 매개 변수의 탐색에 메타 학습을 이용하고 있는 것이 특징입니다.
- TPOT : 진화 알고리즘을 사용하여 기계 학습 과정을 최적화하는 도구입니다.
- H2O AutoML : 특히 Kaggle 공모전에서 자주 사용되는 라이브러리입니다. 하이퍼 매개 변수 탐색에 무작위 검색을 사용하고 있음에도 불구하고 종종 다른 라이브러리보다 좋은 성적을 내는 점이 흥미롭습니다.
- GCP-Tables : GCP(Google Cloud Platform)에 발표된 AutoML 도구에서 원시 데이터를 업로드하면 쉽게 기계 학습이 가능합니다. 그러나 Google Cloud에서만 사용할 수 있으며, 오픈 소스가 아니기 때문에 내부는 알 수 없는 것이 많습니다.
- 기타(오픈 소스) : auto-egboost, GAMA, hyperopt-sklearn, OBOE, Auto-Keras
- 기타(상용 소프트웨어) : Sagemaker, AutoPilot, Azure ML, H2O Driverless AI, DataRobot, Darwin AutoML
| 이름 | 오픈 소스 | 원시 데이터 대응 | 신경망 | CASH 전략 | 앙상블 기법 |
| Auto-WEKA | ◯ | × | 시그 모이 드 MLP | 베이지안 최적화 | Bagging, Boosting, Stacking, Voting |
| Auto-Sklearn | ◯ | × | 없음 | 베이지안 최적화 + 메타 학습 | Ensemble Selection |
| TPOT | ◯ | × | 없음 | 진화 알고리즘 | Stacking |
| H2O | ◯ | ◯ | MLP + AdaDelta | 무작위 검색 | Stacking + Bagging |
| GCP-Tables | × | ◯ | AdaNet (??) * | AdaNet (??) * | Boosting (??) * |
| AutoGluon | ◯ | ◯ | 카테고리형 변수의 매립 + 스킵 커넥션 | 기본적으로 없음 | Multi-Layer Stack Ensembling + Repeated k -fold Bagging |
*GCP-Table은 오픈 소스가 아니기 때문에 프레임워크의 세부 사양은 알 수 없습니다.
실험 및 결과
OpenML AutoML Benchmark와 Kaggle의 경쟁에서 모은 50개의 테이블 데이터를 사용하여 제한 시간 4시간 동안의 학습 결과를 비교했습니다. Wins / Losses에는 그 프레임 워크가 AutoGluon-Tabuler에 이긴 횟수, Failure에는 학습이 실패한 횟수, Champion에는 그 프레임 워크가 1위를 한 횟수가 기록되어 있습니다(위가 OpenML, 아래가 Kaggle의 결과입니다). GCP-Table 이외는 모두 같은 형태의 EC2 인스턴스에 의해 학습을 실시했습니다. 어떤 프레임워크는 제한 시간을 초과해 버린 것도 있습니다.
AutoML Systems · AutoML Benchmark
There is more to an AutoML system than just its performance. An AutoML framework may only be available through an API for a specific programming language, while others can work stand-alone. Some systems might output models which can be used without further
openml.github.io
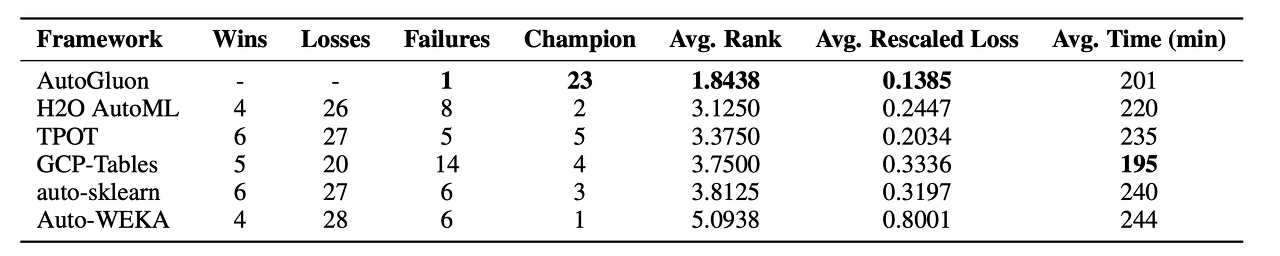

결과를 보면 AutoGluon-Tabuler는 50개의 데이터 중 30개의 데이터에서 1위를 기록하고 있으며, 이것은 다른 프레임워크에 비해 압도적입니다. 또한 OpenML의 데이터는 학습에 실패하고 마는 프레임워크가 적지 않습니다만, AutoGluon-Tabuler는 1회만 실패했습니다. 학습에 걸리는 시간도 OpenML 중에서는 가장 짧고, Kaggle에서도 2번째로 짧습니다.
이상에서 AutoGluon-Tabuler는 견고성, 안정성, 학습시간의 짧음에 있어서 지금까지의 프레임워크보다 뛰어나다고 말할 수 있을 것입니다. 또한 이번 실험에서는 AutoGluon은 하이퍼 파라미터의 최적화를 Off로 했습니다. 그럼에도 불구하고 다른 프레임 워크를 압도하고 있는 것은 AutoML에 있어서 CASH는 중요한 문제가 아니라는 것을 보여줍니다.
결론
본 논문에서는 매우 짧은 코드로 테이블 데이터를 자동 학습할 수 있는 AutoML 프레임워크, AutoGluon-Tabuler이 제안되었습니다.
AutoGluon-Tabuler의 키 포인트는
- 다양한 변수를 포함한 테이블 데이터를 처리할 수 있는 견고한 데이터 처리 기술
- 선진적인 신경망을 이용하고 있는 것
- 다층 스태킹과 repeated k-fold bagging에 의한 강력한 앙상블 학습
위의 3개로 정리할 수 있습니다. 또한 지금까지 (AutoML = CASH)라고 할 정도로 AutoML작업에서 중시되고 있었던 CASH가 사실은 AutoML 작업 중 하나에 지나지 않는다는 것을 보여준 것도 큰 성과라고 할 수 있습니다.
누구나 쉽게 머신러닝을 할 수 있는 시대가 곧 올지도 모릅니다. 앞으로도 AutoML기술의 발전에 주목하고 싶네요.
참고 논문:
AutoGluon-Tabular : Robust and Accurate AutoML for Structured Data
written by Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, Alexander Smola
(Submitted on 13 Mar 2020)
Comments : accepted by ICLR 2020 Conference
Subjects : Machine Learning (stat.ML); Machine Learning (cs.LG)
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| GAN의 발전의 역사( 알고리즘 편 ) (0) | 2020.06.09 |
|---|---|
| 스타벅스는 커피 사업자가 아닌 데이터 테크 기업이다 (0) | 2020.06.03 |
| 완전 비지도 학습으로 라벨링과 특징 표현을 모두 스스로 학습하는 'SeLa' (0) | 2020.05.10 |
| '모르겠다'를 아는 AI, 적은 자원의 환경에서 미학습 도메인을 감지! (0) | 2020.04.20 |
| AI는 인간의 발견을 손쉽게 발견했다, 진화적 검색 알고리즘 (0) | 2020.04.09 |
| 신종 코로나 바이러스의 이미지 데이터셋 공개! (0) | 2020.04.08 |
| 구글이 양자 머신러닝 라이브러리 'TensorFlow Quantum'을 공개 (0) | 2020.03.08 |
| AI는 판타지 세계에서 롤 플레잉이 가능할까? (0) | 2020.03.07 |



