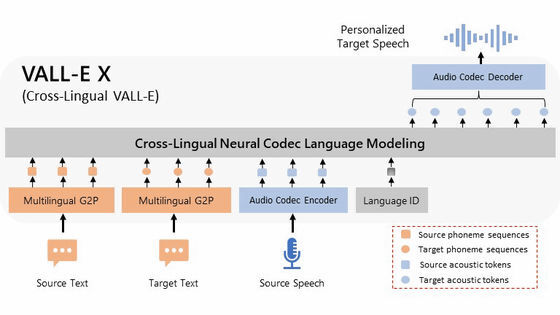
Microsoft가 공개한 VALL-E는 단 3초간의 음성 샘플로 사람의 목소리를 재현할 수 있는 음성 합성 AI입니다. 이 VALL-E에서 영어 이외에도 대응한 「VALL-E X」를 독자적으로 트레이닝한 제로 샷 모델이, GitHub에서 공개되고 있습니다.
제로 샷(zero-shot)이란 무엇인가?
zero-shot 은 쉽게 말하면 "모델이 학습 과정에서 배우지 않은 작업을 수행하는 것"을 의미.
다음과 같은 생성모델에서의 예시들을 들 수 있다.
1. 유인나의 목소리로 음성을 생성하도록 학습한 TTS 모델이 예시 샘플을 이용하여 아이유의 목소리로도 음성을 생성하는 것
2. 셰익스피어처럼 글을 쓰도록 학습한 자연어 생성 모델이 마크 트웨인의 스타일로 글을 쓰는 것
3. 학습 과정에서 존재하지 않았던 종류의 이미지를 생성하는 것
GitHub - Plachtaa/VALL-EX: An open source implementation of Microsoft's VALL-E X zero-shot TTS model.
Demo is available in https://plachtaa.github.io
VALL-E
Model Overview VALL-E X can synthesize personalized speech in another language for a monolingual speaker. Taking the phoneme sequences derived from the source and target text, and the source acoustic tokens derived from an audio codec model as prompts, VAL
plachtaa.github.io
https://github.com/Plachtaa/VALL-E-X
GitHub - Plachtaa/VALL-E-X: An open source implementation of Microsoft's VALL-E X zero-shot TTS model. Demo is available in http
An open source implementation of Microsoft's VALL-E X zero-shot TTS model. Demo is available in https://plachtaa.github.io - GitHub - Plachtaa/VALL-E-X: An open source implementation of Microso...
github.com
VALL-E가 어떤 AI인지는 아래 글을 참고하세요.
Microsoft가 단 3초의 샘플에서 사람 목소리를 재현할 수 있는 음성 합성 AI 'VALL-E'를 발표
Microsoft가 단 3초의 샘플에서 사람 목소리를 재현할 수 있는 음성 합성 AI 'VALL-E'를 발표
2023년 1월 5일에 Microsoft가 새로운 음성 합성 AI 모델「VALL-E」를 발표했습니다. VALL-E는 단 3초간의 음성 샘플로 사람의 목소리를 충실히 시뮬레이션할 수 있는 것 외에, 한 번 학습한 데이터로부터
doooob.tistory.com
VALL-E X는 VALL-E를 확장한 모델로, 소스 언어의 음성과 대상 언어의 텍스트를 모두 프롬프트로 사용합니다. 예를 들어 '영어로 말하는 음성'과 '중국어 문장'을 입력하면 재현된 음성으로 중국어를 읽게 할 수 있습니다.
Microsoft는 VALL-E X에 대해 (PDF 파일 다운로드) 연구 논문이나 모델 개요를 발표하고 있습니다만, 소스 코드나 사전 트레이닝이 끝난 모델은 공개하지 않고 있습니다.
난양 이공대학 전기전자공학부 학생인 Songting Liu(Plachta)씨의 팀은 이 VALL-E X를 재현하는 독자적인 모델을 처음부터 트레이닝하고, 소스 코드와 모델을 공개하고 있습니다.
Microsoft의 VALL-E X의 대응 언어는 영어와 중국어뿐이었습니다만, Plachta 씨의 VALL-E X는 일본어에도 대응하고 있는 것이 특징입니다. Plachta의 VALL-EX 데모는 다음 Hugging Face에서 경험할 수 있습니다.
VALL EX - a Hugging Face Space by Plachta
https://huggingface.co/spaces/Plachta/VALL-E-X
VALL E X - a Hugging Face Space by Plachta
huggingface.co
위의 Hugging Face 데모 페이지에 액세스 하면 이렇습니다.
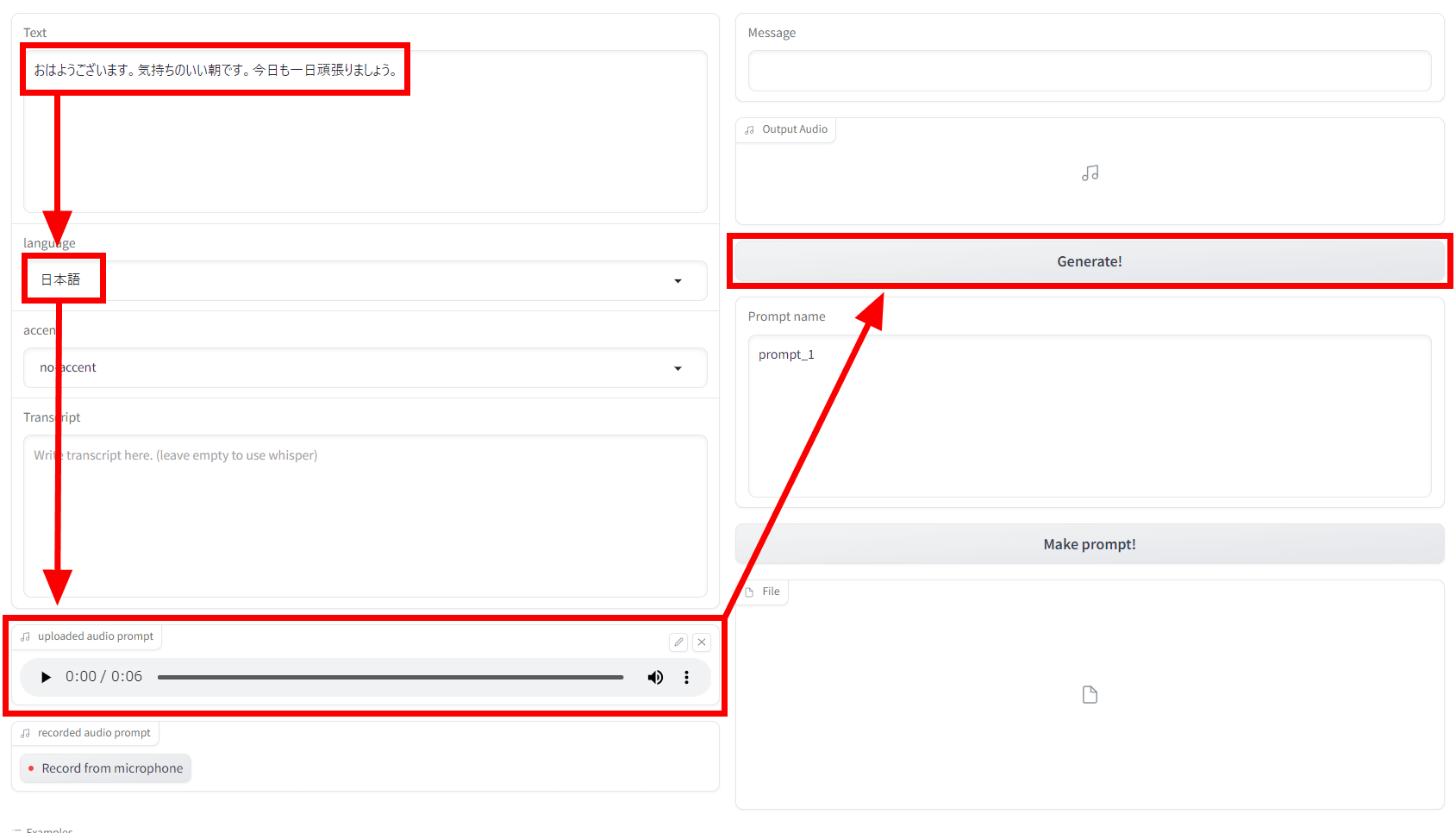
이번에는 영어로 뉴스를 읽는 아래의 음성 파일을 읽어 들여, 일본어로 인사하는 음성을 생성해 보겠습니다.
"Text" 영역에 읽고 싶은 문장을 넣고, "language"에서 Text에 입력한 언어를 선택, "uploaded audio plompt"에 목소리 파일을 읽어 들여 오른쪽 상단에 있는 "Generate!"를 클릭.
3분 정도 기다리자 오른쪽 상단에 생성 내용과 생성된 음성이 표시되었습니다.
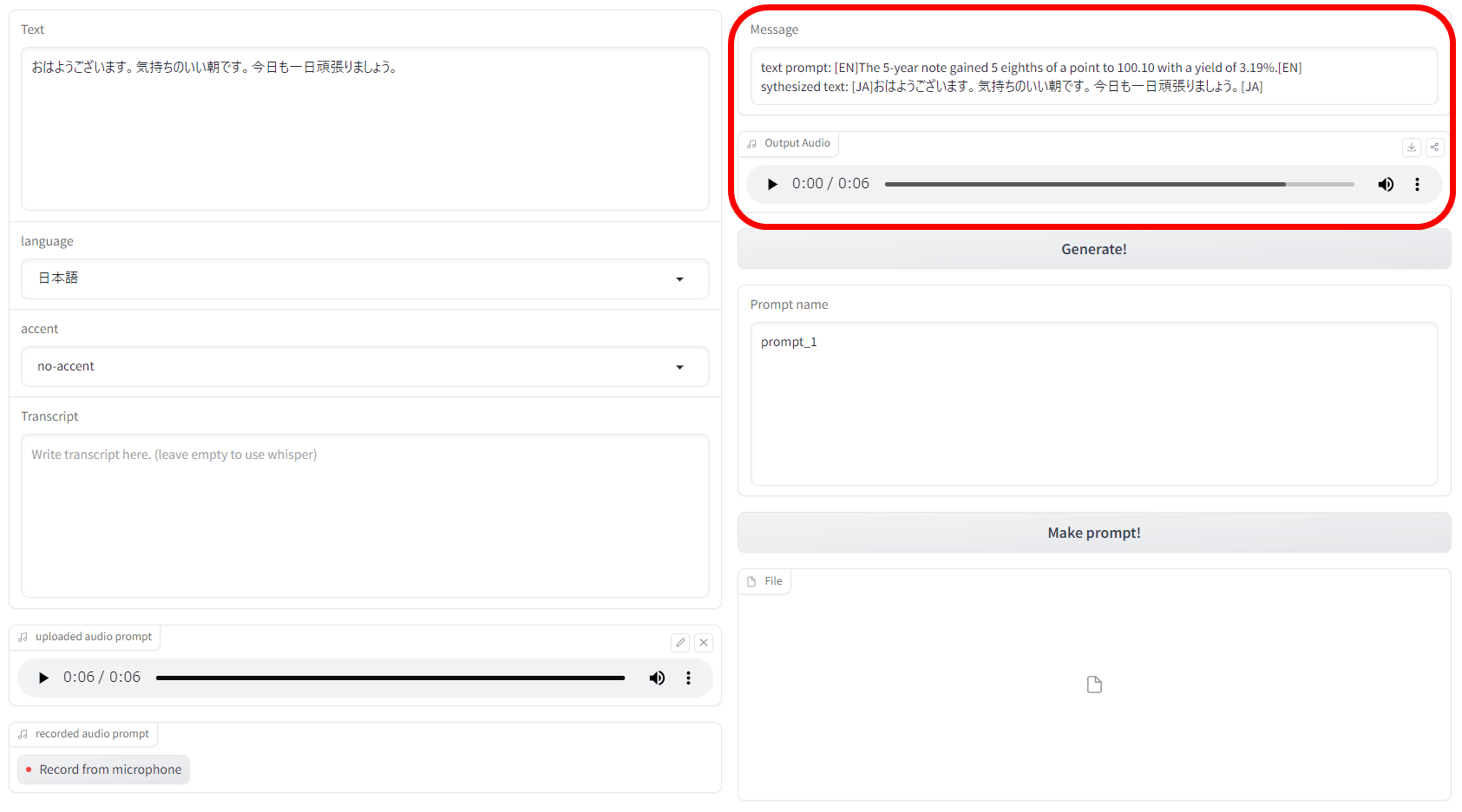
실제로 생성된 음성 파일을 첨부합니다. 원본 음성 파일이 겨우 몇 초로 짧기 때문에, 조금 왜곡된 느낌은 있지만 원본 목소리에 가까운 것이 생성되고 있습니다.
또한 Plachta의 VALL-EX로 생성된 음성 샘플의 예는 아래의 데모 페이지에 다수 공개되어 있습니다.
VALL-E
https://plachtaa.github.io/
VALL-E
Model Overview VALL-E X can synthesize personalized speech in another language for a monolingual speaker. Taking the phoneme sequences derived from the source and target text, and the source acoustic tokens derived from an audio codec model as prompts, VAL
plachtaa.github.io

'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Google이 AI 대응의 PostgreSQL 호환 데이터베이스 서비스 「AlloyDB AI」를 발표 (1) | 2023.08.31 |
|---|---|
| Google Workspace에「PT용 이미지 생성 기능」을 갖춘 AI 서비스 「Duet AI」를 탑재 (0) | 2023.08.31 |
| GPT-4를 2배 빠르게 무제한으로 사용할 수 있는 「ChatGPT Enterprise」 발표 (1) | 2023.08.30 |
| Meta의 코딩 지원 AI 「Code Llama」에 조정을 가하면 OpenAI GPT-4의 성능을 웃돌 가능성 (1) | 2023.08.29 |
| 비트코인에 특화된 대화형 AI 챗봇 「ChatBTC」등장 (2) | 2023.08.28 |
| 임신 8개월의 여성이 AI가 '강도'라고 오인해 체포당하고, 보석금 10만 달러를 지불하는 사태에 (2) | 2023.08.28 |
| AI의 정치적 편향 연구, ChatGPT는 좌파이고 LLaMA는 우파이다 (2) | 2023.08.28 |
| 키보드 소리로 데이터를 훔치는 공포의 「음향 사이드 채널 공격」이 심층 학습으로 정밀도를 향상 (1) | 2023.08.28 |



