이미지와 텍스트를 결합하여 작업을 수행할 수 있는 멀티모달 대규모 언어 모델인 Ferret 의 가중치 정보를 Apple이 공개했습니다. 가중치 데이터는 CC-BY-NC 라이센스로 제공되며 연구 목적으로만 사용할 수 있습니다.
apple/ml-ferret
https://github.com/apple/ml-ferret
GitHub - apple/ml-ferret
Contribute to apple/ml-ferret development by creating an account on GitHub.
github.com
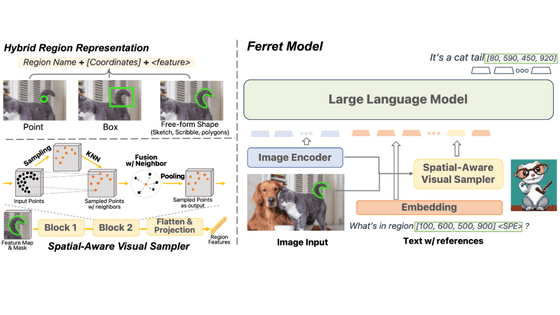
Ferret은 2023년 10월 30일에 공개된 멀티모달 대규모 언어 모델로 이미지의 영역을 지정해 해석할 수 있다는 것이 특징입니다. 영역의 지정 방법에는 「점」, 「사각형」, 「프리 폼」의 3 종류가 존재합니다.
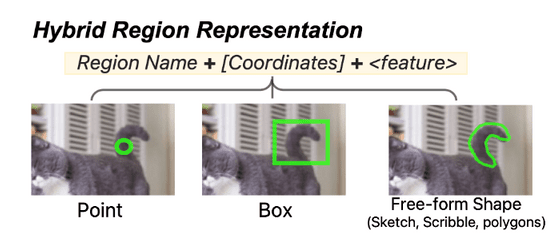
이미지의 일부를 지정하여,「영역 [100, 600, 500, 900]에는 무엇이 있습니까?」와 같이 영역을 참조해 질문하는 것이 가능합니다. Ferret 모델은 이미지와 텍스트를 바탕으로 "고양이 꼬리입니다" 같이 대답할 수 있습니다. 동시에, 보다 정확한 영역의 정보도 대답해 준다는 것.
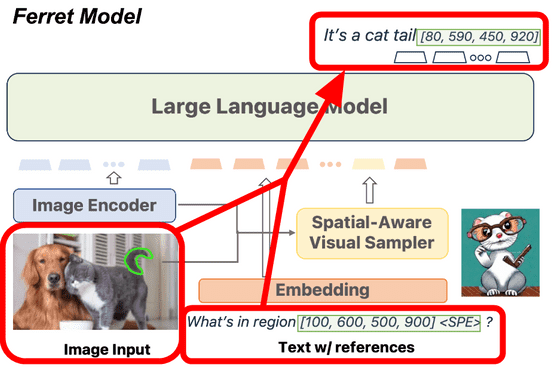
Ferret 모델은 2023년 3월에 공개된 대규모 언어 모델 「Vicuna」를 베이스로 메모리 80GB의 A100 GPU를 8개 사용해 트레이닝되고 있어, 이번 Apple이 공개한 것은 Vicuna의 웨이트로부터의 차분 데이터 전용입니다.
Vicuna는 Meta AI가 2023년 2월에 발표한 LLAMA를 기반으로 파인 튜닝한 모델이기 때문에 Ferret 모델을 이용하기 위해서는 Ferret 모델 차이의 라이센스인 CC-BY-NC 이외에도 Vicuna 및 LLAMA 의 라이센스를 따라야 합니다.
GitHub에서 데모의 기동 방법이나 동작의 모습이 공개되고 있습니다. 데모는 Gradio Web UI를 사용하며 아래 그림과 같이 이미지를 입력하고 영역을 지정하면 왼쪽 하단에 영역 데이터가 표시됩니다. 후에는 그 영역 데이터를 바탕으로 텍스트로 질문하면 됩니다. 이번 예에서는 "물체 [region0]와 물체 [region1] 사이에는 어떤 관계가 있습니까?"라고 질문하고 있습니다.
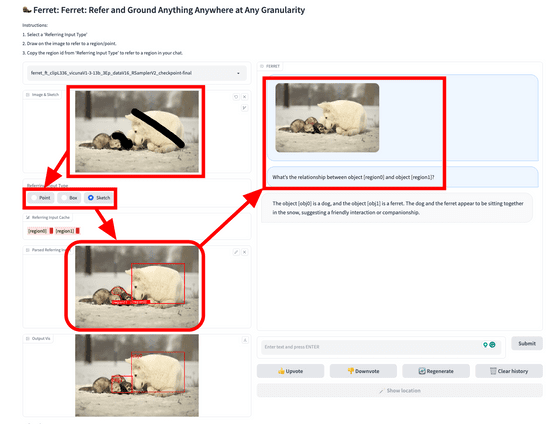
페렛의 대답은 "물체 [obj0]는 개, 물체 [obj1]는 페럿입니다.

동시에 Ferret이 각 영역 내에서 어떤 부분을 인식했는지에 대한 영역 데이터도 응답됩니다.

데모를 이용하려면 Vicuna의 가중치와 Ferret의 차이 데이터를 바탕으로 Ferret의 가중치를 생성하는 절차가 필요합니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Microsoft가 30년 만에 표준 키보드에 새로운 키를 추가, AI 툴에 액세스하는 「Copilot 키」가 등장 (84) | 2024.01.10 |
|---|---|
| 단어와 소리를 오디오 형식으로 변환하는 AI 「Amphion」 테일러 스위프트가 부르는 중국 노래를 생성 (79) | 2024.01.09 |
| 이미지를 분석해 캡션을 자동으로 생성해 주는, 오픈 소스로 상용 이용도 가능한 AI 모델 「BLIP-2」리뷰 (65) | 2024.01.04 |
| 라파엘로의 그림은 공동 제작이었을 가능성이 AI를 사용한 연구에서 분명히 (94) | 2023.12.26 |
| Facebook은 이미 AI가 만든 가짜 게시물로 가득 차 있다 (103) | 2023.12.21 |
| Microsoft가 LLM의 입력 프롬프트의 의미를 유지하면서 고도로 압축하는 기술「LLMLingua」를 개발 (94) | 2023.12.20 |
| Meta가 「Seamless Communication」공개, 화자 톤을 유지하면서 실시간으로 다언어 음성을 번역 (3) | 2023.12.20 |
| 한국의 연세대에서「망막 사진」으로 아이의 자폐증을 100% 분간하는 AI 모델을 발표 (4) | 2023.12.20 |



