
텍스트를 기반으로 이미지를 생성하는 몇 가지 AI 모델이 있지만 고품질 이미지를 생성하는 주요 모델은 수십억 개의 매개 변수를 처리하므로 기본적으로 고사양의 단말이 필요합니다. 2024년 1월 31일 구글 엔지니어들이 「MobileDiffusion」이라는 어프로치를 발표하고 스마트폰과 같은 모바일 기기에서도 효율적으로 이미지를 생성하는 법을 소개했습니다.
MobileDiffusion: Rapid text-to-image generation on-device – Google Research Blog
MobileDiffusion: Rapid text-to-image generation on-device
Posted by Yang Zhao, Senior Software Engineer, and Tingbo Hou, Senior Staff Software Engineer, Core ML Text-to-image diffusion models have shown exceptional capabilities in generating high-quality images from text prompts. However, leading models feature b
blog.research.google
Stable Diffusion이나 DALL-E 등의 모델이 진화하는 한편, 모바일 디바이스로 이미지를 고속 생성하는 것은 그 진행이 더뎠습니다. 특히 노이즈 제거를 반복하여 고품질의 이미지를 생성하는 "샘플링" 등의 시도(스텝) 횟수가 늘어나면 모바일 디바이스의 스펙에서는 처리할 수 없는 경우도 있습니다. 선행 연구에서는 이 샘플링 스텝을 줄이는 것에 초점이 맞춰졌습니다만, 샘플링 스텝을 줄여도 모델의 아키텍처가 복잡하기 때문에 생성에 시간이 걸릴 수 있다는 것입니다.
그래서 Google이 개발한 것이 "MobileDiffusion"입니다. Google은 이를 '모바일 기기용으로 설계된 효율적인 잠재 확산 모델'로 자리매김하고 있으며 512 ×512픽셀의 고화질 이미지를 Android 및 iOS 기기에서 0.5초 만에 생성하는 등 모바일 기기 전문 이미지 생성 모델로 완성하고 있다는 것입니다.
아래 이미지는 모바일 장치에서 실시간으로 이미지를 생성하는 모습입니다.
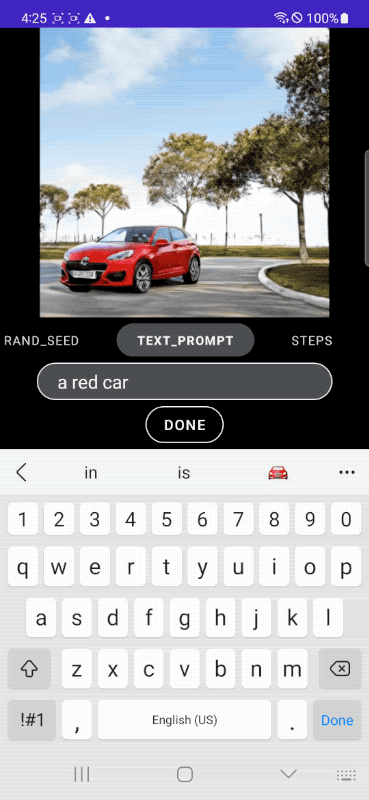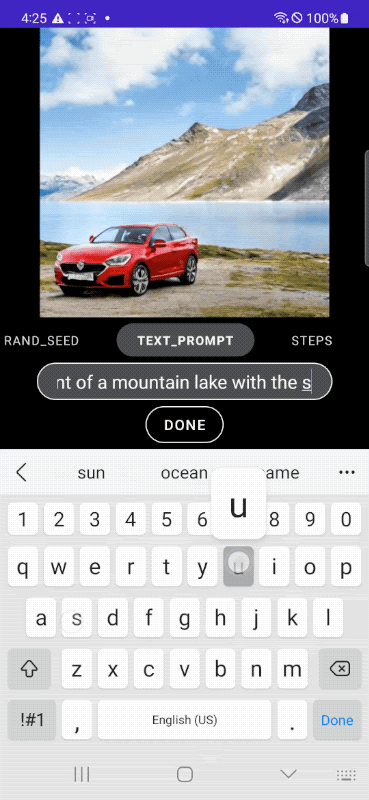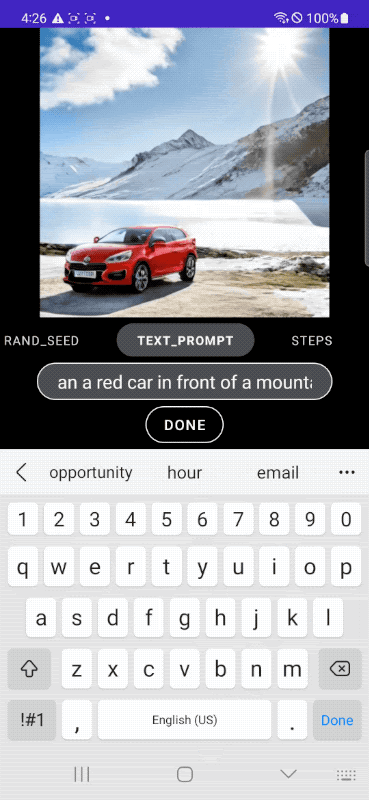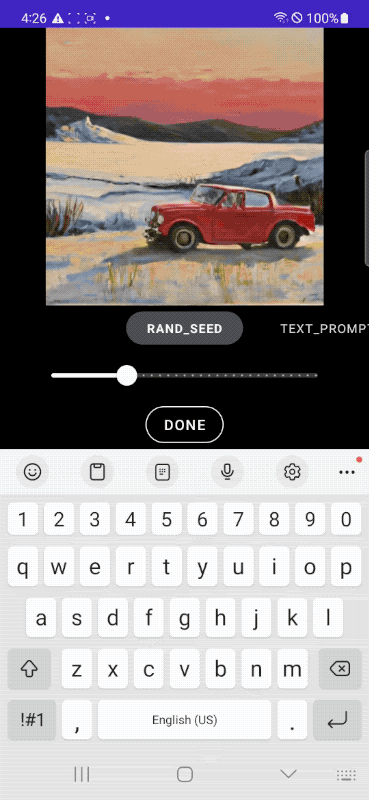
Google은 아키텍처의 복잡성을 해소하기 위해 DiffusionGAN을 채용하여 원스텝 샘플링을 실현, 텍스트에서 이미지로의 확산 모델에서 매우 중요한 역할을 하는 변환 블록의 효율성을 개선하기 위해, 병목에서 자원 집약이 적은 UViT 아키텍처의 아이디어를 채용하여 UNet 아키텍처를 구축했다는 것.
MobileDiffusion의 UNet과 다른 여러 확산 모델의 UNet을 비교하면 다음 이미지와 같이, MobileDiffusion은 FLOPs(부동 소수점 연산)과 파라미터 수에서 뛰어난 효율을 보여줍니다. 또한 Google은 UNet 외에도 이미지 디코더도 최적화하고 있어 성능을 대폭 향상해 대기 시간을 50% 가까이 단축했다고 설명하고 있습니다.

DiffusionGAN의 원스텝 샘플링에 의해 실현된 MobileDiffusion으로 만들어진 이미지입니다. 최종적으로 모델은 5억 2000만의 콤팩트한 파라미터 수가 되어, 모바일 디바이스에서도 고품질이면서도 다양한 이미지를 생성할 수 있다고 합니다.

'AI · 인공지능 > 이미지 생성 AI' 카테고리의 다른 글
| 여러 장의 2D 이미지에서 3D 공간을 재현하는 「Toon3D」 (4) | 2024.05.21 |
|---|---|
| 그래픽카드 변경 없이도 이미지 생성 속도를 높여주는「Stable Diffusion WebUI Forge」설치 과정 (63) | 2024.03.08 |
| 배경이 투명한 이미지를 쉽게 생성할 수 있는 이미지 생성 AI「Layer Diffusion」리뷰 (78) | 2024.03.07 |
| Stability AI가 이미지에서 3D 모델을 생성할 수 있는「TripoSR」을 발표 (77) | 2024.03.06 |
| 고해상도 이미지를 0.5초 만에 생성하는 오픈 소스 AI 이미지 생성 모델 「PixArt-δ」가 등장 (91) | 2024.01.30 |
| 간단한 텍스트로부터 사실적인 동영상을 생성하는 확산 모델 「W.A.L.T」가 등장 (55) | 2023.12.13 |
| Meta가 이미지 생성 AI「Imagine」을 무료로 사용할 수 있는 웹 앱을 출시 (74) | 2023.12.08 |
| AI가 1장의 사진으로부터 고해상도 3DCG 모델을 생성해주는「Human-SGD」 (1) | 2023.11.27 |



