
대규모 언어 모델이나 이미지 생성 AI 등의 기계 학습 모델은 파인 튜닝이나 LoRA(Low Rank Adaptation) 등의 방법에 의해 모델의 가중치를 미세 조정하여 특정 태스크나 목적에 따른 출력을 실시하도록 커스터마이즈 할 수 있습니다. 홍콩 과기대학의 연구팀이 LoRA보다 계산 비용과 시간을 절약하는 새로운 방법 「DoRA(Weight-Decomposed Low-Rank Adaptation)」을 발표했습니다.
[2402.09353] DoRA: Weight-Decomposed Low-Rank Adaptation
https://arxiv.org/abs/2402.09353
DoRA: Weight-Decomposed Low-Rank Adaptation
Among the widely used parameter-efficient finetuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full
arxiv.org

Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch
https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch
Low-rank adaptation (LoRA) is a machine learning technique that modifies a pretrained model (for example, an LLM or vision transformer) to better suit a specific, often smaller, dataset by adjusting only a small, low-rank subset of the model's parameters.
magazine.sebastianraschka.com
완전히 사전 학습된 기계 학습 모델을 최적화하려면 는 입력값의 중요성을 수치화한 「가중치」의 파라미터 조정인 「파인 튜닝」을 실시할 필요가 있습니다. 그러나 일반 정밀 조정에서는 모델 내부의 가중치 매개변수를 모두 업데이트해야 하며, 매우 많은 시간이 걸리는 문제가 있습니다. 예를 들어, 대규모 언어 모델인 Lama 2-7B는 매개변수 수가 70억이지만 이 모든 것을 다시 학습시키는 것은 현실적이지 않습니다.
많은 대규모 언어 모델이나 이미지 생성 AI 등의 확산 모델에서는 Transformer라는 아키텍처를 채용하고 있습니다. 따라서 LoRA는 Transformer 계층별로 매개변수를 추가하여 기계 학습 모델의 재조정을 보다 신속하게 수행할 수 있습니다. LoRA는 일반 파인 튜닝보다 재조정하는 파라미터 수가 훨씬 적기 때문에, 파인 튜닝보다 VRAM 사용량이 적어 계산 비용도 줄일 수 있습니다.

이번에 발표된 DoRA는 사전 학습된 모델의 가중치 행렬 W를 스칼라 m과 인접 행렬 V로 분해하고 이 인접 행렬 V에 LoRA를 적용하는 방법입니다.
예를 들어 실제 2차원 벡터 [x, y]의 경우 벡터의 시작점을 데카르트 좌표의 원점에 놓으면 끝점의 좌표(x, y)가 벡터 성분이 되어 화살표의 방향과 크기를 표현할 수 있습니다. 동시에 화살표의 길이를 절대치 √(x2 + y2)로 화살표와 X정축의 각도를 θ로 놓았을 때 방향을 [cosθ, sinθ]로 나타낼 수 있습니다. 실 2차원 벡터[1, 2]이면 m=√5(약 2.24), V=[√5/5(약 0.447), 2√5/5(약 0.894)]로 나타냅니다.

이와 같이, 가중치 행렬 W를 mV로 분해한 후, 이 V에 LoRA를 적용, 즉 차분 ΔV를 더하는 것이 DoRA입니다. 수식으로 쓰면 조정 후의 가중치 행렬 W'=m(V+ΔV)가 되는 것입니다. 그러나 실제로 DoRA는 가중치 행렬을 분해하고 LoRA를 적용할 뿐만 아니라 2016년에 발표된 가중치 정규화도 수행합니다.
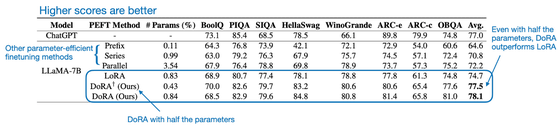
LoRA의 경우 성능을 최적화하기 위해 설정하는 "랭크 수"를 신중하게 결정해야 하지만 연구 팀에 따르면 DoRA는 LoRA보다 견고하며 낮은 순위 수에서도 LoRA보다 높은 성능을 보여준다는 것. 아래는 LLAMA-7B에 각각 DoRA(녹색)와 LoRA(회색)를 적용한 모델의 평균적인 정확성을 세로축으로, 랭크 수를 가로축으로 나타낸 그래프입니다. 두 랭크 수 모두 DoRA를 적용한 모델이 정확성에서 우월하다는 것을 알 수 있습니다.

또한 동일한 LAMA-7B에서 LoRA를 적용한 모델 (LoRA)와 그 절반의 랭크 수로 DoRA를 적용한 모델 (DoRA† (Ours))로 비교하면 성능의 평균 점수는 DoRA를 적용한 모델의 쪽이 위였다는 것. 즉, DoRA는 LoRA보다 저비용으로 높은 성능을 낼 수 있다고 연구팀은 주장하고 있습니다.
AI 관련 뉴스 사이트인 Ahead of AI는 실제로 Google의 대규모 언어 모델 Bert를 경량화한 DistilBERT로 DoRA를 적용한 결과 예측 정확도가 LoRA를 적용한 모델보다 1% 이상 향상되었다고 보고하였고, "DoRA는 LoRA를 논리적이고 효과적으로 확장한 유망한 기법인 것 같다."라고 논했습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| AI 조종으로 각광받는「프롬프트 엔지니어」가 벌써 사라질 위기? (65) | 2024.03.11 |
|---|---|
| Midjourney, ChatGPT Plus, DreamStudio, Image Creator는 41%의 비율로 가짜 선거이미지를 생성 (73) | 2024.03.08 |
| GPT-4를 뛰어넘는 성능으로 이미지와 문장을 동시에 처리할 수 있는 멀티모달 AI「Claude 3」출시 (71) | 2024.03.06 |
| OpenAI 지원 로봇 기업「1X」의 안드로이드가 세련된 동작으로 작업하는 영상 (82) | 2024.02.21 |
| Google이 AI로 파일 형식을 식별하는 도구 「Magika」를 오픈 소스로 공개 (81) | 2024.02.20 |
| 동영상을 보고 학습하는 아키텍처 「V-JEPA」를 Meta가 개발 (76) | 2024.02.20 |
| 중국에서 잇따라 AI 모델이 승인되고, 93조 규모의 AI 산업 시장으로 (111) | 2024.01.31 |
| Meta가 코드 생성 AI 모델의 새로운 버전 「Code Llama 70B」를 릴리스, 코드 정확성이 향상 (110) | 2024.01.31 |



