4줄 요약
- OpenAI가 초 고품질의 비디오 생성 모델 Sora 출시
- 이미지 생성 모델 Diffusion-Transformer 사용
- 동영상을 3차원 이미지로 취급하여 이미지 모델을 확장
- 캡션은 DALL • E3과 마찬가지로 캡션 생성 모델로 생성
OpenAI 소라
Sora는 OpenAI가 올해 2월에 발표한 동영상 생성 모델입니다. 먼저 이 모델의 출력 예를 살펴보겠습니다.

https://cdn.openai.com/sora/videos/big-sur.mp4
각 프레임의 이미지가 매우 아름답게 생성됩니다. 또한, 기존의 동영상 생성에서는 시간이 지났을 때에 찍혀 있는 오브젝트를 유지하는 것이 어렵고, 사라지거나 나타나거나, 갑자기 왜곡하는 것이 많았던 것에 비해, Sora에서는 한 번 사라졌다가 다시 나타나는 경우에도 불일치 없이 생성되고 있습니다.
이러한 동영상 생성 모델은 어떻게 만들어졌는가? 이 논문에서는 OpenAI가 발표 한 Sora의 기술 보고서를 바탕으로 자세히 살펴보겠습니다.
1. Sora에서 할 수 있는 것
Sora를 사용한 동영상 생성은 매우 확장성이 뛰어나므로 텍스트로 동영상을 생성하는 것 이외의 많은 작업이 가능합니다. 테크 블로그에서 예로 든 것이 아래의 다섯입니다.
- 첫 프레임의 이미지에서 동영상 생성
- 동영상을(시간적으로) 앞뒤로 확장
- 두 동영상을 원활하게 연결하는 중간 동영상 생성
- 동영상의 상황 변경
- 이미지 생성
이것 이외에도 화상 생성 모델로 가능한 조건부는 모두 가능하다고 생각됩니다.
2. 아키텍처의 전체 이미지
먼저 Sora의 전체 이미지를 간략하게 설명합니다.
동영상 압축 네트워크
Sora와는 별도로 비디오를 저 차원 잠재 공간으로 압축하는 엔코더와 잠재 공간에서 픽셀 공간으로 되돌리는 디코더를 학습하고 있습니다. Sora는 이 압축 모델의 출력을 사용하여 잠재 공간에서 생성을 학습합니다. 이것은 Stable Diffusion으로 대표되는 잠재 확산 모델과 같은 아이디어입니다.
시공간 패치
언어 모델에서 사용되는 Transformer의 프레임 워크에 탑재하기 위해 잠재 공간으로 압축된 동영상을 3차원 이미지로 캡처하여 시공간 패치로 구분합니다(그림 2에서는 이해를 위해 원래 동영상을 패치로 나누고 있습니다).

각 패치(그림 2의 블록)를 하나의 토큰으로 캡처하고, 확산 모델과 Transformer를 결합한 Diffusion-Transformer를 학습합니다.
우선 확산 모델인 Vision-Transformer에 대해 간략하게 설명한 다음 Diffusion-Transformer에 대해 설명합니다.
Diffusion-Transformer
확산 모델
확산 모델은 완성된 점토 피규어를 서서히 붕괴(해체)해 가는 단계(확산 과정)를 보는 것으로, 반대로 원 재료인 점토로부터 깨끗한 피규어를 만드는 방법(생성 과정)을 배울 수 있는 방법입니다. 예를 들면 점토의 꽃의 일부를 붕괴했다고 해서, 붕괴된 후의 점토와 붕괴 방법을 알면 원래의 꽃의 형태로 되돌릴 수 있습니다. 이러한 예를 대량으로 학습하면, 확산 모델은 붕괴 후의 형태로부터 어떻게 붕괴했는지를 예측해, 원래의 형태를 재현합니다.
이 모델은 생성 모델의 일종으로, 생성할 수 있는 대상은 이미지에 한정되지 않고, 음악이나 모션, 텍스트 등을 생성하는 연구도 있습니다.
확산 모델은 이미지에 작은 노이즈를 반복해서 추가하여 원래 정보를 완전히 잃은 상태로 붕괴시키는 확산 과정과 그 반대로 정보가 없는 상태에서 의미 있는 이미지를 생성하는 생성 과정(역확산 과정)의 두 프로세스로 구성됩니다.

(그림 3). 이후 설명을 위해 원본 이미지를 x0 라고 하고, 합계 T스텝에 걸쳐,
x0→ x1→ ⋯
확산 과정은 모델에 의존하지 않고 정해진 노이즈를 더하고 있으며, 이 과정에서 생성 과정을 학습합니다.
이때 더하는 노이즈로서 가장 자주 사용되는 것이 가우스 노이즈로, 다음 식과 같이 더합니다.

여기에서
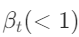
는 스텝 t로 가산되는
노이즈의 스케일을 조정하는 파라미터로 노이즈 스케줄링이라고 합니다.
노이즈 스케줄링은 작은 값으로 시작하여 단계별로 증가합니다.
이것은 위의 공식 데이터 항

가 서서히 0에 가까워지면서
노이즈가 지배적으로 됩니다.
위 식을 확률 밀도 함수를 사용하여 나타내면 다음 식과 같습니다.

이러한 전환에 대한 역방향 전환을 다음과 같이 모델링합니다.

이러한 확산 과정 및 생성 과정의 확률 밀도 함수로부터 모델에 의한 데이터 생성 확률
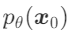
의 로그 우도의
변분 하한을 계산할 수 있으며, 이를 최대화하여 확산 모델을 학습할 수 있습니다.
Denoising Diffusion Probabilistic Models (DDPM)에서 모델의
공분산 행렬(임의의 주어진 벡터 혹은 확률변수의 각 원소들 사이의 공분산을 해당 위치에 채운 정사각행렬)은
등방적 입니다(방향에 상관없이 그 다양체의 모양(geometry)이 같다는 것).
즉,

라고 가정했습니다.
이러한 가정 하에서 평균 함수는 다음과 같은 함수형임을 나타낼 수 있습니다.
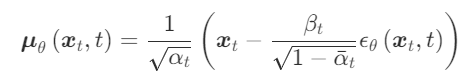
그리고 일부 항을 무시하면 확산 모델의 손실 함수는 다음과 같이 매우 간단한 형태가 됩니다.

여기에서 는 스텝 t에 이르기까지 가해지는 노이즈

DDPM에서는 이와 같이 가해진 노이즈를 예측하고 그 노이즈를 제거하여 점차 의미 있는 이미지를 생성합니다(그림 4).

위에서 DNN으로 표시된 노이즈를 예측하는 모델은 UNet(그림 5)을 사용합니다.

DDPM은 위에서 설명한 간단한 손실 함수로 학습함으로써
Fréchet Inception Distance (FID) 및 Inception Score (IS)와 같은
생성 품질을 평가하는 지표로 높은 성능을 발휘한다는 것을 보여주었습니다.
한편, 공분산(확률변수의 기댓값과 분산이 확률분포에 대한 정보를 주듯이 두 확률변수 사이에 정의된 공분산은 두 확률변수의 선형관계에 대한 정보를 알려 줌)이 등방적이라는 것은 강한 제약으로,
로그 우도가 낮아져 버리는 문제가 있습니다. 로그 우도를 높이는 것은 분포의 모든 모드를 포착하는 데 매우 중요하다는 것이 알려져 있으며, 최근의 연구에서는 로그 우도의 미세한 향상으로도 생성 품질에 크게 영향을 미치는 것으로 알려져 있습니다.
따라서 IDDPM은 DDPM처럼 단순화하지 않는 손실 함수를 사용합니다.
학습하는 것으로 이 문제를 해결하였습니다.
Vision-Transformer
Transformer는 자연언어 처리(NLP)의 맥락에서 제안된 모델로, Attention 이라는, 입력 계열 중에서 주목한 부분의 정보를 추출하는 것과 같은 파트를 풀로 활용한 모델입니다. 이 모델의 출현으로 NLP의 다양한 작업 성능이 획기적으로 향상되었습니다. 또한 ChatGPT로 대표되는 LLM(대규모 언어 모델)을 구성하는 주요 모듈도 Transformer입니다.
Vision-Transformer(ViT)는 이러한 NLP의 성공을 이미지에도 적용하고 싶다는 동기 부여에서 제안된 방법입니다. 그러나 텍스트 같은 정보와 이미지는 형식이 완전히 다릅니다. 따라서 다음 3단계로 Transformer에 대한 입력을 구성합니다.
- 패치라는 작은 영역으로 분해
- 각 패치의 이미지를 일렬로 늘려서 벡터로 처리
- 일렬로 늘린 벡터를 선형 변환
예를 들어 32 × 32 의 이미지로 종횡 4개씩 패치로 나누는 경우, 각 패치는 8 × 8의 이미지가 되어 늘어난 것은 64차원 벡터가 됩니다. 이 벡터에 대해 선형 변환한 것이 이미지 토큰의 임베딩이 되는 것입니다. 그림 6은 이것을 표현한 것입니다.

이후는 Transformer 와 같게, 위치 부호를 더해 입력합니다(그림 7).

Diffusion-Transformer
Diffusion-Transformer(DiT)에서는 IDDPM과 마찬가지로 학습합니다.
모델의 구조는 그림 8과 같습니다.

DDPM 이나 IDDPM 에서는, 화소의 공간에서 확산 모델을 학습하고 있었습니다만, DiT 에서는 Stable Diffusion 등으로 이용되는 Latent Diffusion 이라는 방법을 이용하고 있습니다.
Latent Diffusion에서는 이미지를 저 차원 벡터(잠재 벡터)로 변환하는 Encoder와 저차원 벡터에서 원래 이미지를 복원하는 Decoder를 사용합니다.
Encoder와 Decoder 자체는 확산 모델과는 별도로 학습된 VAE 등으로 확산 모델은 저차원 벡터의 공간(잠재 공간)에서의 생성을 학습합니다. 이를 통해 고해상도 고품질 생성이 가능해졌습니다.
DiT는 잠재적인 벡터 외에 시간(스텝) T의 정보나 텍스트 등의 조건부를 위한 정보를 입력합니다. 이러한 정보는 다층 퍼셉트론을 통해 ViT의 레이어 정규화 후의 스케일링이나 병행 이동으로서 이용됩니다.
조건부 방법은 이것 이외에도 시험하고 있는 것 같으므로, 원본 논문을 더 참고해 주세요.
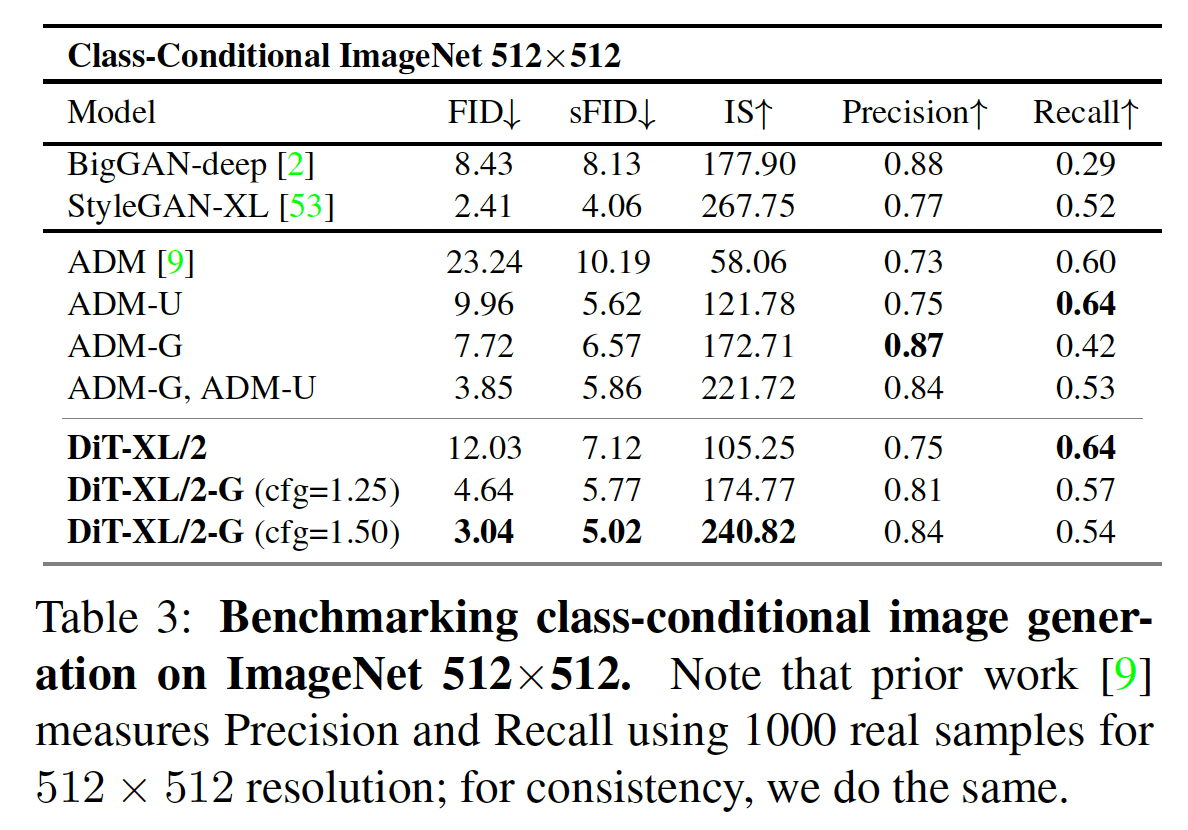
실험으로서는 ImageNet 데이터 세트에 대해서 클래스 라벨로 조건부 생성을 실시하고 있습니다. 이미지 크기는 시도하고 있습니다.
결과는 아래 표와 같이 FID 및 IS에서 최근의 SOTA 모델보다 유의미하게 성능이 높습니다.

생성된 이미지의 예시입니다.

그림에서 알 수 있듯이 Transformer의 크기를 늘리거나 패치 크기를 줄이는 것(패치 수를 늘리는 것) 모두 생성 품질에 기여합니다.
요약
DiT는 노이즈 예측을 UNet에서 ViT로 변경했고, Sora는 이미지를 시간 방향으로 확장한다는 것으로, 둘 다 단순한 아이디어에서 시작했습니다. 동영상 생성에 있어서 이번과 같이 매우 높은 퀄리티를 낼 수 있었던 요인은 모델을 대규모화한 것, 데이터를 대량으로 이용한 것이 전부라고 생각됩니다. 대규모 언어 모델에서도 그렇습니다만, 컴퓨터 비전에도 대규모화의 파도를 느꼈습니다.
동영상을 프롬프트로 취급하고 프레임 예측에 의해 깊이 추정이나 세그멘테이션 등의 다양한 태스크를 실시하는 방법도 제안되고 있습니다. 이러한 next frame prediction이라는 틀은 언어 모델의 next word prediction 과 대응합니다. 따라서 태스크에 대한 설명이나 예시를 이용한 In-Context Learning 이나 특정 태스크에 특화하기 위한 Instruction Tuning이 이미지 태스크에서도 가능하다고 생각됩니다.
언어 태스크의 대다수는 ChatGPT API를 통해 기계 학습을 전문으로 하지 않는 엔지니어에게도 널리 사용됩니다. Sora의 API가 공개되면 컴퓨터 비전 분야에서도 더 많은 사람들이 응용 프로그램을 쉽게 만들 수 있을 것입니다.
참고문헌
- T. Brooks et al. , “Video generation models as world simulators,” 2024, [Online]. Available: https://openai.com/research/video-generation-models-as-world-simulators
- J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” Adv. Neural Inf. Process. Syst. , vol. 33, pp. 6840–6851, 2020.
- AQ Nichol and P. Dhariwal, “Improved Denoising Diffusion Probabilistic Models,” in Proceedings of the 38th International Conference on Machine Learning , M. Meila and T. Zhang, Eds., in Proceedings of Machine Learning Research, vol. 139. 18-24 Jul 2021, pp. 8162-8171.
- A. Dosovitskiy et al. , “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” in International Conference on Learning Representations , 2021.
- W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2023, pp. 4195–4205.
- S. Yang et al. , “Video as the new language for real-world decision making,” Feb. 2024, [Online]. Available: https://openai.com/research/video-generation-models-as-world-simulators
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| 【2024년 최신판】모르면 손해하는 AI 모델이나 기술 10선 정리 (0) | 2024.04.29 |
|---|---|
| 오픈 소스 Sora가 왔습니다! 자신의 Sora 모델을 훈련합시다! (0) | 2024.04.29 |
| ChatGPT 등 수많은 고성능 AI를 낳은 구조 「Attention」 에 대한 상세한 해설 영상 (67) | 2024.04.17 |
| 멀티 모달 LLM의 활용 방법과 기술 해설 (0) | 2024.04.16 |
| 문과도 도전? 비즈니스 관점에서 본 프롬프트 엔지니어링 요약 (2) | 2023.08.01 |
| AI 기업의 엔지니어가 대규모 언어 모델과 RLHF를 알기 쉽게 해설 (3) | 2023.06.27 |
| ChatGPT를 사용하여 10년 만에 백만장자가 되는 공식, 「기업가로서의 청사진」 (6) | 2023.06.14 |
| Meta의 세분화 모델 Segment Anything Model(SAM) 논문 간단 리뷰 (0) | 2023.04.07 |



