
인터넷상에는 AI로 생성된 데이터가 넘쳐나고 있습니다만, 이것들을 트레이닝 데이터로서 이용해 버리면, AI 모델이 원래의 것을 망각해 버리는 「모델 붕괴」가 일어난다고 지적되고 있습니다.
AI models collapse when trained on recursively generated data | Nature
https://www.nature.com/articles/s41586-024-07566-y

Researchers find that AI-generated web content could make large language models less accurate - SiliconANGLE
https://siliconangle.com/2024/07/24/researchers-find-ai-generated-web-content-make-llms-less-accurate /
'Model collapse': Scientists warn against letting AI eat its own tail | TechCrunch
https://techcrunch.com/2024/07/24/model-collapse-scientists-warn-against-letting-ai-eatits -tail/
2024년 7월 25일 옥스포드 대학의 이리아 슈마이로프 씨가 이끄는 연구팀이 AI 모델은 '모델 붕괴'라는 현상에 근본적으로 취약하다는 논문을 학술지의 Nature에서 발표했습니다. 논문에 따르면 다른 AI 모델에 의해 생성된 데이터로부터 무차별적으로 학습하면 AI 모델은 "모델 붕괴"를 일으킨다고 한다. "모델 붕괴"는 시간이 지남에 따라 AI 모델이 기본 데이터 분포를 잊어버리는 퇴화 과정을 말합니다.
AI 모델의 본질은 패턴 매칭 시스템에 있습니다. 교육 데이터의 패턴을 학습하고 입력된 프롬프트를 패턴과 비교하여 가장 가능성이 높은 것을 출력합니다. '맛있는 스닉카드도르의 조리법은 무엇인가?'나 '취임시 연령순으로 미국 역대 대통령을 열거해 주세요'라는 질문이라도 기본적으로 AI 모델은 일련의 단어의 가장 가능성 높은 연속을 출력하기만 하면 됩니다.
그러나 AI 모델의 출력은 '가장 일반적인 것'에 끌린다는 특성을 가지고 있습니다. AI 모델은 '논란을 일으키는 스니카 두루의 레시피'가 아니라 '가장 인기있는 보통 레시피'를 답변으로 출력하기 쉽다는 것입니다. 이것은 이미지 생성 AI에서도 마찬가지입니다.

기사 작성 시점에서 인터넷에는 다양한 AI 생성 콘텐츠가 넘쳐나고 있기 때문에 새로운 AI 모델이 등장할 때는 AI 생성 콘텐츠를 교육 데이터로 활용할 가능성이 충분히 있습니다. 그러나 AI 모델이 앞서 언급했듯이 '가장 일반적인 것'을 출력하는 것을 고려하면 AI 생성 콘텐츠를 트레이닝 데이터로 활용한 새로운 AI 모델은 개의 90% 이상이 골든 리트리버라고 생각하도록 되어 버립니다. 이 사이클이 반복적으로 일어나면 AI 모델은 '개가 무엇인가'를 근본적으로 잊어버린다고 하는데 이것이 '모델 붕괴'라고 불리는 것입니다.
이 과정을 알기 쉽게 4 단계로 나누어 그림이 아래 그림입니다.
(a) 어느 AI 모델(AI 모델 1)을 트레이닝할 때에, 다양한 견종의 화상을 이용했다고 합니다.
(b) 이 AI 모델 1이 출력하는 "개 이미지"는 가장 많은 개 이미지로 트레이닝 데이터에 포함되어 있던 골든 리트리버의 이미지가 많아집니다.
(c) AI 모델 1이 출력한 "개 이미지"를 트레이닝 데이터로 한 새로운 AI 모델 (AI 모델 2)이 등장.
(d) 이 사이클을 반복해 나가면, AI 모델은 「개의 이미지」가 어떤 것인지를 잊어 버립니다.
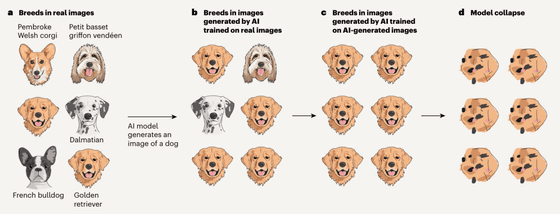
언어 모델이나 다른 모델조차도 기본적으로 AI 모델은 답변을 얻기 위해 교육 데이터 세트에서 가장 일반적인 데이터를 선호합니다. 따라서 AI 생성 콘텐츠가 교육 데이터로 활용되는 경우 모델 붕괴가 문제가 되는 것입니다.
기본적으로 AI 모델이 서로의 데이터로 트레이닝을 계속하면 눈치채지 못한 사이에 AI 모델이 어리석어져 가서 결국 붕괴해 버립니다. 연구팀은 복수의 완화책을 제시하고 있지만, 이론상은 「모델 붕괴를 피할 수 없다」라고 기록했습니다.

연구팀은 "웹에서 수집한 대규모 데이터세트에서 AI 모델을 교육하는 이점을 유지하려면 모델 붕괴 위기를 진지하게 받아들여야 합니다. 인터넷에서 수집한 데이터에 큰 규모 언어 모델(LLM)이 생성한 콘텐츠가 포함되어 있다는 점을 감안하면 시스템과 인간의 진정한 상호작용에 대해 수집된 데이터의 가치가 점점 높아지고 있습니다. 에 인터넷에서 수집된 데이터에 액세스하거나 인간이 대규모로 생성한 데이터에 직접 액세스하지 않고 새로운 LLM 버전을 교육하는 것은 점점 더 어려워질 수 있습니다. 있습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Stability AI가 1개의 동영상에서 다른 8개 앵글의 동영상을 생성하는 AI 모델 「Stable Video 4D」 를 발표 (1) | 2024.07.26 |
|---|---|
| 코드 생성 · 수학 · 추론 능력이 대폭 향상된 「Mistral Large 2」 출시 (1) | 2024.07.26 |
| 기계 학습으로 기존의 3500배 이상 빠르고 비용이 10만분의 1로 억제되는 기상 예측 모델 「NeuralGCM」을 Google Research가 공개 (0) | 2024.07.26 |
| OpenAI가 인간을 사용하지 않고 AI의 안전성을 높이는 방법 「Rule-Based Rewards(RBR)」를 개발 (0) | 2024.07.26 |
| AI를 개발하는 데 필요한 데이터가 급속히 고갈되고 단 1년만에 고품질 데이터의 1/4이 사용 불가 (0) | 2024.07.24 |
| 천문학자가 은하 측정 도구를 사용하여 AI가 만든 깊은 가짜를 구별하는 방법을 발명 (0) | 2024.07.24 |
| Mistral AI가 코드 생성 특화형 AI 「Codestral Mamba」 를 오픈 소스 라이센스로 출시 (1) | 2024.07.22 |
| 인간형 로봇이 운전을 하는 미래 (2) | 2024.06.26 |



