대기업 반도체 메이커이자 AI 연구에도 힘을 쏟고 있는 NVIDIA 가 새로운 이미지 생성 AI인 'eDiffi'를 발표했습니다. NVIDIA는 eDiffi가 전 세계에서 화제가 되고 있는 「Stable Diffusion」이나 OpenAI의 「DALL・E2」등 기존의 이미지 생성 AI보다 입력 텍스트에 충실한 이미지를 생성할 수 있다고 주장하고 있습니다.
[2211.01324] eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Large-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while condition
arxiv.org
eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers
eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers
eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers TL;DR: eDiff-I is a new generation of generative AI content creation tool that offers unprecedented text-to-image synthesis with instant style transfer and intuitive painting with wo
deepimagination.cc
Nvidia's eDiffi is an impressive alternative to DALL-E 2 or Stable Diffusion
THE DECODER
Artificial Intelligence is changing the world. THE DECODER brings you all the news about AI.
the-decoder.com
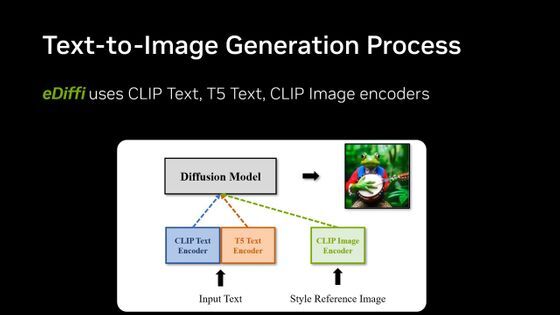
입력된 텍스트를 바탕으로 이미지를 생성하는 eDiffi에서는, Stable Diffusion이나 DALL·E2에서도 사용되고 있는「확산 모델」이라는 이미지 생성 프로세스를 사용하고 있습니다. 확산 모델은 노이즈뿐인 이미지에서 노이즈를 제거하는 과정을 반복하여 궁극적으로 깨끗한 이미지를 생성하는 방식으로 이미지를 생성합니다.
기존의 이미지 생성 AI와 eDiffi가 다른 점은
일반 이미지 생성 AI가 단일 노이즈 제거 모델(디노이저)로 트레이닝하고 있는 반면, eDiffi는 노이즈 제거 단계마다 다른 디노이저로 트레이닝합니다. 이로 인해 기존의 이미지 생성 AI보다 고정밀도의 이미지를 생성할 수 있습니다.
eDiffi의 이미지 생성이 얼마나 고정밀도인지는 아래의 영상을 보시면 알 수 있습니다.
아래는 왼쪽에서 "아름다운 나무들이 자라는 신비한 숲 속에 있는 포털을 매우 세밀하게 그린 디지털 페인트. 포털 앞에 사람이 서 있다", "유령의 집에서 고양이가 마법사 모자를 쓰고 마녀의 모습을 한 고화질의 줌 디지털 페인트. 아트 스테이션 (일러스트 투고 사이트)", "아름다운 바다 풍경의 이미지. 가라앉는다”라는 텍스트를 바탕으로 eDiffi가 생성한 이미지입니다. 모든 이미지는 품질이 높고 텍스트의 지시를 충실하게 반영합니다.
또, 텍스트에 의한 지시와 간단한 페인트에 의한 지시를 조합해, 마음대로 구도를 그려서 이미지를 생성할 수도 있습니다.
텍스트와는 별도로「화풍의 참고 이미지」를 지정하여, 좋아하는 화풍으로 이미지를 생성하는 것도 가능합니다.

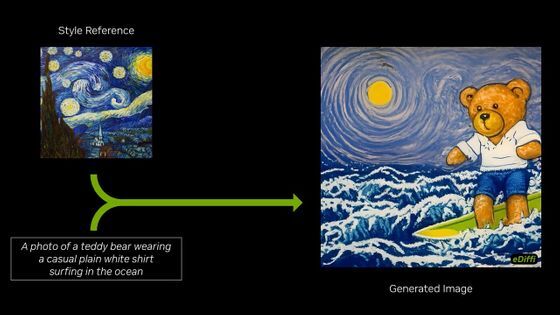
eDiffi는 기존의 이미지 생성 AI와 비교해 보다 텍스트의 지시에 충실한 이미지를 생성할 수 있다는 것.
아래는 "녹색 셔츠를 입은 골든 리트리버 강아지의 사진. 셔츠에는 'NVIDIA rocks'라는 텍스트가 적혀있다. 배경은 사무실. 4K, 디지털 SLR 카메라"라는 프롬프트 문구로 Stable Diffusion, DALL·E2, eDiffi가 생성한 이미지를 순서대로 늘어놓은 것입니다.
모두 골든 리트리버 강아지가 녹색 셔츠를 입고 있는 것까지는 재현할 수 있었습니다만,「NVIDIA rocks」라고 하는 문자가 정확하게 쓰여 있는 것은 eDiffi 뿐입니다.

"테이블 위에 2개의 중국 찻주전자가 있다. 한쪽에는 용의 그림이, 다른 한쪽에는 판다의 그림이 그려져 있다"라는 문구로 생성한 이미지는 다음과 같습니다. 이 경우에도 판다의 그림을 인식할 수 있는 것은 eDiffi 뿐입니다.

"파란 셔츠를 입은 개와 빨간 셔츠를 입은 고양이가 공원에 앉아있는 사진, DSLR 카메라"라는 텍스트로 시도한 결과, eDiffi 만이 파란색 셔츠를 입은 개를 재현하고 있다는 것을 알 수 있습니다.

eDiffi에서는 Google의 자연 언어 처리 모델인 T5(Text-to-Text Transfer Transformer) 와 이미지 분류 모델의 CLIP을 결합하여 이미지 스타일을 모방할 때는 옵션으로 CLIP 이미지 인코더를 사용한다는 것. T5만을 사용하면 올바르지 않은 오브젝트가 포함되는 경우가 있어, CLIP만으로는 세부가 누락되는 경우가 있다고 합니다만, 양자를 병용하는 것으로 최고의 퍼포먼스를 얻을 수 있다는 것을 알게 되었다고 NVIDIA는 해설하고 있습니다.