대규모 언어 모델의 학습에서는, 실제 인간에 의한 평가를 모델의 출력에 반영시키는 「Reinforcement Learning from Human Feedback(RLHF)」가 행해집니다. 그러나 RLHF는 인건비로 인한 비용이 많이 들거나 피드백을 회수하는 데 시간이 걸리는 등의 단점이 존재했습니다.
AlpacaFarm은 "인간이 어떤 평가를 돌려주는지"를 시뮬레이션함으로써 저렴하고 빠른 속도로 RLHF를 진행할 수 있는 도구입니다.
Stanford CRFM
https://crfm.stanford.edu/2023/05/22/alpaca-farm.html
Stanford CRFM
AlpacaFarm replicates the RLHF process at a fraction of the time (<24h) and cost ($<200), enabling the research community to advance instruction following research. Paper Code Release Overview Learning from instructions and human feedback are thought t
crfm.stanford.edu
(PDF)AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
https://tatsu-lab.github.io/alpaca_farm_paper.pdf
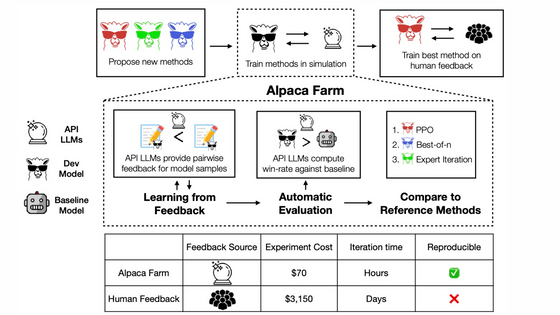
대규모 언어 모델 학습은 아래 그림과 같은 단계로 진행됩니다.
우선 대량의 텍스트로 모델을 트레이닝해 「Pretrained LLM」을 작성해, 다음에 본이 되는 데이터를 이용해 「지도 학습 파인 튜닝」을 실시해 「SFT 모델」을 작성합니다. 이에 더 정확도를 높일 때 사용되는 것이 RLHF입니다.

AlpacaFarm에는 "모델 응답에 평가 제공", "기준 모델과 새 모델의 비교 평가", "참조 구현과 비교 제공"이라는 세 가지 기능이 있습니다.

모델의 응답 평가 시 인간과 AlpacaFarm의 일치율은 아래 그림과 같습니다. 아래 그림은 기준이 되는 모델보다 평가 대상 모델의 응답이 뛰어나다고 판정되는 비율을 플롯 한 것으로, 이 그림을 보면 인간의 평가가 낮으면 AlpacaFarm의 시뮬레이션 평가도 낮아지고, 반대로 인간이 높이 평가한 모델은 AlpacaFarm도 높이 평가하고 있습니다. 실제 인간에게 평가받는 것에 비해 45분의 1의 비용으로, 매우 짧은 시간만에 동등한 평가를 얻을 수 있었습니다.

또한 AlpapaFarm에 의한 시뮬레이션에서는 실제 인간을 이용한 RLHF를 실시하는 경우와 마찬가지로 과잉 최적화 등의 현상이 발생합니다.
아래 그림의 왼쪽이 인간에 의한 RLHF로, 모델의 퍼포먼스가 상승한다고 RLHF를 계속하면 퍼포먼스가 오히려 내려가는 현상이 산(山) 모양의 그래프로 나타나고 있습니다. 가운데의 AlpacaFarm에 의한 RLHF에서도 동등한 현상이 재현되고 있어, 정확히 인간에 의한 평가와 동등한 평가를 돌려주고 있습니다. 우측의 GPT-4를 이용한 RLHF의 그래프는 우상향 그래프가 되어 재현에 실패하고 있습니다.

AlpacaFarm의 두 번째 기능인 모델끼리의 평가는, 복수의 공개 데이터 세트를 바탕으로 새로운 평가용 데이터 세트를 작성했다고 합니다. Alpaca 7B의 데모 버전이 공개되었을 때 모은 실제 사용 사례 데이터와 가능한 한 비슷한 세트가 되도록 조정했다고 합니다. 실제 사용 사례의 프롬프트와 새로운 평가용 프롬프트에서 Davinci003 모델과 RLHF 모델에 대한 응답을 생성하여 "어느 것이 높은 평가 응답을 생성할 수 있는지"를 시뮬레이션했습니다.
결과는 아래와 같으며, 기존에 공개된 데이터 세트를 재구성하니, 실제 행해지는 단순 명령의 퍼포먼스는 충분히 따라 할 수 있었습니다.

AlpacaFarm의 마지막 특징은 "PPO", "Best-of-n", "Expert Iteration"이라는 일반적인 학습 알고리즘 3개를 참조 구현으로 탑재하고 있다는 것입니다. AlpacaFarm 개발팀은 이 3가지 RLHF 모델의 승률을 다른 모델들과 비교했습니다. 그 결과, 인간에 의한 평가에서는 PPO가 ChatGPT를 웃도는 평가를 얻을 수 있었습니다.

덧붙여 이 실험에 이용된 코드는 GitHub에 공개되어 있습니다.
https://github.com/tatsu-lab/alpaca_farm
GitHub - tatsu-lab/alpaca_farm: A Simulation Framework for RLHF and alternatives.
A Simulation Framework for RLHF and alternatives. Contribute to tatsu-lab/alpaca_farm development by creating an account on GitHub.
github.com
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Microsoft가 차세대 AI 앱 개발을 지원하는 개발자용 대시보드 「Dev Home」 발표 (2) | 2023.05.25 |
|---|---|
| Microsoft가 자사 제품에 의한 모든 AI 아트에 워터마크를 넣겠다고 표명 (1) | 2023.05.25 |
| Google이 무료로 고퀄의 상품 이미지를 생성할 수 있는 AI 툴 「Product Studio」 발표 (2) | 2023.05.25 |
| 채팅 AI가 여친이 되어 음성 메시지나 셀카를 보내주는 'GirlfriendGPT' (2) | 2023.05.25 |
| 이미지 생성 AI나 ChatGPT 등의 제네레이티브 AI는 게임 개발 방식을 크게 바꾸고 있다 (2) | 2023.05.24 |
| OpenAI가 「초지능 AI」의 등장에 대비하기 위해 세계적인 규제 기관을 도입하자고 주장 (2) | 2023.05.24 |
| Intel이 초당 200경 회 계산하는 슈퍼컴을 사용해 1조 파라미터의 생성 AI를 개발 중 (2) | 2023.05.24 |
| Meta가 오픈소스 음성 인식 모델 「Massively Multilingual Speech(MMS)」를 발표 (2) | 2023.05.24 |



