
채팅 AI를 연구하고 있는 세바스챤 라슈카 씨가 채팅 AI가 실용화되기까지의 연구 궤적을, 주요 논문 24개를 추려 요약하고 있습니다.
Understanding Large Language Models - by Sebastian Raschka
Understanding Large Language Models
A Cross-Section of the Most Relevant Literature To Get Up to Speed
magazine.sebastianraschka.com
· 주요 아키텍처 및 작업
◆ 1 : Neural Machine Translation by Jointly Learning to Align and Translate (2014)
회귀형 신경망(RNN)에서 '입력의 어느 부분이 중요한가?'라는 '어텐션'을 도입하여 보다 긴 문장을 정확하게 다룰 수 있게 되었습니다.
◆ 2:Attention Is All You Need (2017)
인코더 부분과 디코더 부분으로 구성된 「트랜스포머」모델이 도입되었습니다. 이 논문에서는 위치입력 인코딩 등 현대의 기초가 되는 개념을 다수 도입하고 있습니다.
◆ 3 : On Layer Normalization in the Transformer Architecture (2020)
트랜스포머 모델의 「Norm」 레이어를 블록의 앞부분에 배치하는 것이 보다 효과적으로 기능한다는 것을 알아냈습니다.
◆ 4 : Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
1991년도에 이미 트랜스포머와 동등한 접근법이 검토되고 있었습니다. 라슈카는 "역사에 관심이 있는 사람들에게 추천합니다"라고 말합니다.
◆ 5 : Universal Language Model Fine-tuning for Text Classification (2018)
언어 모델을 사전 학습 & 파인 튜닝의 2 단계로 나누어 훈련함으로써 태스크를 잘 처리할 수 있음을 보여주었습니다. 이 논문은 트랜스포머 논문의 1년 후에 작성되었지만 트랜스포머가 아닌 일반 RNN에 초점을 맞추고 있습니다.
◆ 6 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)
엔코더와 디코더로 나뉘어 있다는 트랜스포머의 구조에 따라 연구 분야도 텍스트 분류 등을 하는 엔코더형 트랜스포머의 방향과 번역이나 요약 등을 하는 디코더형 트랜스포머의 2 방향으로 나뉘어 갔습니다.
BERT 논문에서는 문장의 일부를 가려 예측하는 기술이 도입되어 언어 모델이 문맥을 이해할 수 있게 되었습니다.

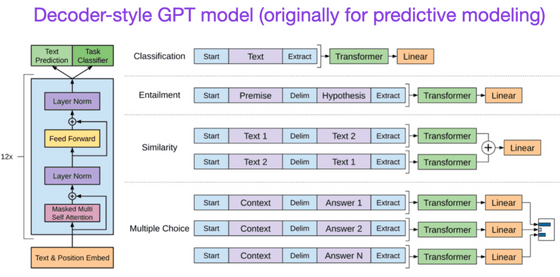
◆ 7:Improving Language Understanding by Generative Pre-Training (2018)
최초의 GPT의 논문입니다. 디코더형의 구조를 가지는 언어 모델을 「다음 단어를 예측」하는 방법으로 트레이닝했습니다.
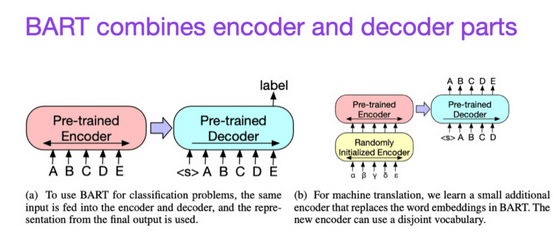
◆ 8 : BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019)
예측에 강한 인코더형 트랜스포머와 텍스트 생성에 강한 디코더형 트랜스포머를 조합해, 양쪽의 장점을 활용할 수 있도록 했습니다.
◆ 9:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (2023)
연구 논문이 아니고, 다양한 아키텍처가 어떻게 진화해 왔는지 조사하여 정리한 논문입니다. 오른쪽의 파란 가지로 표현된 것처럼, 특히 디코더형의 발전이 현저한 것을 알 수 있습니다.

· 스케일링 및 효율성 향상
◆ 10:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022)
어텐션의 계산을 고속으로 실시할 수 있게 되어, 메모리 소비량을 확 줄일 수 있는 훌륭한 알고리즘의 해설입니다.

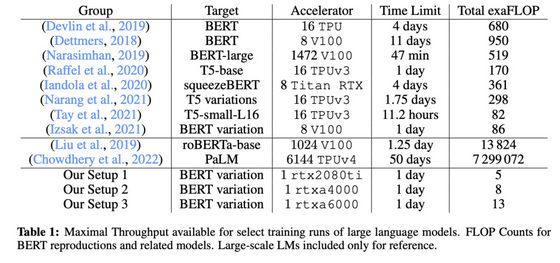
◆ 11 : Cramming: Training a Language Model on a Single GPU in One Day (2022)
작은 모델은 고속으로 트레이닝 가능하지만, 동시에 트레이닝의 효율도 떨어진다는 것을 알게 되었습니다. 역으로 말하면, 모델 크기를 늘려도 비슷한 시간에 훈련이 가능하다는 것입니다.
◆ 12:LoRA: Low-Rank Adaptation of Large Language Models (2021)
대규모 언어 모델을 파인 튜닝할 때의 기법은 다양합니다만, 그중에서도 파라미터 효율이 높은 방법이 「LoRA」입니다.

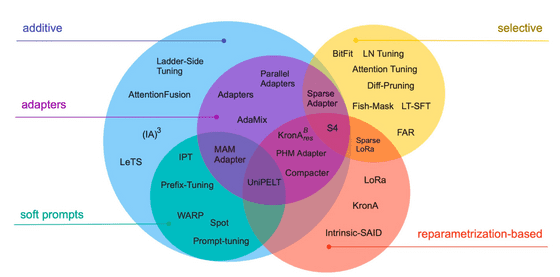
◆ 13:Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (2022)
사전 학습된 언어 모델은 다양한 작업을 잘 수행하지만, 그중에서도 특정 작업을 전문화하려면 미세 조정이 필요합니다. 이 논문에서는 정밀 튜닝을 효율적으로 수행하는 방법을 다수 검토합니다.
◆ 14 : Scaling Language Models: Methods, Analysis & Insights from Training Gopher (2022)
언어 모델의 파라미터 수를 늘렸을 때, 성능이 어떻게 향상되는지 확인해보면 '문장의 이해', '사실의 확인', '비속어의 식별'과 같은 작업이 잘 된다는 것을 알았습니다. 한편, 논리나 수학적 추론의 태스크 성적은 그다지 변하지 않았다고 합니다.

◆ 15 : Training Compute-Optimal Large Language Models (2022)
생성 태스크의 성적 향상에 대해 모델의 파라미터 수와 트레이닝 데이터 수의 새로운 관계를 알게 되었습니다. GPT-3이나 Gopher 등의 모델은 트레이닝 부족이라고 지적하고 있습니다.
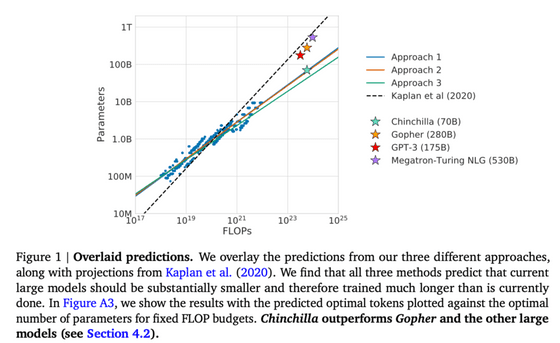
◆ 16:Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (2023)
트레이닝 과정에서 언어 모델이 어떻게 능력을 익혀가는지 연구했습니다.

이 논문에서는 아래의 내용도 보여줍니다.
・중복 데이터로 하는 트레이닝은 이익도 손해도 없음.
・트레이닝의 순서는 암기에 영향 없음.
・사전 트레이닝으로 여러 번 사용한 단어는 관련 태스크의 퍼포먼스가 좋아짐.
・배치 사이즈를 2배로 하면 트레이닝 시간은 반이 되지만 수렴에는 영향이 없음.
・언어 모델을 의도한 방향으로 유도
◆ 17:Training Language Models to Follow Instructions with Human Feedback (2022)
강화 학습 루프에 인간을 투입하여 「인간의 피드백에 의한 강화 학습(RLHF)」을 도입했습니다. 이 논문에서 사용된 언어 모델의 이름을 사용하여 InstructGPT 논문이라고 불립니다.

◆ 18:Constitutional AI: Harmlessness from AI Feedback (2022)
「무해」한 AI를 만들기 위해서, 룰에 근거하는 자가 트레이닝 메커니즘을 개발했습니다.

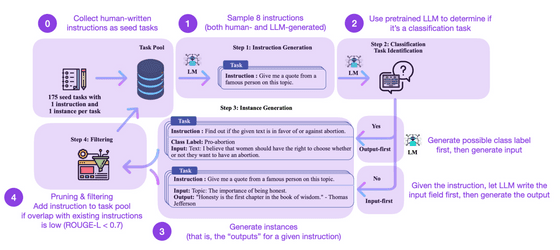
◆ 19:Self-Instruct: Aligning Language Model with Self Generated Instruction (2022)
언어 모델을 파인 튜닝할 때, 인간이 명령 데이터를 준비하면 스케일업이 어렵다는 문제가 있습니다. 이 논문에서는 명령 데이터 자체도 언어 모델에게 준비하도록 하는 구조가 기술되어 있습니다. 원래의 언어 모델이나 인간이 준비한 데이터로 훈련한 모델보다 성능이 좋아지지만, RLHF를 실시한 모델에는 진다는 것.
・인간의 피드백에 의한 강화 학습(RLHF)
RLHF는 2023년 5월 현재 사용 가능한 옵션 중에서 가장 우수한 것 같다고 라슈카는 말합니다. 앞으로도 한층 더 RLHF의 영향력이 높아질 것으로 라슈카씨는 전망하고 있기 때문에, 보다 RLHF에 대해 자세하게 학습하고 싶은 사람을 위해서 추가로 RLHF의 논문을 소개하고 있습니다.
◆ 20:Asynchronous Methods for Deep Reinforcement Learning(2016)
asynchronous gradient descent를 도입한 논문입니다.
◆ 21:Proximal Policy Optimization Algorithms(2017)
gradient descent를 개량해, 데이터 효율과 스케일링을 높인 Proximal Policy Optimization(PPO)를 개발했습니다.
◆ 22:Fine-Tuning Language Models from Human Preferences (2020)
RLHF에 PPO를 도입했습니다.
◆ 23:Learning to Summarize from Human Feedback (2022)
「사전 학습」→「파인 튜닝」→「PPO」라고 하는 3 스텝의 트레이닝으로 통상의 지도 학습보다 뛰어난 성적을 남기는 모델을 작성했습니다.

◆ 24:Training Language Models to Follow Instructions with Human Feedback (2022)
17번의 논문이 재등장했습니다. 위에서 설명한 것과 같은 3단계로 교육을 수행하지만 텍스트 요약 대신 텍스트 생성을 강조하고 평가 옵션 수를 늘리고 있습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 적은 GPU 메모리로 대규모 언어 모델을 트레이닝 하는 기법 「QLoRA」가 등장 (4) | 2023.06.07 |
|---|---|
| 「ChatGPT」로부터 대답을 잘 끌어내기 위한 OpenAI의 공식 가이드 (3) | 2023.06.07 |
| 요리 영상을 보는 것만으로 그 요리를 재현할 수 있는 「로봇 셰프」의 실험에 성공 (3) | 2023.06.07 |
| 오픈 소스로 상용 이용도 가능한 대규모 언어 모델 「Falcon」이 등장, 오픈 소스 모델 중 최고의 성능 (4) | 2023.06.07 |
| TikTok에서 살인사건 피해자가 자신의 최후를 말하는 영상이 증가 중 (3) | 2023.06.05 |
| AI 탑재 드론이 표적 파괴 작전 시뮬레이션에서 자신의 오퍼레이터를 살해 (4) | 2023.06.05 |
| 대화형 채팅 AI의 벤치마크 순위 공개, 1위는 GPT-4 (3) | 2023.06.04 |
| 명반 자켓을 Photoshop의 「제네레이티브 채우기」로 보완하면 어떻게 될까 (4) | 2023.06.02 |



