
Microsoft Research의 AI 연구팀이 Transformer 기반 모델 phi-1을 발표했습니다. 이 모델은 파라미터 수가 GPT-3.5의 100분의 1 이하인 13억 밖에 안되는데도 테스트용 데이터 세트 HumanEval에서 GPT-3.5를 웃도는 성적을 거둔 것으로 보고되었습니다.
[2306.11644] Textbooks Are All You Need
https://doi.org/10.48550/arXiv.2306.11644
Microsoft Releases 1.3 Bn Parameter Language Model, Outperforms LLaMa
Microsoft releases µTransfer, a new technique for hypertuning large neural networks
The total compute used to tune GPT-3 turned out to be a mere 7 per cent of the compute used to pretrain the model.
analyticsindiamag.com
다음은 phi-1 성능을 다른 모델과 비교한 것입니다. phi-1은 프로그래밍 능력을 평가하기 위한 데이터 세트인 HumanEval에서 50.6%, MBPP에서 55.5%로 높은 정확도를 보였습니다. 이 결과는 GPT-4의 67%에 이르지는 못했지만, 파라미터 수가 1,750억 인 GPT-3.5를 상회하는 것입니다.

phi-1이 얼마나 가벼운지, 논문의 저자 중 한 명인 세바스티안 뷰벡은 "다른 HumanEval 50%를 초과하는 모델은 1,000배나 큽니다. 예를 들면, WizardCoder는 모델 크기는 10배, 데이터 세트 크기는 100배였습니다."라고 트윗.
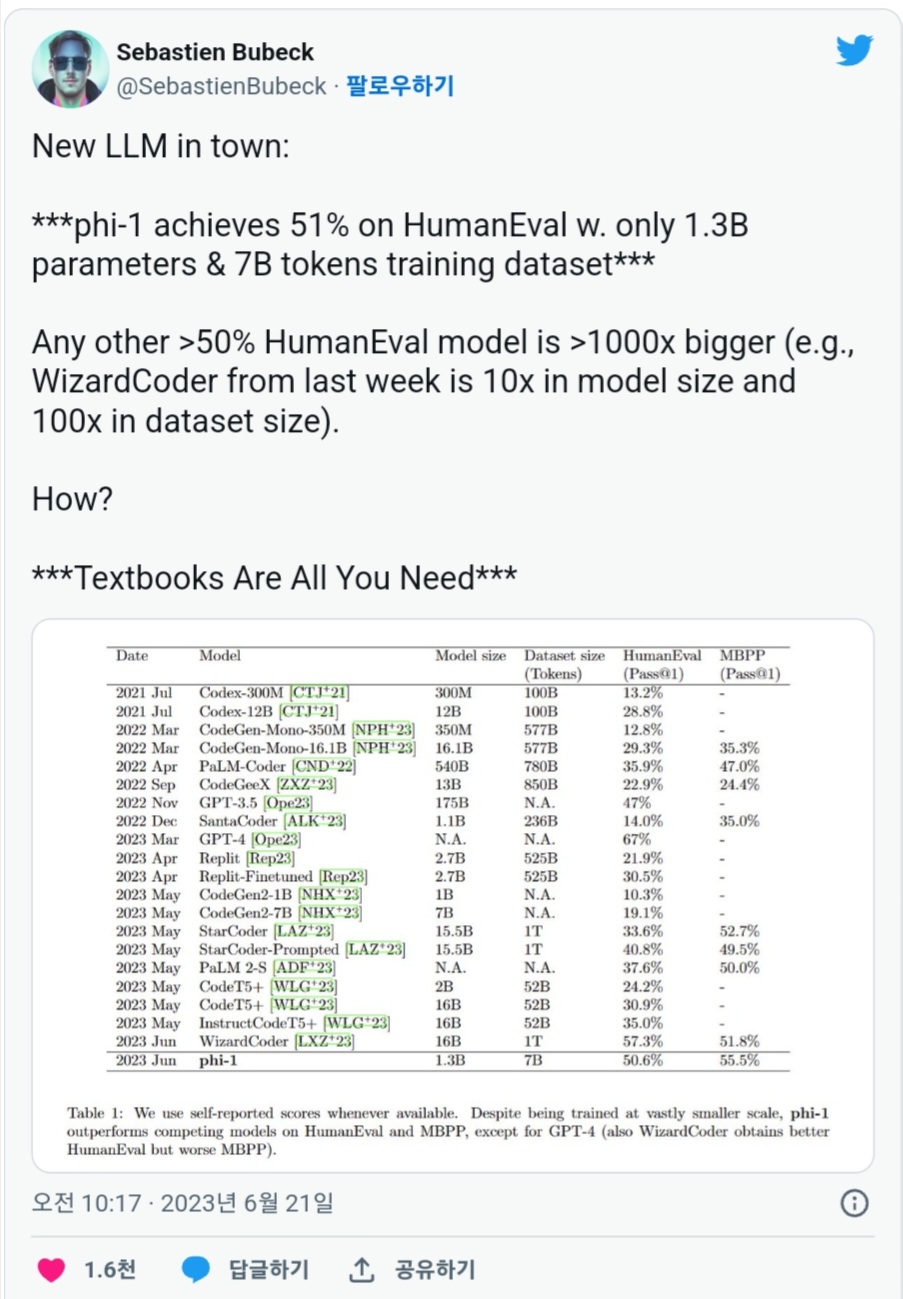
Textbooks Are All You Need(네게 필요한 것은 오직 교과서)라는 제목의 논문에 따르면, 이 모델은 인터넷에서 수집된 교과서급 품질의 데이터 세트 60억 토큰과 GPT-3.5로 생성된 교과서급 데이터 세트 10억 토큰을 사용해, 8대의 NVIDIA A100 만으로 불과 4일간의 트레이닝으로 만들어졌다고 합니다.
특징 있는 위 논문의 제목은 Transformer 모델의 기초를 세운 논문 "Attention Is All You Need(네게 필요한 것은 오직 어텐션)"에서 비롯된 것으로 여겨집니다.
연구팀은 또한 phi-1과 같은 파이프라인으로 훈련된 더 작은 모델 phi-1-small을 개발하고 있습니다. phi-1-small은 파라미터 수가 3억 5천만으로 더 적음에도 불구하고 HumanEval에서 45%를 달성했습니다.
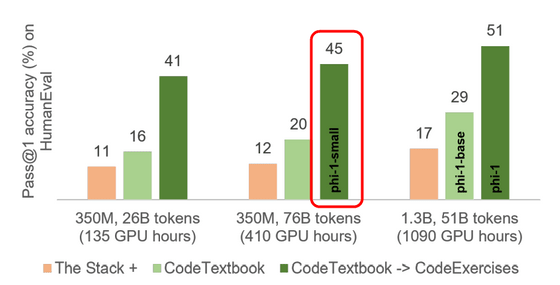
공동 저자인 로넨 엘던은 "코딩에 교과서급 품질 교육 데이터를 사용하자, 예상 밖의 결과를 얻었다."라고 말하고 있습니다. 또한, 에르단 씨에 의하면 phi-1은 곧 AI 플랫폼·Hugging Face에서 이용할 수 있게 될 것이라고 합니다.

이 논문을 다룬 소셜 뉴스 사이트인 Hacker News의 스레드에서 "GPT에 의해 생성된 고품질의 합성 데이터 세트가 없었다면 불가능했다."라고 지적받은 대로, phi-1의 중요성은 「모델 사이즈를 크게 하는 대신, 질을 향상함으로써 고성능의 모델을 얻을 수 있다」라는 점에 있습니다. 예를 들어, GPT-4와 새로운 대항마로 눈에 띄는 오픈 소스 모델 Orca는 파라미터 수가 130억으로 비교적 경량이지만, GPT-4 데이터로 학습함으로써 OpenAI 제품을 넘는 벤치마크 결과를 보였습니다.
한편, AI가 생성한 정보를 AI 학습에 이용하는 기법에는 우려도 제기되고 있습니다. 2023년 5월에 arXiv에서 공개된 논문 「The Curse of Recursion(재귀의 저주)」에서는, 다른 LLM 데이터로 학습함으로써 발생하는 「데이터 포이즈닝」에 의해, 새로운 모델의 정밀도가 저하되는 것이 나타났습니다. ChatGPT와 같은 독점적인, 즉 비공개 강력 모델의 출력으로 약한 모델을 미세 조정하는 것의 폐해는 "The False Promise of Imitating Proprietary LLMs(독점 LLM을 모방하려는 거짓된 약속)"이라고 불리고 있습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 엔비디아 CEO, "AI에 익숙해지지 않으면 개인도 기업도 이길 수 없다." (2) | 2023.06.27 |
|---|---|
| GPT와 매일 대화중인 손정의, 눈앞의 손익에 얽매이지 않고 AI 투자를 추진 (4) | 2023.06.26 |
| 전자 워터마크로 AI 이미지를 추적하는 기술 「Tree-Ring Watermarks」 (2) | 2023.06.26 |
| 마블의 최신 드라마인 「시크릿 인베이젼」은 AI로 오프닝 영상을 작성했다 (2) | 2023.06.23 |
| 최대 24배 빠른 대규모 언어 모델 라이브러리 「vLLM」의 등장과 PagedAttention 구조 (2) | 2023.06.23 |
| AI의 등장으로 컴퓨터의 UI는 '제3의 패러다임'으로 이동 (2) | 2023.06.22 |
| 메르세데스 벤츠가 ChatGPT를 시험적으로 탑재, 90만대 이상의 차로 실증 실험 (2) | 2023.06.22 |
| 10만 건이 넘는 ChatGPT 계정이 도난당해 다크웹에서 거래되고 있는 것으로 판명, 기업 기밀정보 유출 위험 (2) | 2023.06.22 |



