
2023년 2월 13일, Stability AI가 텍스트로부터 이미지를 생성하는 새로운 모델「Stable Cascade」를 발표했습니다. 이 모델은 비상용 라이센스로 출시되었습니다.
고품질의 이미지를 고속으로 생성하는 이 모델은 3가지 다른 모델(스테이지 A, B, C)로 구성된 파이프라인으로 구축됩니다. 이 3단계의 접근법으로 인하여 일반 소비자용의 저사양 하드웨어에서도 트레이닝과 파인 튜닝이 가능해지고 있습니다.
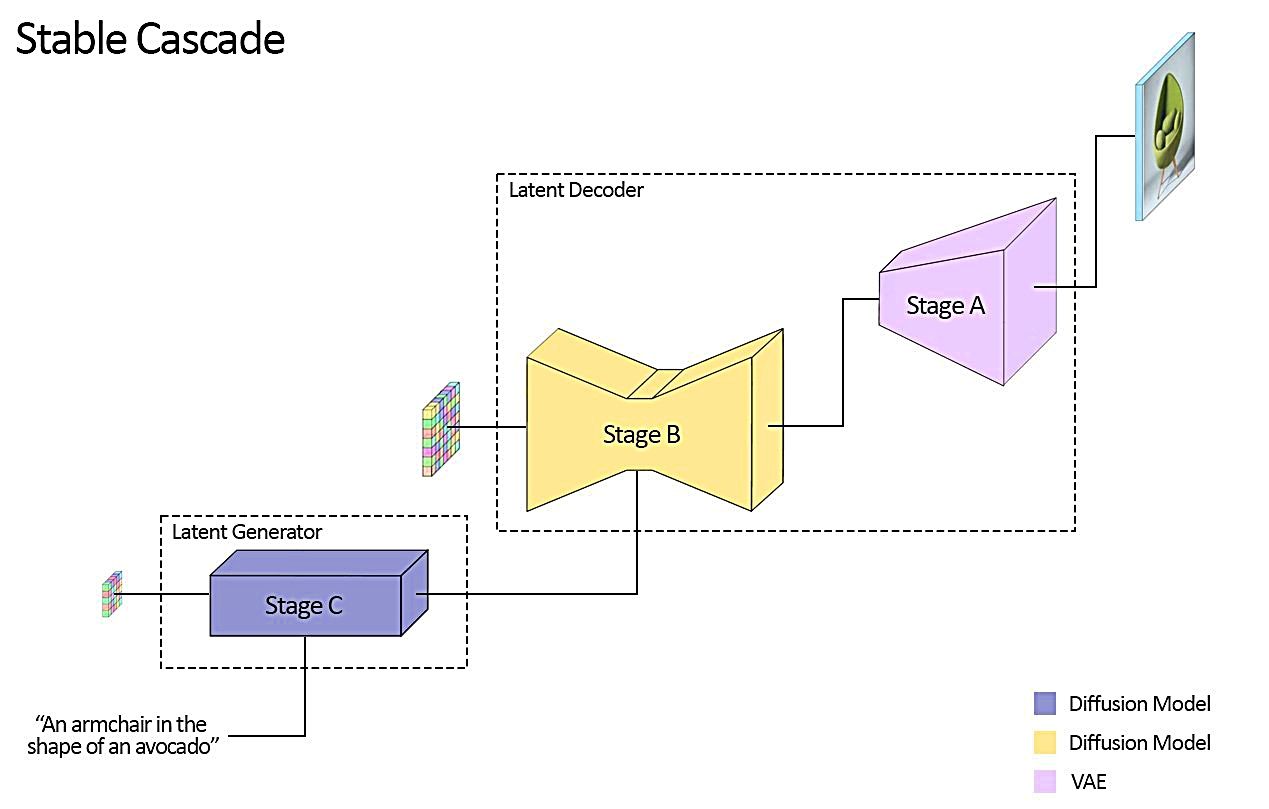
Stable Cascade의 기초 역할을 하는「Würstchen」아키텍처는 이미지의 계층적 압축을 가능하게 하고, 고도로 압축된 잠재 영역을 이용하면서 효율적인 추론과 저비용 트레이닝을 가능하게 합니다. 3단계 모델의 각 스테이지는 다른 파라미터 사이즈를 가지며, 이미지 생성의 정밀도 및 세부의 재구성능력이 우수하다고 합니다.
스테이지 C(Latent Generator Phase : 잠재 생성기 단계)는 사용자 입력을 24 x 24의 콤팩트한 잠재 영역으로 변환합니다. 이 스테이지에서의 텍스트 조건 생성을, 고해상도 픽셀 공간(스테이지 A · B)으로의 디코드로부터 분리해, ControlNets나 LoRA를 포함한 추가 학습이나 파인 튜닝을 이 스테이지 C만으로 완결시킵니다.
그 후, 이미지의 압축에 사용되는 스테이지 A · B(Latent Decoder Phase : 잠재 복호화 단계)에 건네져, 높은 압축률을 달성합니다.
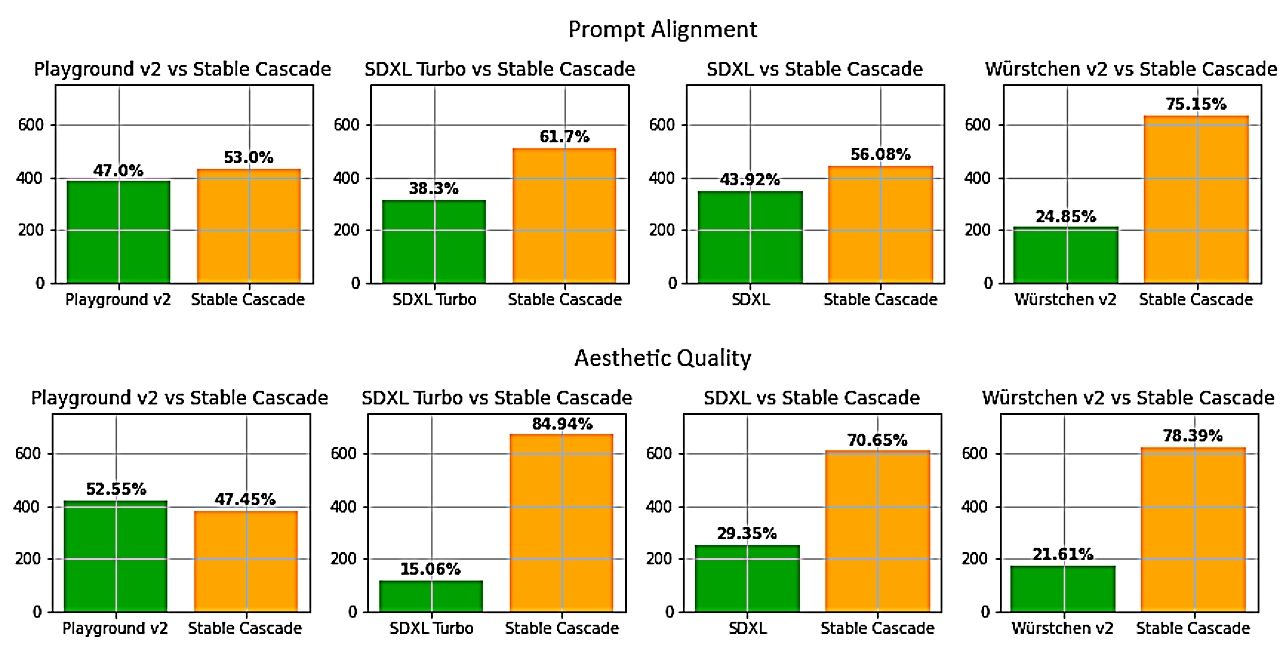
Stability AI에 의하면, 프롬프트의 얼라인먼트와 미적 품질의 양쪽에 있어서는, 거의 모든 모델 비교에서 Stable Cascade 쪽이 뛰어났다고 합니다.
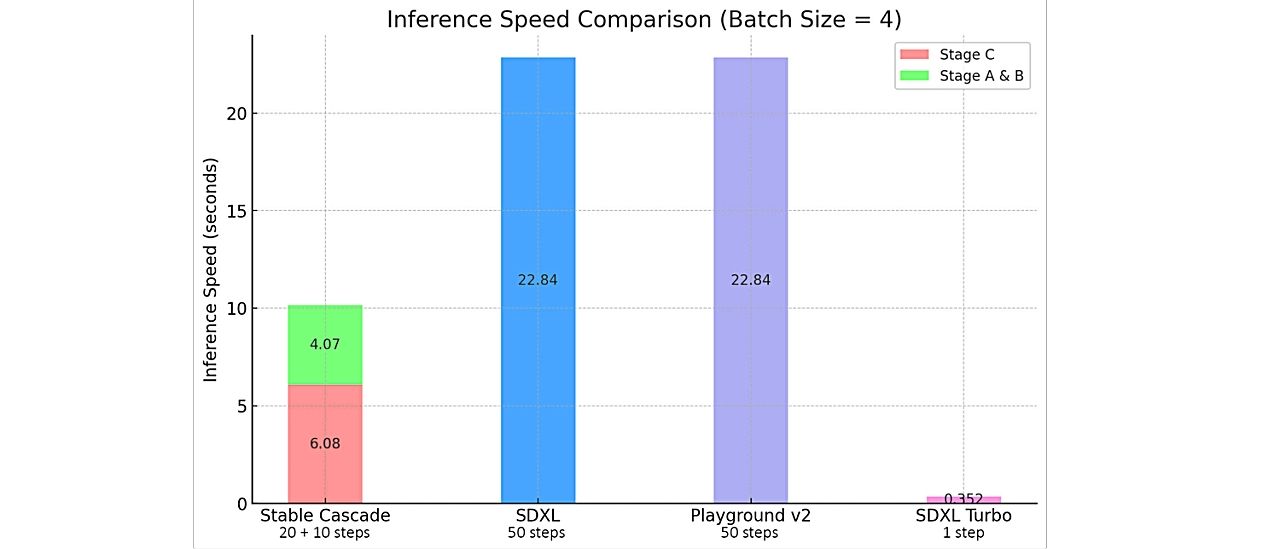
추론 속도를 비교하는 그래프 (StableCascade는 SDXL 모델 대비 절반의 시간만 사용)
Stable Cascade가 출시됨에 따라 Training, Fine Tuning, ControlNet 및 LoRA의 모든 코드가 StabilityAI GitHub에 게시되었습니다.
https://github.com/Stability-AI/StableCascade
GitHub - Stability-AI/StableCascade: Official Code for Stable Cascade
Official Code for Stable Cascade. Contribute to Stability-AI/StableCascade development by creating an account on GitHub.
github.com
Text to Image에 더하여, 이미지에 Variation을 더하는 기능이나, Image to Image 등이 소개되고 있습니다.
· Variation(왼쪽이 원본 이미지) : 주어진 이미지에서 이미지 임베딩을 추출하고 모델로 되돌리는 기능.

· Image to Image : 주어진 이미지에 노이즈를 추가하여 이미지 생성의 시작점으로 사용하는 기능.

그 외, 릴리즈 예정인 ControlNet의 일부가 소개되고 있습니다.
· 인 페인팅 / 아웃 페인팅 : 텍스트 프롬프트에 따라 마스킹된 부분을 생성된 이미지로 채웁니다.

· 캐니 엣지 : 엣지(윤곽)를 따라 새로운 이미지를 생성합니다. 스케치를 바탕으로 전개하는 것도 가능.

・2배 초해상 : 스테이지 C에서 생성된 Latent Space(잠재 영역)에도 사용 가능.

'AI · 인공지능 > 이미지 생성 AI' 카테고리의 다른 글
| Stability AI가 이미지에서 3D 모델을 생성할 수 있는「TripoSR」을 발표 (77) | 2024.03.06 |
|---|---|
| 사진이나 일러스트가 노래하도록 하거나 말하게 하는 AI 시스템 「EMO」가 등장 (76) | 2024.03.04 |
| Stable Diffusion XL이 「SDXL-Lightning」의 데모를 공개 (75) | 2024.02.28 |
| Stability AI가 고화질 이미지 생성 AI 「Stable Diffusion 3」를 발표 (85) | 2024.02.26 |
| Google이 스마트폰을 사용해 0.5초만에 이미지를 생성하는「MobileDiffusion」을 발표 (114) | 2024.02.02 |
| 고해상도 이미지를 0.5초 만에 생성하는 오픈 소스 AI 이미지 생성 모델 「PixArt-δ」가 등장 (91) | 2024.01.30 |
| Google이 초 고품질의 동영상 생성 AI 「Lumiere」를 발표 (108) | 2024.01.26 |
| TikTok의 모회사 ByteDance가 텍스트로 고품질 동영상을 생성하는 AI「MagicVideo-V2」발표 (91) | 2024.01.22 |



