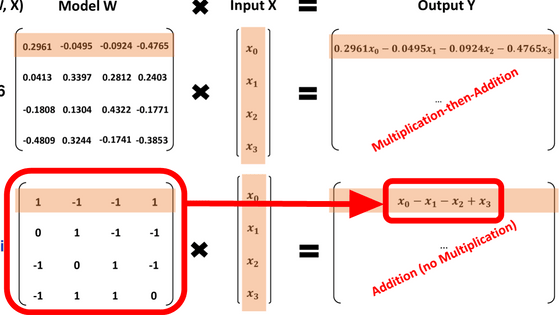
마이크로소프트의 연구팀이 모델의 가중치를 「-1」,「0」,「1」의 세 가지 값만으로 함으로써 대규모 언어 모델의 계산 비용을 급감시키는 데 성공했다고 발표했습니다.
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
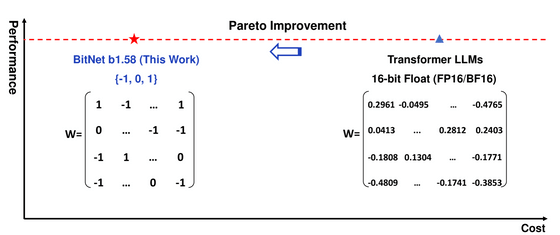
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It ma
arxiv.org
기존 모델이라면 입력에 '0.2961' 등의 가중치를 곱한 다음 더하고 빼야 했지만, 「-1」,「0」,「1」의 3 값만 있으면 곱셈 없이 모든 계산을 더하여 계산할 수 있습니다.
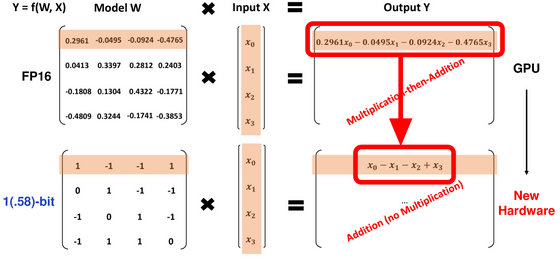
따라서 동일한 성능을 내는 데 필요한 비용이 일반 대규모 언어 모델에 비해 급감한다는 것. 또한, 각각의 파라미터가 「-1」,「0」,「1」이라는 3개의 값을 취하기 때문에 log[2](3)의 값으로 인해 「1.58비트의 모델」이라고 명명되고 있습니다.
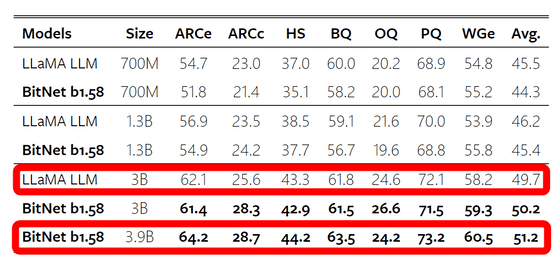
다양한 벤치마크에서 학습 데이터에 포함되지 않은 데이터를 처리시키는, 소위 제로 샷의 성능을 LLaMA와 비교한 결과는 아래 그림과 같습니다. 같은 사이즈의 LLaMA에 대해서 BitNet은 성능면에서 동등 이하가 되고 있습니다만, LLAMA의 3B모델에 대해서 BitNet의 3.9B모델은 대부분의 지표를 웃도는 등, 모델 사이즈를 조금 크게 하는 것으로 기존의 성능을 유지할 수 있음을 시사하고 있습니다.
성능면에서는 좋은 승부라고 할 수 있었습니다만, 필요한 메모리 양이나 레이턴시에 있어서는 BitNet의 압승입니다. LLaMA의 3B 모델에 비해 BitNet의 3.9B 모델은 필요한 메모리 양이 3.32분의 1, 대기 시간은 2.4분의 1로 크게 감소하고 있습니다.
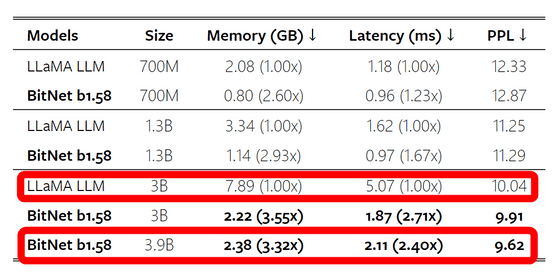
레이턴시와 메모리 소비량의 차이는 모델의 크기가 커질수록 벌어지고, 70B 모델끼리의 비교에서는 BitNet의 레이턴시는 LLAMA의 4.1분의 1로 메모리 소비량은 7.16의 1까지 줄일 수 있다는 것.
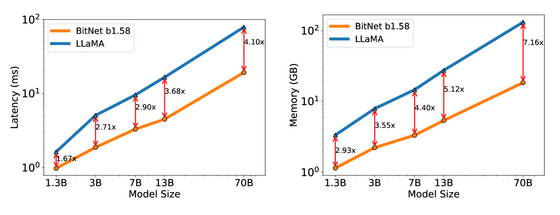
또한 행렬 연산의 비용이 71.4분의 1로 격감하고 있으며, BitNet은 총 에너지 소비량을 70B 모델로 LLAMA의 41.2분의 1로 줄이는 데 성공하고 있습니다.
배치 사이즈는 11배, 처리량은 8.9배로 향상.

2조 토큰을 사용한 훈련 후의 벤치마크는 아래 그림과 같이 1.58비트 모델에서도 강력한 일반화 능력이 있음이 확인되었습니다.

이번 기법을 이용함으로써 행렬 연산에 필요한 곱셈의 양을 대폭 줄일 수 있기 때문에, 논문에서는 「1bit의 대규모 언어 모델용 새로운 하드웨어 설계로의 문을 열었다」라고 말하고 있습니다.
아니, 이건 너무 급진적이잖아...
거 기술 변화가 너무 심한 거 아니오?

'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Midjourney, ChatGPT Plus, DreamStudio, Image Creator는 41%의 비율로 가짜 선거이미지를 생성 (73) | 2024.03.08 |
|---|---|
| GPT-4를 뛰어넘는 성능으로 이미지와 문장을 동시에 처리할 수 있는 멀티모달 AI「Claude 3」출시 (71) | 2024.03.06 |
| AI에게「스타 트렉의 선장이 되어라」라고 지시하면 더 나은 성능을 발휘하는 것을 발견 (77) | 2024.03.05 |
| ChatGPT 등 채팅 AI의 보안 기능을 파괴하는 멀웨어 「Morris II」가 등장 (4) | 2024.03.05 |
| LLM의 동작을 Excel에서 완벽 재현하여 AI 구조를 학습하는 시트가 등장 (71) | 2024.03.04 |
| AI가 이미지 설명을 자동으로 생성 (89) | 2024.02.29 |
| Microsoft가 생성 AI의 허점을 테스트하는 툴「PyRIT」을 발표 (82) | 2024.02.28 |
| NVIDIA의 CEO가 "AI 때문에 더 이상 프로그래밍을 배울 필요가 없다"고 말하여 논쟁 (77) | 2024.02.28 |



