
3 개의 요점
✔️ 다양한 분야에서 사용되는 'GAN'의 포괄적인 조사 논문 소개
✔️ GAN의 품질을 측정하는 지표 및 다양한 응용을 소개
✔️ GAN을 어디에 적용할 수 있는지 포괄적으로 파악이 가능
A Review on Generative Adversarial Networks : Algorithms, Theory, and Applications
written by Jie Gui, Zhenan Sun, Yonggang Wen, Dacheng Tao, Jieping Ye
(Submitted on 20 Jan 2020)
subjects : Computer Vision and Pattern Recognition (cs.CV) ; Machine Learning (cs.LG)
시작하기
이번에는는 GAN의 서베이 논문(알고리즘 편)에 이어 생성된 이미지의 품질을 측정하는 지표와 GAN의 응용을 소개합니다.
GAN의 발전의 역사( 알고리즘 편 )
3개의 요점 ✔️ 다양한 분야에서 사용되는 GAN의 포괄적인 조사 논문 소개 ✔️ GAN의 알고리즘에 초점을 맞춘 다양한 접근 방식을 소개 ✔️ GAN의 최신 동향 A Review on Generative Adversarial Networks : A.
doooob.tistory.com
GAN이 생성하는 이미지를 어떻게 평가할지는 아직도 어려운 문제로 알려져 있습니다. 모드 붕괴를 어떻게 파악할 것인가, 과적합을 어떻게 감지할지 등 현재 제안되고 있는 지표 만으로는 측정이 어렵다고 되어 있습니다. 그러나 현재 어떤 지표가 일반적으로 사용되고 있는지를 아는 것은 중요합니다.
또한 GAN은 이미지 생성을 위해 태어난 알고리즘이지만, 현재는 다양한 분야에서 GAN의 개념을 응용한 연구가 발표되고 있습니다. 아래의 내용을 통해 어떤 응용이 있는지 파악하여 주시면 감사하겠습니다.
GAN의 성능을 측정하는 지표
Inception Score (IS)
IS는 생성된 이미지의 품질과 다양성을 측정하는 대표적인 방법 중 하나입니다. 정의는 다음과 같습니다.

즉, IS는p(y)의 차이를 KL발산으로 측정하여 두 분포가 크게 다르면 커지는 지표입니다.
이것은 이미지 분류 모델에 생성 이미지를 입력했을 때, 높은 확률로 클래스 i라고 예측되면, 생성 이미지가 실제 이미지와 비슷하다고 할 수 있습니다. 이것은 p(y|x)로 측정이 가능합니다.
또한, p(y|x)를 x로 적분한 p(y)가 평등한 분포이면 생성된 이미지가 다양성을 가지고 있다고 말할 수 있습니다. 이 두 가지 관점에서 생성 이미지를 평가하는 것이 IS입니다.
FID
IS는 실제 이미지를 고려하지 않는다는 단점이 있습니다. 그것을 개선하기 위해 고안된 지표가 FID입니다. FID는 분류 모델에 따라 실제 이미지와 생성 이미지에서 특징량을 추출합니다. 그들이 정규 분포를 따른다고 가정하고 그 분포 사이의 거리를 측정합니다. 정의식은 다음과 같습니다.

여기서, μr 및 Cr은 각각 실제 이미지에서 추출된 특징량의 평균과 공동 분산이고, μg와 Cg는 각각 생성 이미지에서 추출된 특징량의 평균과 공동 분산입니다.
MS-SSIM
Multi-scale structural similarity(MS-SSIM)는 이미지의 유사도를 측정하는 지표이며, 학습한 GAN이 모드 붕괴하고 있는지, 이 지표를 이용하여 파악할 수 있습니다. MS-SSIM의 정의식은 다음과 같습니다.

여기에서 y는 각각 비교하고싶은 이미지, l(x,y)는 이미지 사이의 픽셀 값의 변화, c(x,y)는 이미지 사이의 콘트라스트의 변화, s(x,y)는 이미지 사이의 상관 계수를 나타냅니다.
이름에도 있듯이 MS-SSIM은 이미지 사이의 변화를 다른 스케일로 측정하는 지표입니다. 즉, MS-SSIM는 이미지를 흐리게하고 있고, 각각의 스케일 j의 이미지에 대하여 를 계산합니다. 또한, 스케일 M의 이미지에 대해서만 계산합니다. 이것을 나타낸 것이 아래 그림입니다.

아래 그림은 MS-SSIM에 따라 이미지 사이의 유사도를 계산한 예입니다.

MS-SSIM의 값이 작을수록 이미지 사이의 유사성이 작고, 생성한 이미지에 다양성이 존재한다는 것을 보여줍니다.
GAN의 응용
여기서부터는 GAN 그 자체, 또는 GAN의 개념을 응용한 연구를 소개합니다.
반 감독 학습
GAN은 반 감독 학습에 잘 사용됩니다. SGAN은 GAN을 확장하여 이미지 분류의 반 감독 학습에 적응한 것입니다.
일반적인 GAN은 식별기(이하 D)에서 0~1의 값을 가지고 있지만 SGAN의 D는 분류기+1의 차원을 가집니다. 마지막 차원은 생성된 이미지가 가짜라는 것을 의미하는 클래스입니다.
즉, 생성기(이하 G)에 의해 생성된 이미지가 어떤 클래스에 속한 것인지 D에 의해 식별되고, 클래스 i로 분류되면, 그것을 학습 데이터로 사용합니다. 라벨이 붙은 실제 이미지와 라벨 없이 생성된 이미지를 사용하고 있다는 점에서 반 감독 학습이라 할 수 있겠습니다.
도메인 적응
도메인 적응은 학습 데이터(소스)와 테스트 데이터(대상)의 분포에 차이가 있는 경우에 사용되는 기술입니다. 예를 들어, 학습 데이터는 낮에 찍힌 사진이고 테스트 데이터는 야간에 찍힌 사진일 때, 데이터 사이의 분포에 차이가 있습니다. 이 격차를 줄여주는 방법이 도메인 적응 기술입니다.
ADDA는 GAN을 도메인 적응에 응용 한 방법입니다. 아래의 그림은 ADDA의 개요 그림입니다.

ADDA는 먼저 원본 도메인의 데이터로 Source CNN을 학습합니다. 다음은 Source CNN의 파라미터로 초기화한 Target CNN을 준비하고, D는 소스에서 추출된 특징량인지, 대상에서 추출된 특징량인지 식별할 수 있도록 학습합니다.
CNN을 적대적으로 학습시켜, 어느 도메인의 특징량인지, D가 모르도록 CNN을 학습시킬 수 있으면, Target CNN은 도메인 불변의 특징량을 추출할 수 있게 된 것입니다.
CyCADA라는 기술은 원본 도메인에서 대상 도메인의 변환을 Cycle GAN으로 수행합니다. 이 변환된 데이터와 대상의 특징량 분포는 비슷해야 하므로 ADDA처럼 적대적 학습을 함으로써 분포 사이의 거리를 가깝게 합니다. 아래의 그림은 CyCADA 학습을 나타낸 그림입니다.

물체 감지
Perceptual GAN은 작은 물체를 감지하기 위해 제안된 방법입니다. 물체 감지에서 큰 물체와 작은 물체의 특징맵이 크게 달라서, 작은 물체를 감지하기 어렵다고 지적하고 있습니다. 아래의 그림은 Perceptual GAN의 개요입니다.

Perceptual GAN은 작은 물체의 특징맵을 큰 물체의 특징맵에 가깝게 하는 G와, 큰 물체의 특징맵인지, 작은 물체의 특징맵에서 G에 의해 생성된 특징맵인지 식별하는 D로 구성됩니다. 다음 그림은 G에 의해 작은 물체에서 생성된 특징맵의 예제입니다.
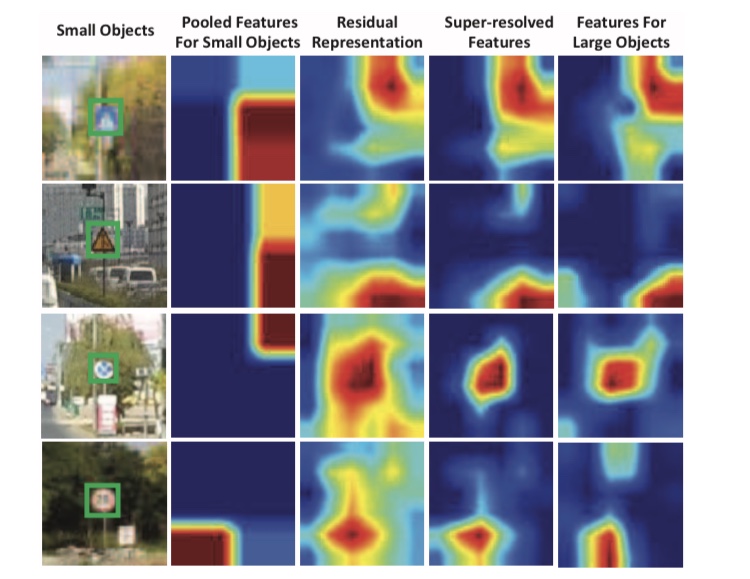
오른쪽에서 두 번째 특징량은 G에 의해 생성된 특징맵으로 맨 오른쪽 열은 큰 물체의 특징맵입니다. 이를 통해, 작은 물체라도 정밀하게 검출하는 것이 가능해졌습니다.
Segmentation(세분화)
비 지도 학습 세그멘테이션에 GAN이 사용되고 있습니다. 이 기술을 ReDO라고 합니다.
ReDO는 물체의 경계를 확인하고 그 내용을 다시 그리는 G와 G에 의해 생성된 이미지인지, 진짜 이미지인지 여부를 식별하는 D로 구성됩니다. 적대적으로 학습시키는 것으로, G는 세분화를 할 수 있게 됩니다.
초해상도화
초해상도화는 저화질 이미지를 고화질의 이미지로 변환하는 시도입니다. SRGAN는 처음으로 초해상도화에 GAN을 적용한 연구입니다. 기본적인 구조는 DCGAN과 같으며, 손실 함수는 다음과 같습니다.

SRGAN은 G의 학습에 있어서, 보통의 적대적 loss 이외에 콘텐츠 loss를 추가하여 학습을 실시합니다. 이것은 생성 이미지에서 추출한 특징량과 정답 이미지에서 추출한 특징량 사이의 손실입니다. 픽셀이 아닌 특징량 기반의 손실을 생각하는 것으로, 인간이 봐도 위화감이 없는 고화질의 이미지를 생성하는 데 성공하고 있습니다.
정보 검색
IRGAN은 어느 쿼리 q에 대하여 document d를 반환하는, 정보 검색에 사용된 첫 GAN입니다.
정보 검색의 목적은 어느 쿼리 q와 관련된 document d를 연관 짓는 실제 확률 분포 p(d | q)를 구하는 것입니다.
IRGAN에서는 쿼리 q에 대해, G는 연관된 d를 샘플링할 수 있도록 학습합니다. 한편, D는 G가 제시하는 d와 실제 관련이 있는 dt를 정밀하게 식별하도록 학습합니다. 학습이 수렴할 때, G는 실제 확률 분포에 가까운 것을 얻을 수 있습니다.
자연 언어에서의 이미지 생성
자연 언어를 입력으로 하여, 해당 언어를 반영한 이미지 생성이 Conditional GAN의 틀에서 이루어지고 있습니다.
TAC-GAN은 진짜 이미지 Ireal에게 부여된 자연 언어 t를 잠재적 변수에 심어서, 그것과 노이즈 z를 합친 것을 G에 입력합니다. 아래의 그림은 TAC-GAN의 개요입니다.

여기서, Iwrong은 Ireal 과는 다른 클래스에 속하는 이미지로, Cr은 Ireal 클래스, Cw는 Iwrong 클래스입니다. TAC-GAN의 D는 일반적인 GAN과 달리 생성된 이미지가 진짜인지 여부의 확인뿐만 아니라 그 이미지가 어떤 클래스에 속하는지까지 식별합니다.
즉, 이미지로서는 진짜에 가까워도, 클래스로서는 다를 때(입력 언어는 Cr에 부여된 자연 언어로, 예측된 클래스가 Cw)는 손실을 줍니다. 이렇게 함으로써 자연 언어에 대응하는 이미지를 생성하는 것이 가능합니다. 다음 그림은 생성된 그림의 예입니다.

음악 생성
C-RNN-GAN은 음악 생성에 GAN을 적용한 연구입니다. 아래의 그림은 C-RNN-GAN의 개요를 나타낸 그림입니다.

아래의 파란색 부분이 G, 위의 노란색 부분이 D를 나타냅니다. G에 의해 생성된 음악이 진짜인지 가짜인지 D가 식별합니다. G는 D를 속이거나 음악을 생성합니다.
사이버 보안
최근 악성 코드라고, 악성 소프트웨어나 코드에 의한 공격이 증가하고 있습니다. 이 공격에 대해 악성 코드 탐지 시스템을 도입하여 어느 정도 악성 코드를 탐지하고 제거할 수 있습니다.
MalGAN은 악성 코드 탐지 시스템을 속이는 악성 코드를 작성하기 위한 GAN입니다. 우선 악성 코드 탐지 시스템의 내부 정보를 알 수 없다고 가정합니다. 이를 블랙박스 공격이라고 합니다. 알 수 있는 것은, 악성 코드 탐지 시스템의 예측 결과뿐입니다. 아래의 그림은 MalGAN의 개요도를 나타낸 것입니다.

여기서 중간 Black-BOX Detector(BBD)가 탐지 시스템입니다. 우측의 Substitute Detector(SD)는 BBD예측 결과를 모방하도록 학습됩니다. 먼저 G가 BBD를 속이거나 악성 코드를 생성합니다. 한편, Benign(양성 프로그램)도 입력됩니다. 이에 대해 BBD는 예측 라벨을 반환하기 때문에 그것을 정답 라벨로 하여 SD는 학습을 수행합니다.
이 SD가 BBD를 모방할 수 있으면, 나머지는 SD(즉, 이것이 D입니다)를 속이거나 적대적으로 학습할 수 있으며, 그 결과, G는 BBD를 속일 수 있는 악성 코드를 생성할 수 있습니다.
정리
여기서는 GAN이 생성하는 이미지를 평가하는 대표적인 지표와 GAN의 응용에 대해 소개했습니다. 사실 아직 소개하지 못한 것도 많이 있어서, GAN에는 무한한 가능성이 숨어있다고 재차 느꼈습니다.
알고리즘 편의 서두에서 2018년에는 GAN에 관한 논문이 12000개 정도 발표됐다고 했습니다. 이러한 경향은 계속되어갈 것입니다. 아직 적용되지 않은 분야에서도 사용되지 않을까 생각합니다. 여러분도 GAN이 어떻게 사용되고 있는지 체크해 보시면 재미있으실 것이라 생각합니다.
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| 나는 어떻게 TensorFlow 개발자 자격증을 통과했는가 (3) | 2020.08.17 |
|---|---|
| 일본에서 60만 건의 구인정보를 분석하여 데이터 과학자의 평균 연봉과 채용 조건을 분석 (0) | 2020.07.01 |
| 코드 없는 AI 플랫폼, 사용해야 하나요? 그 한계와 기회 (0) | 2020.06.28 |
| 기계 학습 엔지니어는 10년 후에는 존재하지 않을것이다. (0) | 2020.06.13 |
| GAN의 발전의 역사( 알고리즘 편 ) (0) | 2020.06.09 |
| 스타벅스는 커피 사업자가 아닌 데이터 테크 기업이다 (0) | 2020.06.03 |
| 완전 비지도 학습으로 라벨링과 특징 표현을 모두 스스로 학습하는 'SeLa' (0) | 2020.05.10 |
| '모르겠다'를 아는 AI, 적은 자원의 환경에서 미학습 도메인을 감지! (0) | 2020.04.20 |



