
3개의 요점
✔️ 다양한 분야에서 사용되는 GAN의 포괄적인 조사 논문 소개
✔️ GAN의 알고리즘에 초점을 맞춘 다양한 접근 방식을 소개
✔️ GAN의 최신 동향
A Review on Generative Adversarial Networks : Algorithms, Theory, and Applications
written by Jie Gui, Zhenan Sun, Yonggang Wen, Dacheng Tao, Jieping Ye
(Submitted on 20 Jan 2020)
subjects : Computer Vision and Pattern Recognition (cs.CV) ; Machine Learning (cs.LG)
시작하기
2014년 이미지 생성을 위한 알고리즘 'GAN'이 발표되었습니다. 최근 튜링상을 수상한 Yann LeCun 씨는 GAN을 '기계 학습에서 지난 10년 동안 가장 재미있는 아이디어'라고 평가하고 있습니다.
GAN의 발표 이후, GAN에 대하여 많은 논문이 발표되었으며, 2018년에는 GAN관련 논문이 11,800개 발표되었다는 보고가 있습니다. 이미지 생성의 틀에서 태어난 GAN이지만 지금은 자연 언어 처리와 음성 처리 등 다양한 분야에서 응용되고 있습니다.
여기서는 알고리즘적 측면에서 GAN 발전의 역사를 소개합니다.
GAN이란?
GAN은 한마디로 표현한다면 생성기(이하 G)와 식별기(이하 D)의 두 가지가 서로 적대적인 학습을 실시하는 것입니다. G는 생성한 이미지를 가능한 한 실제에 가깝도록, 그리고 D는 입력된 이미지가 진짜인지 아니면 G가 생성해낸 가짜인지를 정밀하게 식별하는 학습이 이루어집니다. 이것을 나타낸 것이 아래 그림입니다.
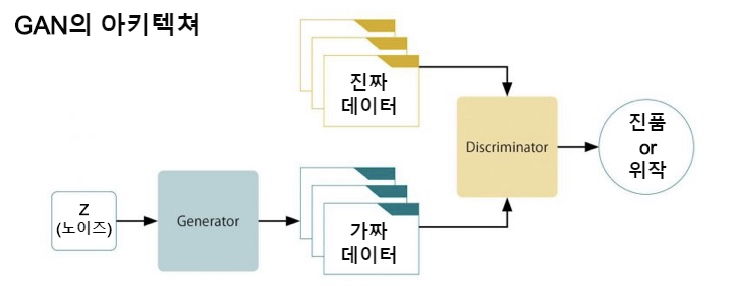
G는 노이즈 Z로부터 실제에 가까운 이미지를 생성하도록 학습합니다. D는 실제 이미지와 G가 생성한 이미지의 구별이 불가능할 때, 학습이 수렴됩니다. 즉, G는 학습 데이터의 분포를 학습할 수 있었다는 것을 의미합니다.
오리지널 GAN의 손실 함수는 다음과 같이 나타낼 수 있습니다.
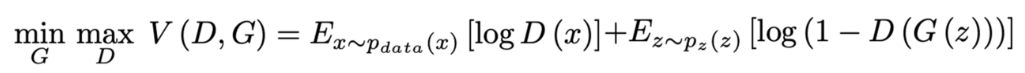
G를 고정하고, D의 최적의 해(풀이)를 찾으면 다음과 같습니다.

여기서, Pg는 G가 획득한 데이터의 분포입니다. 즉, Pg = Pdata가 될 때, D는 1/2이 됩니다.
여기서 이 D✳︎G 를 원래의 식에 대입하면 원래 GAN은 'JS거리'라는 것을 최소화하는 문제로 귀착합니다. 여기에서 JS거리는 KL거리를 대칭으로 한 거리입니다.
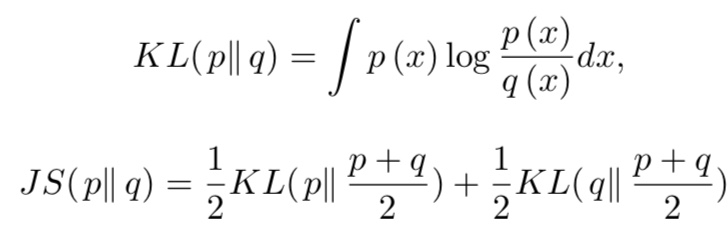
GAN의 문제점
GAN은 학습에 큰 문제를 안고 있습니다. 그것은 경사 손실 문제와 모드 붕괴입니다. 아래의 그림은 원래 GAN의 손실 함수를 D(G(z))를 축으로 나타낸 것입니다.

붉은 선이 원래의 GAN을 나타냅니다. 학습 초기에는 실제 데이터와 G가 생성하는 데이터를 쉽게 확인할 수 있습니다. 즉, D(G(z))는 0에 가깝습니다. 0 부근에서는 거의 경사가 0이며, G학습이 충분히 이루어지지 않습니다. 이를 '경사 손실 문제'라고 합니다.
또한 우연히 G가 D를 속이는 이미지를 생성했을 때, 그 이미지만 계속 생성하면 손실 함수는 작아집니다. 즉, 학습된 G는 유사한 이미지만을 생성할 수 있습니다. 이를 '모드 붕괴'라고 합니다.
GAN의 대표적인 변종
그럼, 이제부터 GAN의 대표적인 변종들을 소개하겠습니다.
InfoGAN
원래 GAN에서는 노이즈 z를 변경하면 이미지가 어떻게 변할지 조정하는 것이 어렵다는 문제가 있었습니다. InfoGAN은 잠재 변수 c를 준비하고 상호 정보량을 극대화 함으로써 c에 이미지의 특징을 포함하는 데 성공했습니다. 다음 표현식은 InfoGAN의 손실 함수입니다.
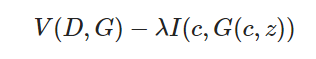
위의 식에 있듯이, G의 생성하는 이미지 정보를 c에 포함하도록 학습을 진행합니다.
Conditional GAN
Conditional GAN은 어떤 조건의 원래 이미지를 생성하는 것입니다. 예를 들어, 클래스 라벨이나 문장 특징으로 조건을 달아서 해당 이미지를 생성하는 것입니다.
유명한 Conditional GAN의 예로 pix2pix를 들 수 있습니다. 이것은 이미지 사이의 스타일을 변환하는 방법입니다. 다음 그림은 흑백 이미지에 색을 칠하는 작업을 보여주고 있습니다.
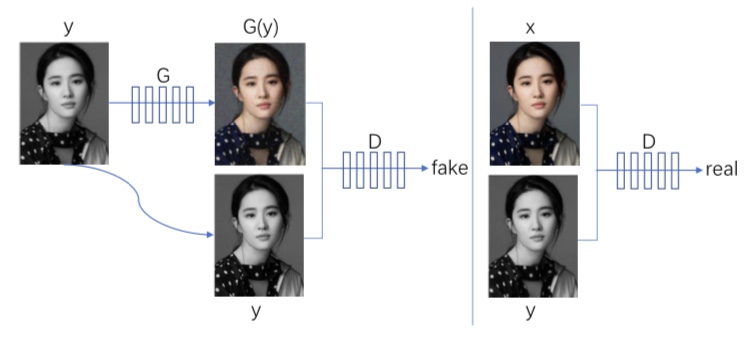
pix2pix는 원본 이미지 y를 G에 의해 변환합니다. y를 수정한 이미지 G(y)가 진정한 페어(쌍)인지, 그리고 동시에 x라는 진짜 이미지에 대해서도 x와 y가 진짜 페어(쌍)인지 정확하게 식별하도록 D의 학습이 진행됩니다.
한편, G는 G(y)와 y가 진짜 페어(쌍)라고 D가 잘못 인식할 수 있도록 학습합니다. 따라서 G는 자연적인 변환 방법을 배울 수 있습니다. (x, y)는 쌍으로 학습하고 있다는 점에서 조건부라고 할 수 있습니다.
CycleGAN
CycleGAN은 pix2pix와 비슷하지만 조건 설정이 다릅니다. pix2pix는 이미지마다 1대 1로 페어(흑백 이미지와 그에 대응하는 색이 입혀진 이미지)가 존재합니다. 그러나 페어를 얻을 수 없는 경우도 많습니다. 예를 들어, 말과 얼룩말의 이미지처럼, 1 대 1로 이미지가 대응하고 있지 않는 경우 등입니다.
이러한 경우에도 스타일 변환이 가능한 것이 CycleGAN입니다. 아래의 그림은 CycleGAN의 개요입니다.

CycleGAN에는 두 개의 생성기 G · F와 두 개의 식별기 Dx · Dy가 존재합니다. G를 사용하여 x를 y로 변환하고 이를 Dy로 식별합니다. y역시 마찬가지입니다.
이대로 학습을 하면 페어가 존재하지 않기 때문에 스타일뿐만 아니라 다른 부분도 변경될 가능성이 있습니다. 그래서 CycleGAN은
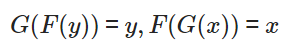
가 되도록 제약을 거는 것을 제안하고 있습니다. 원래로 돌아간다는 제약을 걸어서 변환된 이미지의 복구가 가능하도록, 즉 크게 변화하지 않도록 하고 있습니다.
WGAN
WGAN은 GAN의 학습을 안정시키기 위해 'Wasserstein 거리'라고 불리는 두 개의 분포 사이의 거리측도를 이용한 손실 함수를 제안한 GAN입니다.
Wasserstein 거리는, 어떤 분포를 대상이 되는 분포에 일치시키는데 필요한 최소 거리입니다. 이산 분포를 이용하면 이해하기 쉽습니다. 분포 P와 Q가 있어서, P를 Q에 일치시키는 것을 생각합시다. 여기서는 다음과 같이 P와 Q를 가정합니다.
P1 = 0.3, P2 = 0.2, P3 = 0.1, P4 = 0.4
Q1 = 0.1, Q2 = 0.2, Q3 = 0.4, Q4 = 0.3
이 두 분포를 일치시키기 위해서는 P1에서 P2로 0.2, P2에서 P3으로 0.2, Q3에서 Q4로 0.1 이동시킴으로써 두 분포를 일치시킬 수 있습니다. 이것을 나타낸 것이 아래 그림입니다.
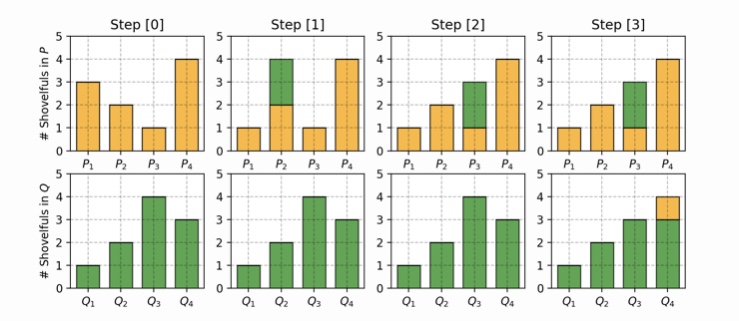
이 합계가 Wasserstein 거리(0.2 + 0.2 + 0.1 = 0.5)입니다. 이것을 연속 분포에 적응하면 다음과 같이 됩니다.

GAN의 문제점에서도 소개했지만, JS거리와 W거리에서는 무엇이 다른 것일까요. 이 차이를 보기 위하여 다음과 같은 가정에서 JS거리와 W거리를 계산해 봅시다.

즉, P는 x=0에서만 확률 값을 Q는 x=θ 일 때만 확률 값을 가지는 분포입니다. 이때,
JS거리 = log2(θ ≠ 0), W거리 =
가 됩니다. θ=0일 때는 JS거리는 0이 되고 불연속 함수임을 알 수 있습니다. 한편, W거리는 연속이며, 이것이 GAN의 안정된 학습을 가능하게 합니다. 더 자세한 논의는 여기를 참조하십시오.
From GAN to WGAN
This post explains the maths behind a generative adversarial network (GAN) model and why it is hard to be trained. Wasserstein GAN is intended to improve GANs’ training by adopting a smooth metric for measuring the distance between two probability distri
lilianweng.github.io
손실 함수를 공부한 GAN
GAN의 문제점에서도 언급했듯이, 원래 GAN의 학습은 매우 불안정합니다. 이를 해결하기 위해 다양한 손실 함수에 의한 GAN이 제안되고 있습니다.
LSGAN
LSGAN은 매우 단순하면서도 G의 학습 초기에 있어서의 기울기 손실 문제를 해결하는 손실 함수를 제안하고 있습니다.

여기서 a, b, c는 하이퍼 파라미터로, 논문에서는
a = 0, b = 1, c = 1
등이 추천되고 있습니다. 두 번째 식에서 알 수 있듯이, 학습 초기에 c=1로 하는 것으로, G학습에 충분한 경사를 얻을 수 있습니다.
Hinge loss based GAN
힌지 loss를 베이스로 하여 손실 함수를 이용한 GAN도 제안되고 있습니다.
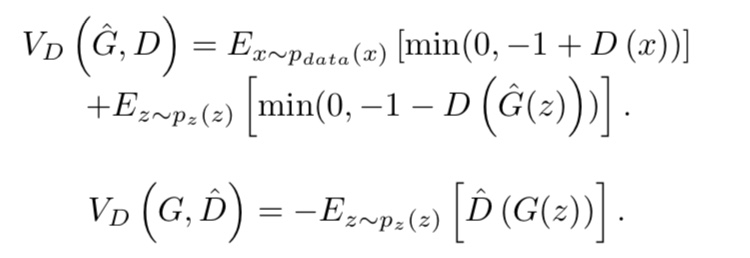
BEGAN
BEGAN에서 D는 auto encorder입니다. 즉, D는 실제 이미지인지, G가 생성한 이미지인지, 명시적으로 식별하지 않습니다. 대신 아래의 Wasserstein 거리를 극대화합니다.

여기서 m real은 진짜 이미지의 복원 오차이고, m gen은 G에 의해 생성된 이미지의 복원 오차입니다. W를 극대화한다는 것은 실제 이미지 복원 오차를 0에 가깝게 하여, 생성된 가짜 이미지의 복원 오차를 발산한다는 것입니다.

동시에, G는 자신이 생성한 이미지의 복원 오차를 줄일 수 있도록 학습합니다. 즉 G는 리얼한 이미지를 생성하는 것 밖에는 G와 D, 어느 쪽의 학습도 성공시킬 수 없습니다. 더 자세한 논의는 여기를 참조하십시오.
Began: State of the art generation of faces with generative adversarial networks
This post describes the theory behind the newly introduced BEGAN.
medium.com
GAN의 대표적인 구조
DCGAN
오리지널 GAN의 G와 D는 MLP(다층 퍼셉트론)로 구성되어 있었습니다. 이에 비해 DCGAN은 콘볼루션 층을 이용하여 G와 D의 표현력을 높이고 있습니다. 아래의 그림은 G에 사용된 구조의 예입니다.

SAGAN
기존의 GAN의 구조는 CNN을 기반으로 하고 있으며, 국소적인 부분에 주목하여 이미지를 생성해 버리는 문제가 있었습니다. Self AttentionGAN(SAGAN)은 Self Attention기구를 GAN의 구조에 통합하여 포괄적 특징으로 생성합니다.
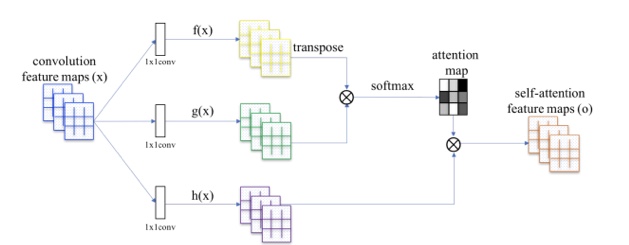
위 그림의 f(x) :쿼리와 g(x) :키에 의해, 각 화소와 비슷한 화소 부분을 추출하고 attention map을 생성합니다. 그 후, h(x) :가중치와 attention map을 곱함으로써 Self Attetion map을 만듭니다. 이를 GAN의 구조에 통합함으로써 보다 포괄적인 특징을 고려하여 고품질의 이미지를 생성하는 데 성공하고 있습니다.
StyleGAN
StyleGAN은 고품질의 얼굴 이미지를 생성하는 데 성공한 GAN입니다. 뿐만 아니라 StyleGAN은 머리 · 연령 · 성별 등을 제어할 수 있습니다. 아래의 그림이 StyleGAN의 개요입니다.
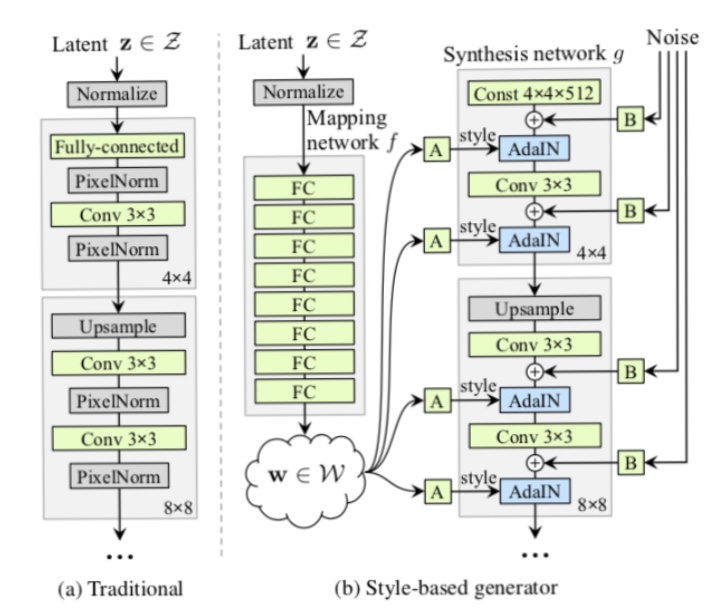
StyleGAN은 잠재 변수 z에서 직접 이미지를 생성하는 것이 아니라 중간 특징량으로서 G의 AdaIN 부분에 입력됩니다. 여기서 AdaIN은

위와 같이 정의됩니다. x는 입력, y는 화풍 변환을 원하는 스타일의 이미지입니다. 스타일 이미지의 평균 μ(y)과 표준 편차 σ(y)를 이용하여 화풍을 변환합니다.
학습에 의해 머리와 성별 등의 스타일이 학습되어, 컨트롤 가능한 변수가 됩니다. 또한 StyleGAN에서는 노이즈를 G의 중간에 입력하여 머리카락의 흐름이나 주근깨 등을 변화시킬 수 있습니다.
Progressive GAN
Progressive GAN은 저해상도의 이미지 생성에서 시작하여, 점차 레이어를 추가하여 고해상도 이미지를 생성하는 데 성공한 GAN입니다. 아래의 그림은 Progressive GAN의 개요도를 나타냅니다.
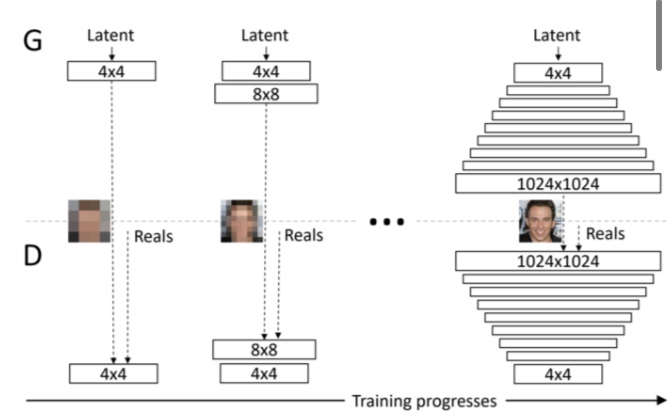
이 구조의 장점은 노이즈 z에서 갑자기 고화질의 이미지를 생성하는 것보다는 낮은 화질의 거친 이미지의 생성이 더 간단한 작업이기 때문에 학습이 간단하다는 것입니다. 학습 시간도 줄일 수 있습니다.
BiGAN
기존의 GAN에서는 노이즈 z에서 이미지를 생성하는 단방향 학습만 하고 있었습니다만, BiGAN에서는 이미지로부터 z를 생성하는 양방향의 생성 메커니즘을 도입하는 것으로, 이미지 특징량을 얻는 데 성공하고 있습니다.
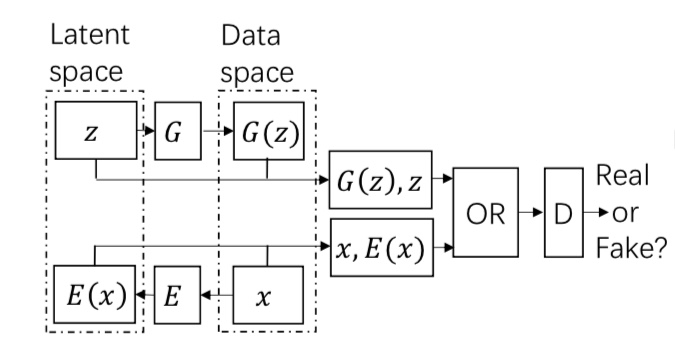
이미지 x는 인코더 E에 의해 특징이 추출되어, E(x)와 z를 포함하여 적대적 학습을 실시하는 것으로, 이미지 특징량을 추출할 수 있도록 인코더를 배울 수 있습니다.
D2GAN
D2GAN은 두 식별기와 하나의 생성기로 구성된 GAN입니다. D2GAN은 모드 붕괴를 해결하는 방법이 되고 있습니다.

D2GAN는 손실 함수가 KL거리와 reverse KL거리의 가중치화 한 함수입니다. 즉, 손실 함수는 다음과 같습니다.

여기서 제1항이 KL거리, 제2항이 reverse KL거리입니다. 그럼 이 두 거리는 무엇이 다른 것일까요.
다음과 같은 분포 P와 Q를 상정해 봅시다. 여기서는 Q를 P에 접근시키고자 합니다.

KL거리의 경우 P로 가중되고 있기 때문에 KL거리는 바로 산처럼 커져 버립니다. KL거리를 작게 하려고 하면 오른쪽의 산과의 거리를 작게 하려고 하는 아래와 같은 분포가 됩니다.

한편, reverse KL거리에서는 Q에서 가중되고 있기 때문에, P의 오른쪽 산은 무시되어 버립니다. 즉, 원래의 상태로 KL거리가 줄어듭니다.
즉, D2GAN의 손실 함수의 최소화에 의해 KL거리와 reverse KL거리를 작게 한다는 것은 생성된 이미지의 품질과 다양성을 매개 변수로 조정할 수 있다는 것입니다. α를 크게 하면 다양성을, β를 크게 하면 품질을 중시한다는 것입니다.
MGAN
MGAN는 D2GAN과 반대되는 것으로 여러 생성기와 하나의 식별기, 어떻게 생성기에서 이미지가 생성되었는지 확인하는 분류기로 구성됩니다. 아래의 그림이 MGAN의 개요입니다.
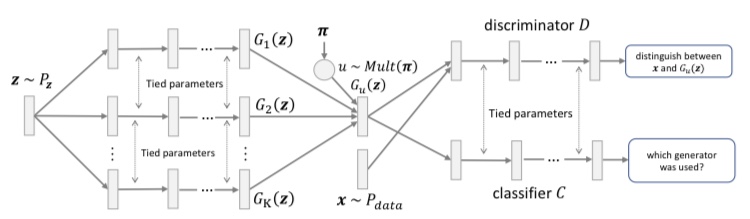
식별기는 여러 생성기가 생성한 이미지를 가중하여 얻은 이미지와 실제 이미지를 식별하는 것과 같이 학습됩니다. 한편, 각각의 생성기의 생성하는 이미지 분포의 JS거리를 최대화 함으로써 각 생성기가 다른 이미지를 생성하도록 합니다.
실제로 이미지를 생성할 때 여러 생성기 중 하나를 선택합니다. 이러한 학습을 실시하는 것으로, 고품질의 이미지를 생성할 수 있고 모드 붕괴를 방지할 수 있습니다.
정리
이번에는 GAN의 기초부터 시작해 지금까지 제안되어 온 다양한 GAN을 소개해 봤습니다. 원래 GAN은 학습이 불안정하기 때문에, 그 해결법도 여럿 제안되고 있습니다.
또한 이미지 생성 작업에서 시작된 GAN이지만, 현재는 이미지 생성뿐만 아니라 자연 언어 처리와 음성 처리 등 다양한 작업에 응용되고 있습니다. 다음은 GAN이 생성한 이미지의 품질을 측정하는 지표와 GAN의 응용에 대하여 소개하겠습니다.
GAN의 발전의 역사( 응용 편 )
3 개의 요점 ✔️ 다양한 분야에서 사용되는 'GAN'의 포괄적인 조사 논문 소개 ✔️ GAN의 품질을 측정하는 지표 및 다양한 응용을 소개 ✔️ GAN을 어디에 적용할 수 있는지 포괄적으로 파악이 가��
doooob.tistory.com
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| 일본에서 60만 건의 구인정보를 분석하여 데이터 과학자의 평균 연봉과 채용 조건을 분석 (0) | 2020.07.01 |
|---|---|
| 코드 없는 AI 플랫폼, 사용해야 하나요? 그 한계와 기회 (0) | 2020.06.28 |
| 기계 학습 엔지니어는 10년 후에는 존재하지 않을것이다. (0) | 2020.06.13 |
| GAN의 발전의 역사( 응용 편 ) (0) | 2020.06.10 |
| 스타벅스는 커피 사업자가 아닌 데이터 테크 기업이다 (0) | 2020.06.03 |
| 완전 비지도 학습으로 라벨링과 특징 표현을 모두 스스로 학습하는 'SeLa' (0) | 2020.05.10 |
| '모르겠다'를 아는 AI, 적은 자원의 환경에서 미학습 도메인을 감지! (0) | 2020.04.20 |
| 한 줄의 코드로 자동학습! 머신러닝을 자동화하는 AutoML (2) | 2020.04.12 |



