3 개의 요점
✔️ 단어의 삽입과 삭제를 이용한 새로운 문장 생성 방법을 제안
✔️ 기존 방식에 비해 빠른 계산이 가능
✔️ 기계 번역 작업에서 성능이 향상
문장 생성은 자연 언어 처리에서 활발히 연구되고 있는 분야 중 하나입니다. 문장 생성을 이용한 자연 언어 처리 기술의 대표적인 응용 분야로서 기계 번역과 채팅 봇 등이 있습니다. 이러한 문장 생성은 언어 모델이라는 기술이 이용되고 있으며, 신경망을 이용한 방법이라면 LSTM와 Transformer 등으로 이전부터 순서대로 한 단어씩 생성해가는 방법이 일반적입니다.
이번에 소개하는 논문에서는 이러한 기존의 '한 단어씩 생성하는' 방법과는 다른 방법을 제안하고 있습니다. 제안된 방법은 한 번에 여러 단어를 한꺼번에 생성하고 그것을 바탕으로 단어의 삭제나 추가 편집 작업을 반복하여 원하는 문장을 생성합니다.
기존 방식에 비해 문장을 출력하는 데 필요한 계산 횟수가 줄어들기 때문에 빠른 문장생성이 가능합니다. 또한 기계 번역 작업에서 성능 향상도 보고되고 있습니다. 이 논문은 2019년 겨울에 캐나다에서 개최되는 기계 학습의 최고 콘퍼런스인 NeurIPS 2019에도 채택되고 있습니다.
일반적인 자기 회귀 모델에 의한 문장 생성
이 논문에 제안된 방법을 소개하기 전에 일반적인 문장 생성 방법에 대해 알아보겠습니다. 자연 언어 처리 기술에 의한 문장 생성은 이전부터 순서대로 단어를 하나씩 출력해가는 방법이 일반적으로 이용되고 있습니다. 예를 들어 "today is a beautiful day"라는 글(단어의 나열)을 출력할 때 먼저 첫 번째 단어인 today를 출력하고 이 today라는 단어를 바탕으로 다음의 is를 출력합니다. 또한 today is라는 문맥을 입력하고 다음 a, 그다음 beautiful을 같은 방식으로 출력해 갑니다.
즉, 문장 생성은 '어느 문맥으로부터 다음 단어를 예측하는 태스크'에 대입하는 방식으로 모델링 되어 있습니다. 이것은 언어 모델링을 불리며, 최근의 신경망을 이용한 방법에서는 LSTM이나 Transformer를 이용하여 문맥을 인코딩하고 다음 출현할 단어의 분포를 계산하는 모델이 유명합니다.
이러한 방법을 이용하여 문장 생성을 할 경우, 각 단계에서 단어를 예측하기 위해서는 매번 지금까지의 상황을 이용한 확률 계산을 해야 합니다. 따라서 출력할 문장이 길어지면 길어질수록 문장 생성에 시간이 소요됩니다. 예를 들어 위의 문장이면 맨 앞의 'today'에서 마지막 'day'를 출력하기까지 5번의 계산이 필요합니다. 마찬가지로 100 단어를 출력하기 위해서는 최소 100회의 계산이 필요합니다. 특히 최근의 문장 생성에 널리 이용되고 있는 Transformer는 시점마다 모든 계산을 다시 기록해야 하기 때문에 이것은 간과할 수 없는 문제입니다.
문장의 길이에 비례하여 계산 시간이 길어져 버리는 문제를 해결하는 방법으로, 모든 단어를 한 번에 출력하는 방법(비 자기 회귀모델 not-self regression model)이 제안되고 있습니다. 위의 예라면, 문장의 길이로 5 단어가 주어진다고 가정할 때, "today is a beautiful day"의 모든 단어를 한 번에 출력합니다. 그러면 문장의 길이에 관계없이 1회 계산으로 문장을 출력할 수 있습니다. 그러나 이 모델은 문장의 길이를 미리 지정하지 않으면 안 된다는 점과 문맥을 이용할 수 없다는 점 등의 단점이 있습니다.
삽입과 삭제를 이용한 모델에 의한 문장 생성
이 논문은 지금까지 제안되어 왔던 자기 회귀 모델과 비 자기(not-self) 회귀 모델을 결합하여 빠른 속도로 새로운 문장을 생성하는 기법을 제안하고 있습니다. 이 방법에 의하면 삽입과 삭제 작업을 반복하면서 문장을 편집해 가는 것으로 원하는 문장을 만들 수 있습니다.
구체적인 예로, 위에서 언급 한 예문인 "today is a beautiful day"를 출력하는 과정을 보겠습니다. 먼저 다음과 같이 단어를 넣을 수 있는 빈 토큰(PLaceHolder)을 여러 개 생성합니다.
[PLH] [PLH] [PLH]
삽입 단계에서는 위와 같이 빈 토큰을 생성하고 거기에 단어를 끼워 넣습니다.
today day beautiful
이어서 제거 단계에서는 불필요한 단어를 삭제합니다.
today day beautiful
다시 삽입 단계에서 빈 토큰을 각 단어 사이에 몇 개 삽입합니다.
today [PLH] [PLH] beautiful [PLH]
다시 이 빈 토큰에 단어를 삽입합니다.
today is a beautiful day
계속되는 삽입/삭제 단계에서 더 이상 글을 편집할 필요가 없다고 판단되면 삽입/삭제의 루프를 빠져나와 문장이 완성됩니다.
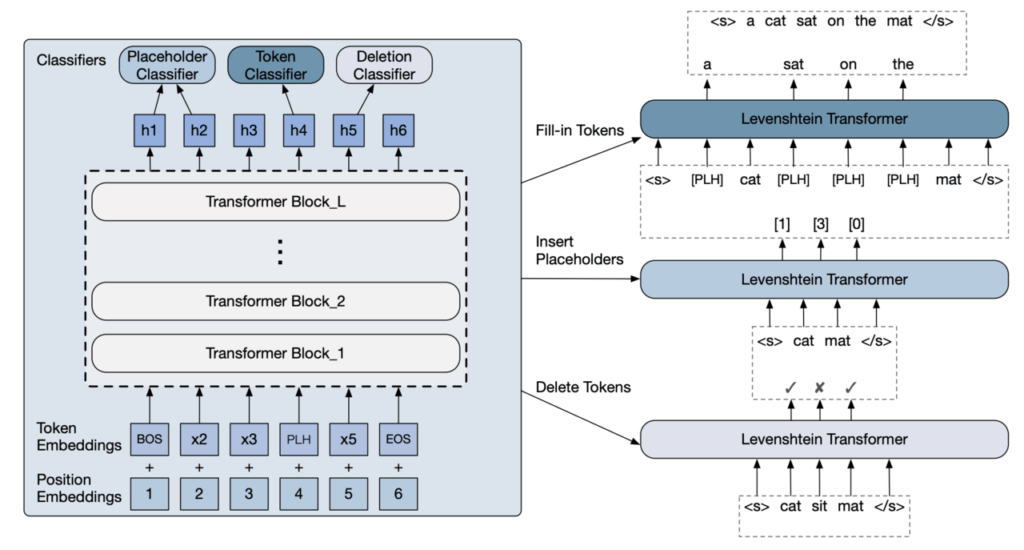
위와 같은 삽입과 삭제의 편집을 이용한 문장 생성을 위해 '빈 토큰을 삽입하는 기구', '빈 토큰에 단어를 끼워 넣는 기구', '단어를 삭제하는 기구' 이렇게 세 가지가 필요합니다. 각 기구가 담당하는 작업은 단순하기 때문에 각각 분류하여 문제를 해결하는 모델로 생각할 수 있습니다. 제안된 방법은 Transformer를 사용하여 생성 도중의 문장을 읽고, 세 기구에 의해 각 작업의 계산을 수행합니다.
먼저 빈 토큰을 삽입하는 기구(Placeholder Classifier)는 어느 두 개의 단어 사이에 몇 개의 빈 토큰이 삽입될지를 예측합니다. 다음으로 빈 토큰에 단어를 끼워 넣는 기구(Token Classifier)는 빈 토큰에 알맞은 최적의 단어를 전후 문맥에서 예측합니다. 마지막으로 단어를 삭제하는 기구(Deletion Classifier)는 전후 문맥을 고려하여 해당 단어를 삭제해야 할지를 분류합니다.
이 모델에 의한 문장 생성은 비 자기 회귀 모델처럼 한 번의 계산으로 여러 단어를 출력할 수 있습니다. 즉 100 단어처럼 긴 문장을 출력하는 경우에도 100회 이하의 계산 횟수로 문장을 완성할 수 있습니다. 또한 직전에 출력한 글을 편집해 나가는 것으로 자기 회귀 모델처럼 문장 전체를 고려한 단어를 생성할 수 있습니다.
그러면 문장 생성시 성능의 저하 없이 고속으로 문장을 생성할 수 있습니다. 이 모델은 문자열 사이의 거리를 측정하고 편집하는 거리의 개념에서 Levenshtein Transformer라는 명칭이 붙어 있습니다.
※ levenshtein distance (편집 거리 알고리즘)는 두 문자열 간의 유사도를 측정하는 데 사용되는 알고리즘입니다.
기계 번역 작업 정밀도 향상 및 고속화에 성공
문장을 생성하는 모델의 평가에서 일반적으로 사용되는 기계 번역 태스크로 제안된 방법의 평가를 실시합니다. 기계 번역 태스크는 러시아어에서 영어, 영어에서 독일어, 영어에서 일본어의 세 가지 언어 간 번역을 대상으로 합니다. 또한 영어 문서 요약 작업으로 Gigaword라는 데이터셋을 이용한 실험도 게재하고 있습니다.
비교 모델은 최근 문장 생성 태스크에서 성공을 거두고 있는 Transformer모델로, 문장을 생성할 때 확률이 높은 4 패턴 문장의 가능성을 유지하면서 출력하는 모델(즉 beam size가 4 모델, 아래 표에서는 beam4)과 매번 가장 확률이 높은 단어를 순차적으로 출력하는 모델(greedy)을 사용합니다. 제안된 방법은 삽입 및 삭제 작업을 학습할 때 데이터에 포함된 문장만을 사용하는 모델 (oracle)과 다른 문장 생성 기법을 사용하여 학습 데이터를 생성하는 모델(distillation)의 두 가지를 비교합니다.
결과를 보시면, 러시아어에서 영어, 영어에서 독일어 두 기계 번역에서 성능이 향상된 것으로 보고되고 있습니다. 또 다른 실험에서도 Transformer의 수치와 동일한 정도의 성능이 나오고 있어, 출력 메커니즘을 변경하여도 크게 성능이 떨어지지 않는다고 판단할 수 있습니다.
하단에서는 문장의 출력에 걸리는 평균 시간(ms)과 출력에 필요한 삽입/삭제의 평균 반복수를 보여줍니다. 예를 들어 러시아어에서 영어로 기계 번역하면 기존의 Transformer는 문장의 출력에 평균 27.1번의 계산이 필요했던 반면, 제안된 방법은 2.03회로 계산이 끝나는 것을 알 수 있습니다. 이에 따라 전체 문장 출력에 걸리는 평균 시간도 크게 줄일 수 있습니다.

아래 그림은 제안된 기법을 이용하여 영어에서 일본어로 기계 번역되는 과정을 보여줍니다. 영문을 입력받은 모델이 첫 번째 반복에서 대부분의 단어를 출력하고, 다음 반복에서 중복 부분을 삭제하거나 부족한 단어의 삽입으로 완료하고 있는 모습을 볼 수 있습니다. 일본어의 출력은 11 단어가 포함되어 있기 때문에 기존의 방법으로는 11번 계산이 필요하지만, 제안된 방법은 단 2번 만에 생성이 종료되고 있습니다.

정리
이 논문에서는 기존의 방식과는 다른 새로운 방식으로 문장을 생성하는 방법을 제안했습니다. 삽입과 삭제 작업은 인간이 문장을 다룰 때의 프로세스와도 비슷하고, 그 문장 생성 과정은 인간에게도 알기 쉬운 것이라고 생각됩니다.
기계 번역과 문서 요약의 정확도를 떨어트리지 않고(일부는 성능 향상에 기여), 문장 생성을 가속화한 공헌은 크다고 말할 수 있습니다. 이것은 신경망을 이용한 실시간 응답 시스템의 속도 개선에도 기여할 것으로 생각됩니다.
Levenshtein Transformer
Jiatao Gu, Changhan Wang, and Jake Zhao (Junbo)
NeurIPS 2019
'AI · 인공지능 > AI 칼럼' 카테고리의 다른 글
| 미래를 예측하는 부품! 시계열 특징 Shapelets이란? (0) | 2020.01.09 |
|---|---|
| 메타 학습의 단점을 극복? CACTUs의 등장 (1) | 2020.01.08 |
| 알리바바, 고객 서비스 만족도를 대화 로그로 예측 (0) | 2020.01.07 |
| 일본의 AI사업을 견인하는 인기 기업 랭킹 5선 [2020년판] (0) | 2020.01.06 |
| 생성 이미지를 마음대로!? 새로운 GAN 프레임워크 'VCGAN' (0) | 2020.01.02 |
| AI학습을 더 인간 답게? 학습 경험을 살린 MTL학습법의 등장! (0) | 2020.01.01 |
| 3차원 모션 추정! 이미지 속 인간의 움직임을 3차원으로 재현! (0) | 2019.12.31 |
| 훈련 데이터에 없는걸 만든다고!? 최신식 GAN : COCO-GAN (0) | 2019.12.28 |



