
AI 개발 단체 OpenAI가 텍스트와 이미지를 숫자로 변환하는 Embedding 모델 text-embedding-ada-002를 발표했습니다. text-embedding-ada-002는 기존 모델에 비해 기능이 상당히 향상되어 비용대비 성능이 높아지고 사용이 간편하다고 합니다.
New and Improved Embedding Model
New and Improved Embedding Model
We are excited to announce a new embedding model which is significantly more capable, cost effective, and simpler to use. The new model, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperform
openai.com
Embeddings - OpenAI API
https://beta.openai.com/docs/guides/embeddings
알고리즘이 텍스트 및 이미지를 인식하려면 텍스트와 이미지를 숫자 데이터로 변환해야 합니다. 임베딩이란 텍스트와 이미지를 어떠한 벡터로 변환하는 과정으로, 요즘 자연어 처리 모델과 이미지 생성 AI에 필수적인 기술입니다.
text-embedding-ada-002에 액세스 하려면 Python에서 OpenAI API를 사용한 "OpenAI Python Library"에서 모델 이름에 "text-embedding-ada-002"를 지정하면 OK.
다음은 "porcine pals say"라는 문자열을 숫자로 변환하는 코드입니다.
import openai
response = openai.Embedding.create(
input="porcine pals say",
model="text-embedding-ada-002"
)
OpenAI에 의하면, 텍스트 검색 · 코드 검색 · 문장 유사성에 있어서는 text-embedding-ada-002가 기존 모델보다 퍼포먼스에서 우수하였고, 텍스트 분류에서는 기존과 동등한 퍼포먼스를 발휘했다고 합니다.
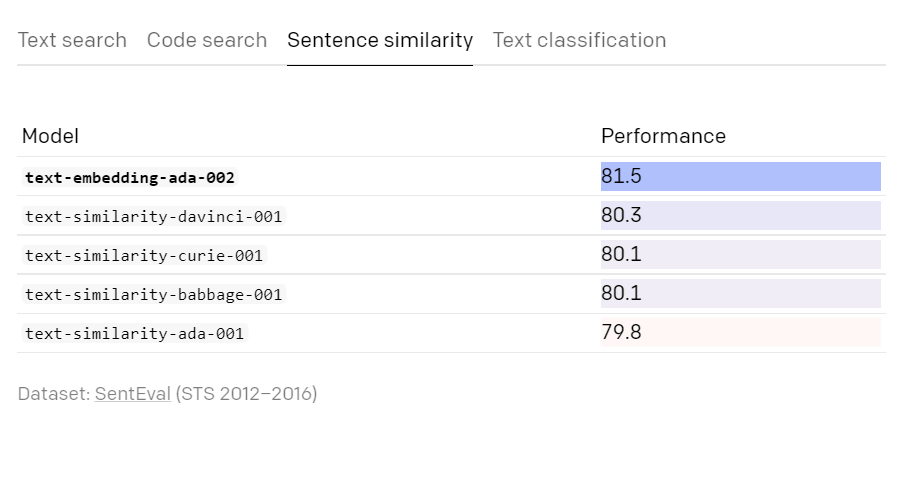
다음은 텍스트 검색을 비교한 결과로 "Performance"의 숫자가 클수록 성능이 우수함을 나타냅니다.

코드 검색

문장의 유사성
텍스트 분류는 이전 모델보다 약간 성능이 떨어지고 있지만, 90점대를 유지하고 있기 때문에 OpenAI는 거의 동등한 성능을 발휘했다고 코멘트.

기존 모델은 'text-search-davinci-*-001', 'text-similarity-davinci-001' 등과 같이 목적에 따라 모델이 별도로 되어 있었지만 text-embedding-ada-002는 텍스트 검색, 코드 검색, 문장의 유사성, 텍스트 분류가 통합되어 하나의 모델로 가능하다고 합니다.
또한 text-embedding-ada-002는 지금까지 입력 가능한 토큰 길이가 2048까지였던 것이 8192까지 증가되었고, 더 긴 문장을 처리할 수 있습니다. 게다가 텍스트를 다루는 벡터의 차원이 1536차원으로, 전 세대 모델의 8분의 1로 억제되었다는 것. 덧붙여 text-embedding-ada-002의 사용 코스트는 전 세대 모델「Davinci」보다 90% 인하되어 코스트 퍼포먼스로 생각하면 기존보다 99.8% 유리하다고 OpenAI는 주장하고 있습니다.
OpenAI는 "새로운 임베디드 모델은 자연어 처리 및 코드 작업을 위한 훨씬 더 강력한 도구입니다."라고 말하고 있습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| OpenAI가 3D모델 생성 AI「Point-E」를 오픈 소스화, 600배 빠른 3D 오브젝트 생성 (0) | 2022.12.22 |
|---|---|
| 이미지가 말을 한다!? 이스라엘의 스타트업 기업이 이미지 자동 생성 · 텍스트 리딩 AI를 발표 (0) | 2022.12.22 |
| OpenAI가 개발한 텍스트 생성 AI「GPT-3」가 어떤 처리를 하고 있는지 전문가가 해설 (1) | 2022.12.22 |
| 문장에 따른 악곡을 생성해 주는 AI「Riffusion」등장,「Stable Diffusion」베이스로 누구나 자유롭게 이용 가능 (1) | 2022.12.22 |
| DeepMind가 영화나 연극의 각본을 공동 집필해 주는 AI「Dramatron」을 발표 (0) | 2022.12.13 |
| DeepMind가 개발한 AI「AlphaCode」가 프로그래밍 콘테스트에서 '평균' 평가를 획득 (0) | 2022.12.13 |
| AI 개인 트레이닝「퍼포먼스 AI」오픈 (0) | 2022.12.12 |
| 작화의 90%를 AI가 담당! 그림책「사과 공주」가 크리에이터와 AI의 공동 작업으로 완성 (0) | 2022.12.12 |



