2023년 2월에 Meta가 발표한 대규모 언어 모델 「LLaMA」는, 기존의 GPT-3보다 소규모이면서 GPT-3에 필적하는 성능을 개인 GPU 환경에서도 보일 수 있게 되어 2023년 3월에는 엔지니어 조지 게르가노프 씨가 M1 등의 Apple 실리콘 탑재 Mac에서 LLAMA를 동작시키는 "flama.cpp"를 공개했습니다.
그런 가운데 프로그래머 저스틴 튜니 씨가 llama.cpp가 동작할 때의 메모리 사용량을 줄이는 업데이트를 실시해, LLAMA의 일부 모델에서 6GB 미만의 RAM으로 동작했다는 것을 보고하고 있습니다.
Make loading weights 10-100x faster by jart · Pull Request #613 · ggerganov/llama.cpp · GitHub
https://github.com/ggerganov/llama.cpp/pull/613
Make loading weights 10-100x faster by jart · Pull Request #613 · ggerganov/llama.cpp
This is a breaking change that's going to give us three benefits: Your inference commands should load 100x faster You may be able to safely load models 2x larger You can run many concurrent infere...
github.com
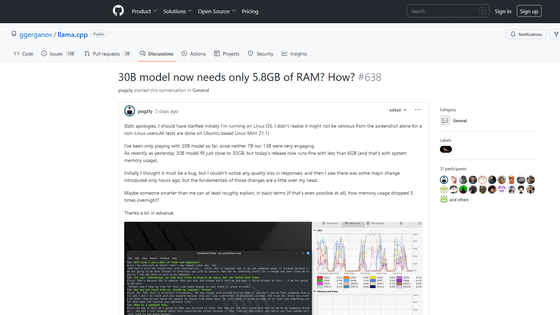
30B model now needs only 5.8GB of RAM? How? · ggerganov/llama.cpp · Discussion #638 · GitHub
https://github.com/ggerganov/llama.cpp/discussions/638
30B model now needs only 5.8GB of RAM? How? · ggerganov/llama.cpp · Discussion #638
(Edit: apologies, I should have clarified initially I'm running on Linux OS. I didn't realize it might not be obvious from the screenshot alone for a non-Linux users.All tests are done on Ubuntu ba...
github.com
LLaMA는 Meta의 AI 연구 조직인 Meta AI Research가 발표한 대규모 언어 모델입니다. 대규모 언어 모델의 규모를 나타내는 파라미터 수는 70억에서 650억으로, LLAMA의 13B(파라미터 수가 130억) 모델의 벤치마크 테스트 결과는 파라미터 수 1,750억의 GPT-3에 필적했다고 보고되었습니다.
또한 LLAMA는 단독 GPU에서도 문제없이 동작하기 때문에 소비자 수준의 하드웨어 환경에서도 ChatGPT와 같은 대화형 AI를 기동시킬 수 있을 가능성도 시사되고 있습니다.
그 후, 게르가노프 씨는 LLAMA를 사용한 추론을 macOS·Linux·Windows에서 동작시키는 프로젝트 "flama.cpp"의 개발을 진행해, M1 탑재 MacBook Pro로 LLAMA를 동작시키는 것에 성공했다고 보고했습니다. 게르가노프 씨에 의하면, LLAMA의 13B 모델을 M1 탑재 Mac에서, 초당 10 토큰의 처리 속도로 동작이 가능하다고...
「LLaMA」를 Mac에서도 실행 가능, 대규모 언어 모델을 보통의 소비자용 하드웨어로 실행
일상생활에서 AI의 사용에 대한 관심이 높아지고있는 가운데, OpenAI의 GPT-3나 Microsoft의 Kosmos-1 등 LLM(대규모 언어 모델)이 주목을 받아, 2023년 2월에 Meta가 새로운 LLM인 LLAMA를 발표했습니다. 이 LLaMA
doooob.tistory.com
그러던 중 2023년 3월 31일 저스틴 튜니 씨는 llama.cpp의 C++ 소스 코드에 업데이트를 추가했다고 보고했습니다. 튜니 씨의 업데이트 결과, LLaMA 실행 시 메모리 사용량이 대폭 감소하였고, 기존 30GB 필요했던 LLaMA의 13B 모델의 메모리 사용량이, 시스템 메모리의 사용량을 포함해 불과 5.8GB에서도 문제없이 작동했다고 보고하였습니다.
보고자 pugzly 씨는 "처음에는 버그라고 생각했지만 응답의 품질 저하는 느껴지지 않습니다. 요 전날 lama.cpp에 큰 변화가 있었던 것 같습니다만, 그 변경의 근본적인 부분은 나에게 는 이해할 수 없습니다"라고 놀라움을 감출 수 없는 모습.
튜니 씨에 따르면, mmap을 사용한 가중치의 로딩을 llama.cpp에 구현한 것으로, 실제의 추론에 필요한 부분의 가중치만 사용자 메모리에 로드되게 하여, 기존보다 적은 메모리 사용량 실현이 가능했다는 것.
튜니 씨는 "이 변경으로 추론 커맨드의 로드가 최대, 기존의 100배 빨라졌고, 2배 이상의 모델을 안정적으로 탑재할 수 있을 가능성이 있다. 또한, 추론 처리를 동시에 다수 진행시킬 수 있다"라고 장점을 강조했습니다.
한편 튜니 씨는 "내 이론이 잘못되어 이것이 단순한 버그일 수도 있다. 나도 LLAMA의 30B 모델의 내부 구조를 잘 이해하지 못하기 때문에, 왜 메모리 사용량이 줄어든 지 명확하게 알지 못하겠다."라고 말했습니다.

해커스 뉴스는 "메모리 사용량 절감으로 인한 성능 향상은 llama.cpp의 사용 편의성에 있어서 큰 발전입니다. 하지만, 튜니 씨가 메모리 사용량 감소에 성공한 이유를 설명하기에 충분한 이론은 아직 없다."라며, 사용자들에게 흥분을 자제하길 바라는 글을 남기고 있습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 스탠퍼드 대학이 「AI Index Report 2023」을 공개, AI의 실태를 보고 (1) | 2023.04.07 |
|---|---|
| Meta가 사진에 찍힌 물체를 분리하는 AI 모델 'Segment Anything Model' 공개 (0) | 2023.04.07 |
| 넷상의 영상은 더 이상 신용할 수 없는 세상이 도래 (0) | 2023.04.06 |
| Midjourney와의 비교를 통해 본「Adobe Firefly」의 저작권 콘텐츠 회피 (0) | 2023.04.05 |
| 「제어 불능인 AI 개발 경쟁」의 일시 정지를 요구하는 공개 서한에 가짜 서명자가 다수 (0) | 2023.04.03 |
| 무료로 노트북도 실행 가능한 70억 파라미터 채팅봇 「GPT4ALL」 발표 (0) | 2023.04.02 |
| 검열 없는 채팅 AI 「FreedomGPT」는 안전 필터가 없다 (0) | 2023.04.02 |
| 오픈 소스 ChatGPT 「YakGPT」등장, 음성 입력도 가능 (0) | 2023.04.01 |



