
한 장의 이미지를 바탕으로 다른 분위기의 이미지를 만드는 기술은 2022년에 이미 등장했지만, 그 기술을 그대로 영상에 적용하려 하면 프레임과 프레임의 연결이 골치 아프고, 반대로 프레임 간의 연결을 중시해 버리면 프레임 한 장, 한 장의 퀄리티가 떨어지는 문제가 발생합니다. TokenFlow는 와이츠만 과학 연구소의 연구자 그룹이 개발한 기법으로, 영상 프레임 사이의 일관성과 퀄리티를 유지하면서도 그 분위기만 바꿀 수 있는 기법입니다.
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
https://arxiv.org/abs/2307.10373
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
The generative AI revolution has recently expanded to videos. Nevertheless, current state-of-the-art video models are still lagging behind image models in terms of visual quality and user control over the generated content. In this work, we present a frame
arxiv.org
아래의 영상은 실제 TokenFlow를 이용해 생성된 것입니다.
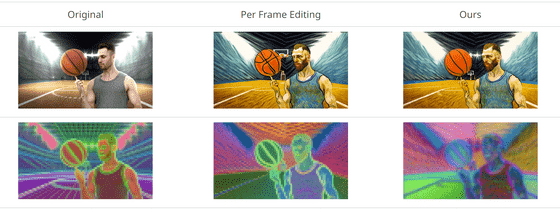
한 남자가 손가락 위에서 농구공을 돌리고 있습니다. 이것이 원래의 영상입니다.

「Shiny silver robot(빛나는 은색 로봇)」이라는 프롬프트를 주면 남자는 요구대로 변신합니다.

「Van Gogh Style(반 고흐풍)」입니다. 외형은 회화스럽지만, 남자와 공의 움직임은 매우 부드럽습니다.

「Star wars clone trooper(스타워즈 클론 트루퍼)」라고 지정하면 배경까지 우주처럼 변하고 있습니다.

기존의 「프레임마다 분위기를 변경해 가는」 기법에서는, 농구공에 그어진 선의 위치 등, 전후 프레임을 바탕으로 적절한 위치에 배치할 필요가 있는 요소들의 취급에 서툴렀습니다만, TokenFlow를 이용하면 원본 영상과 동등한 수준의 일관성을 유지하는 것이 가능해졌습니다.
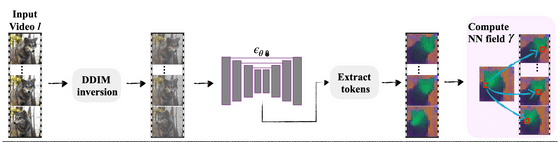
TokenFlow에서는 먼저 입력된 영상의 각 프레임을 DDIM으로 반전시켜 토큰을 추출합니다. 이어서, 최근접 이웃 탐색(Nearest neighbor search, NNS)을 이용하여 프레임 간 특징의 대응 관계를 추출합니다.
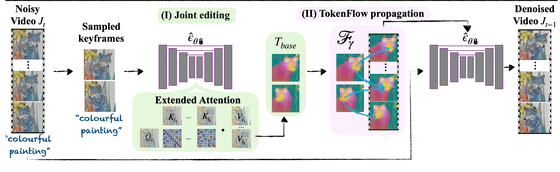
그리고 확산 모델의 노이즈 제거 페이즈에 있어서, 노이즈가 혼잡한 영상으로부터 키프레임을 샘플링해, 확장 어텐션 블록을 사용해 일괄 편집해 「편집된 토큰」을 작성합니다. 여기서, 앞서 추출해 둔 프레임간의 특징의 대응을 이용해 「편집이 끝난 토큰」을 영상 전체에 적응하는 것으로 일관성을 확보하고 있습니다.
프로젝트 페이지에서는 다수의 견본이나, 다른 모델과의 비교 영상 등이 준비되어 있습니다.
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
(소리 주의! 링크에 방문하시면 샘플 영상이 바로 재생됩니다.)
https://diffusion-tokenflow.github.io/

또한, GitHub에 코드가 공개될 예정입니다만, 현시점에서는 「CODE IS COMING SOON!」이라고만 되어 있고, 아직 미공개 상태입니다.
https://github.com/omerbt/TokenFlow
GitHub - omerbt/TokenFlow: Official Pytorch Implementation for "TokenFlow: Consistent Diffusion Features for Consistent Video Ed
Official Pytorch Implementation for "TokenFlow: Consistent Diffusion Features for Consistent Video Editing" presenting "TokenFlow" - GitHub - omerbt/TokenFlow: Official Pytorch ...
github.com
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 3명의 AI 전문가가 미국 의회에서 증언, AI 연구의 1인자들의 시각은? (2) | 2023.07.27 |
|---|---|
| ChatGPT에 지시할 때, '처음'과 '마지막'에 요점을 쓰면 더 나은 답변이 돌아온다 (2) | 2023.07.27 |
| 최근 AI의 핵심 기술인 「트랜스포머」를 낳은 부모가 구글을 퇴사해 스타트업을 설립 (2) | 2023.07.27 |
| 대만의 TSMC가 AI용 고성능 반도체에 대응하는 첨단 공장을 신설 (2) | 2023.07.27 |
| ChatGPT의 지능이 급격히 떨어지고 있다는 연구 결과, 간단한 수학 문제 정답률이 98%에서 2%로 악화 (3) | 2023.07.25 |
| ChatGPT나 LiDAR 센서를 탑재한 가정용 로봇 개 「Unitree Go2」가 발매된다 (2) | 2023.07.25 |
| Stability AI가 ChatGPT와 동등한 성능을 가진 오픈소스 대규모 언어 모델 'FreeWilly' 공개 (3) | 2023.07.24 |
| 1만 종류를 넘는 대규모 언어 모델(LLM)을 시각화한 데이터 라이브러리 (3) | 2023.07.23 |



