캘리포니아 대학 버클리 대학교, 캘리포니아 대학교 샌디에이고 대학교, 카네기 멜론 대학교가 협력하여 설립한 오픈 연구 조직, Large Model Systems Org(LMSYS Org)가 공동으로 자체 개발한 대규모 언어 모델 벤치마크 플랫폼에서 Google의 채팅봇 AI 'Bard with Gemini Pro'의 벤치마크 점수가 OpenAI의 GPT-4의 일부 모델을 넘어 2위를 차지했다고 보고 했습니다.
LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys
LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys
huggingface.co

LMSYS Org는 대규모 언어 모델의 벤치마크 플랫폼 'Chatbot Arena'를 개발하고 있습니다. 이 벤치마크는 인간 유저를 오픈 채팅에 초대해, 익명의 AI 모델 2종류와 대화를 시킨 뒤에 투표를 실시해, 체스에서 이용되는 엘로 등급(Elo rating)으로 순위를 매긴다는 것입니다.
대화형 채팅 AI의 벤치마크 순위 공개, 1위는 GPT-4
대화형 채팅 AI의 벤치마크 순위 공개, 1위는 GPT-4
캘리포니아 대학 버클리 학교의 학생과 교원이 캘리포니아 대학 샌디에이고 학교와 카네기 멜론 대학과 협력하여 설립한 오픈 연구 조직 "Large Model Systems Org(LMSYS Org)"가 ChatGPT, Palm, Vicuna 등의 채
doooob.tistory.com
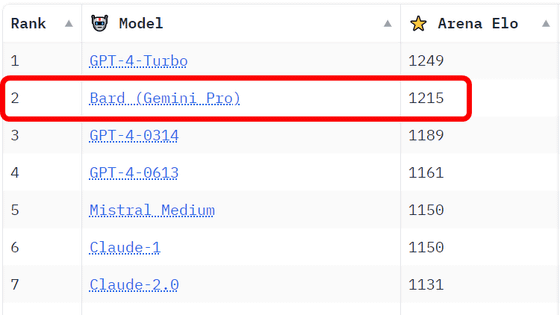
LMSYS Org에 따르면, Chatbot Arena의 엘로 등급 순위는
2024년 1월 26일 시점에서
1위가 OpenAI의 GPT-4 Turbo
2위가 Google의 Bard(Gemini Pro)
3위가 OpenAI의 GPT-4 버전 0314
4위가 OpenAI의 GPT-4 버전 0613입니다.
GPT-4 버전 0314는 Microsoft Azure에서 실행되는 GPT-4 모델 "Azure OpenAI Service"에서 처음 릴리즈 된 버전이며 GPT-4 버전 0613은 두 번째로 릴리스 된 버전입니다. 그리고 이번 GPT-4 모델에 이로레팅으로 뛰어난 Bard는 Google이 개발한 멀티 모달 AI Gemini Pro를 기반으로 한 "Bard with Gemini Pro"입니다.
각 모델의 1000회전에서의 레이팅 샘플링표와 대전 승률을 정리한 표가 아래와 같습니다.

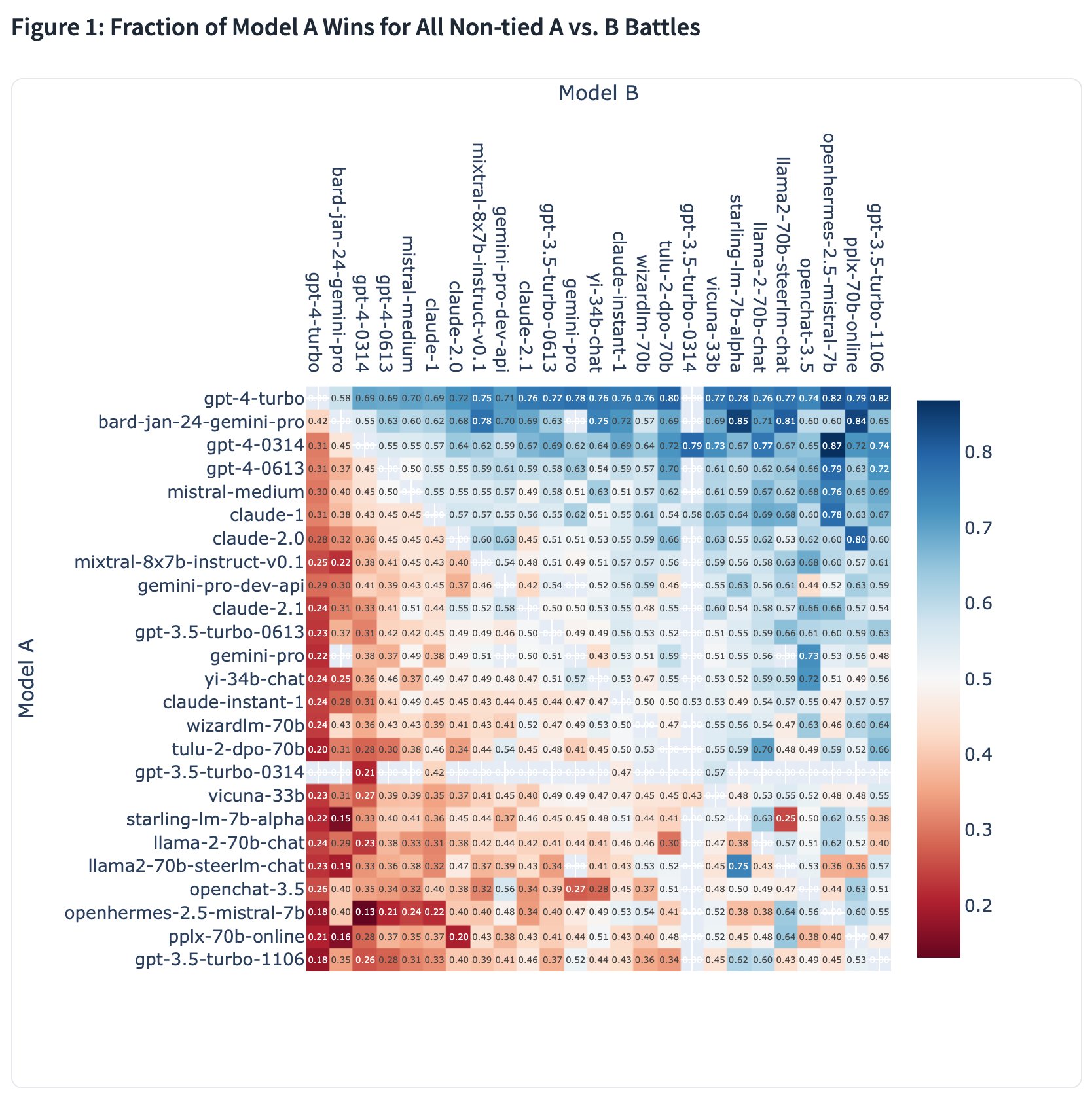
LMSYS Org는 "Google의 Bard가 훌륭한 약진을 이루고 GPT-4를 넘어 랭크 2위가 되었습니다. Google의 훌륭한 공적에 대해 큰 축복을!"라고 코멘트하고 있습니다. 게다가 향후 출시 예정인 Gemini Ultra 기반 Bard의 결과에 대해서도 기대하고 있습니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| Google이 AI로 파일 형식을 식별하는 도구 「Magika」를 오픈 소스로 공개 (81) | 2024.02.20 |
|---|---|
| 동영상을 보고 학습하는 아키텍처 「V-JEPA」를 Meta가 개발 (76) | 2024.02.20 |
| 중국에서 잇따라 AI 모델이 승인되고, 93조 규모의 AI 산업 시장으로 (111) | 2024.01.31 |
| Meta가 코드 생성 AI 모델의 새로운 버전 「Code Llama 70B」를 릴리스, 코드 정확성이 향상 (110) | 2024.01.31 |
| NVIDIA의 SDR의 영상을 HDR로 변환하는 AI 기술 「RTX Video HDR」 (99) | 2024.01.26 |
| 「인간형 로봇이 커피를 내리는 영상」AI 로보틱스의 미래에 있어서 자이언트 스텝 (110) | 2024.01.24 |
| AI 그림 앱「AI 피카소」, 1장의 전신 이미지로 댄스 동영상을 생성 (102) | 2024.01.24 |
| 아쿠타가와상 수상 작품 「도쿄도 동정탑」5% 내용은 생성 AI 사용 (105) | 2024.01.22 |



