
Google의 기계 학습 모델 "Transformer"는 데이터를 시계열로 처리하지 않고도 자연 언어 등의 데이터를 번역 및 텍스트 요약할 수 있으며, ChatGPT 등의 자연스러운 대화가 가능한 채팅 AI의 기반이 되고 있습니다. 또한, Transformer의 기법을 화상 분야에 응용한 모델이 「Vision Transformer」 입니다.
소프트웨어 엔지니어인 데니스 타프씨는 "Vision Transformer"의 컴포넌트가 어떻게 작동하고 데이터가 어떤 흐름을 따라가는지 시각화하여 설명하고 있습니다.
A Visual Guide to Vision Transformers | MDTURP
https://blog.mdturp.ch/posts/2024-04-05-visual_guide_to_vision_transformer.html

0 : 시작하며
전제로서, Transformer의 구조와 마찬가지로, Vision Transformer도 지도학습 트레이닝이 이루어지고 있습니다. 즉, 모델이 이미지와 그에 상응하는 라벨의 데이터 세트로 훈련되고 있다는 것입니다.

1: 하나의 데이터에 초점을 맞추는
'패치 크기 1'이라는 단일 데이터를 선택합니다.

2: 이미지 분할
Vision Transformer에서 처리할 수 있는 이미지를 만들기 위해 이미지를 동일한 크기의 패치로 분할합니다.

3 : 이미지 패치 플랫화
패치를 p'= p² * c"의 벡터로 변환합니다. 여기서 p는 패치의 크기, c는 분할된 패치 수입니다.

4 : 패치 포함 벡터 작성
선형 변환을 이용하여 벡터로 변환한 이미지 패치를 추가로 패치 포함 벡터로 변환합니다.

5 : 모든 패치에 적용
모든 패치를 패치 포함 벡터로 변환합니다. 그 결과, n×d로 표현되는 배열이 완성되었습니다. 여기서 n은 이미지 패치의 수이고 d는 패치 임베딩 벡터의 크기입니다.

6: 분류 토큰 추가
모델을 효과적으로 교육하기 위해 분류 토큰(cls 토큰)이라는 벡터를 추가합니다. 이 벡터는 네트워크의 학습 가능한 파라미터로, 랜덤 하게 초기화됩니다.

7 : 위치 포함 벡터 추가
이전 단계에서는 벡터에 위치 정보가 연결되지 않았습니다. 따라서 학습 가능하고 무작위로 초기화된 "위치 포함 벡터"를 cls 토큰을 포함한 모든 벡터에 추가합니다.
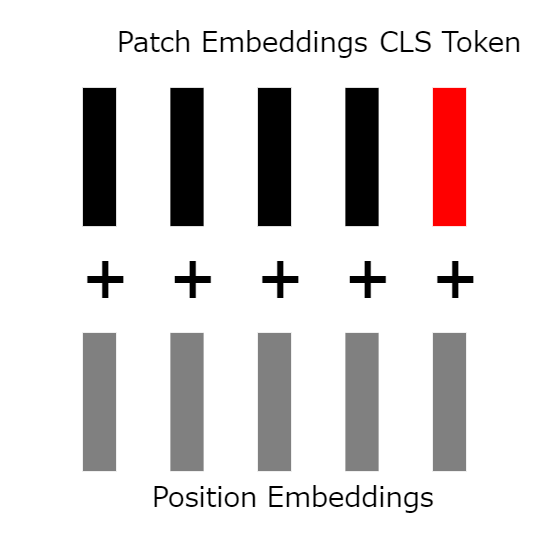
8:트랜스 입력
위치 매립 벡터가 추가되면, 사이즈(n+1)×d의 배열이 남게 되어, 이것은 변압기에의 입력에 대응합니다.

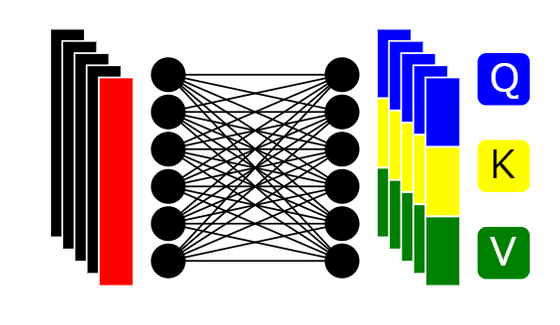
9:3종류의 벡터에의 배분
사이즈(n+1) ×d의 배열을 각각 Q에 해당하는 「쿼리 벡터」, K에 해당하는 「키 벡터」, V에 해당하는 「값 벡터」 로 배분합니다.
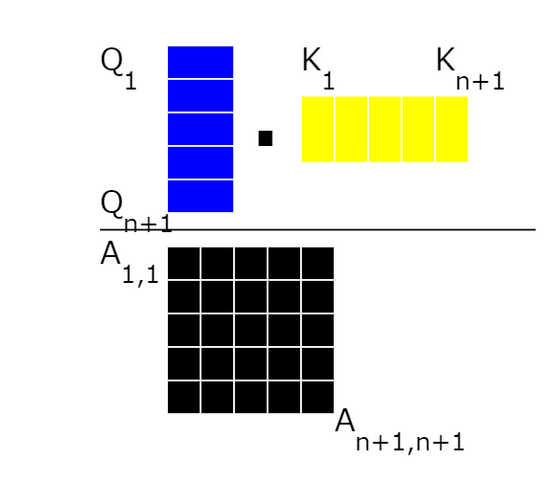
10 : 어텐션 스코어 계산
주의 스코어를 계산하기 위해 모든 쿼리 벡터와 키 벡터를 곱합니다.
11 : 어텐션 스코어 매트릭스
계산에 의해 어텐션 행렬을 얻었으므로 모든 행의 합계가 1이 되도록 "Softmax"함수를 모든 행에 적용합니다.

12 : 집계된 콘텍스트 정보 계산
행렬의 첫 번째 행에 주목하여 패치 포함 벡터의 집계된 콘텍스트 정보를 계산합니다. 그런 다음 전체를 값 벡터의 가중치로 사용하여 첫 번째 패치 포함 벡터의 집계된 콘텍스트 정보 벡터를 얻습니다.

13: 모든 행에 적용
어텐션 행렬 전체에 이 계산을 적용합니다. 그 결과, N+1개의 집계된 문맥 정보 벡터를 취득하게 됩니다.

14 : 프로세스 반복
이전의 프로세스를 헤드 수에 따라 여러 번 반복합니다. 그 결과, 복수의 집계된 문맥 정보 벡터가 출력되는 것입니다.
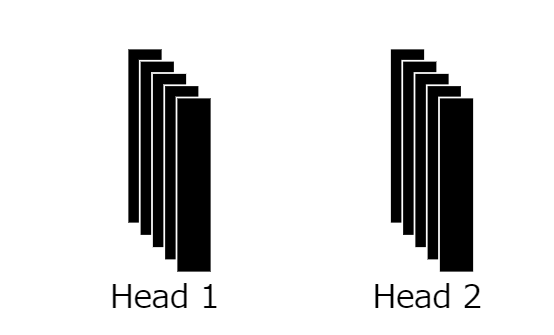
15 : 크기 d를 벡터에 매핑
여러 헤드를 통합하고 패치 포함 벡터와 동일한 크기 d의 벡터에 매핑합니다.

16:어텐션 레이어의 완성
벡터에의 매핑에 의해, 입력에 사용한 임베딩 벡터와 정확히 같은 사이즈로 동량의 임베딩이 완성되었습니다.

17 : 잔류 연결 적용
위치 내장 벡터가 추가된 레이어의 입력을 어텐션 레이어의 출력에 추가합니다.
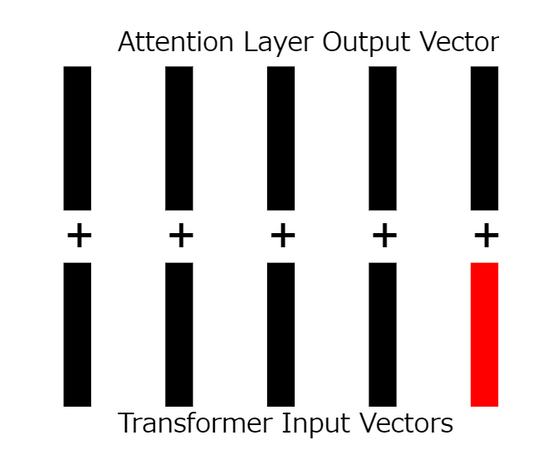
18 : 잔류 연결 계산
입력과 출력을 각각 추가합니다.

19 : 피드 포워드 네트워크
비선형 활성화 함수가 있는 피드 포워드 네트워크를 사용하여 지금까지 생성된 출력을 피드 합니다.

20 : 최종 결과
다중 처리를 수행하여 입력과 동일한 크기의 출력을 생성했습니다.
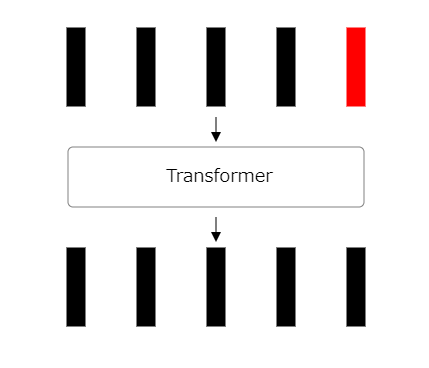
21 : 처리 반복
지금까지의 프로세스를 여러 번 반복합니다.
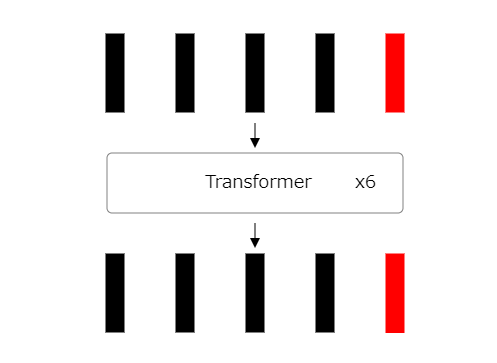
22: 분류 토큰 출력 식별
Vision Transformer에서 마지막 단계로 분류 토큰의 출력을 식별합니다.

23 : 분류 확률 예측 분류
토큰 출력과 완전히 연결된 다른 신경망을 사용하여 원본 이미지의 분류 확률을 예측합니다.
24: Vision Transformer 트레이닝
교차 엔트로피 오차를 사용하여 Vision Transformer를 트레이닝합니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 영상의 디테일을 살리면서 업스케일하는 AI 「VideoGigaGAN」 을 Adobe의 연구팀이 개발 (86) | 2024.04.26 |
|---|---|
| AI는 실제 인간의 얼굴보다 리얼해 보이는 얼굴을 만든다는 '하이퍼 리얼리즘' 의 문제점이란? (81) | 2024.04.25 |
| 영화의 배경 기술은 수작업에서 디지털로 어떻게 진화해 왔는가, 또한 AI 시대에는 어떻게 되어 갈 것인가? (81) | 2024.04.25 |
| Microsoft가 비용 효율적인 작은 언어 모델 「Phi-3」 을 출시, 오픈 모델에서 상용 이용 가능 (82) | 2024.04.25 |
| 상금 총액이 2억 7천만 원 이상인 AI 미인 콘테스트 「Miss AI」 를 개최 (79) | 2024.04.24 |
| 일상 회화를 녹음하고 요약할 수 있는 펜던트형 AI 가젯 「Pendant」가 등장 (67) | 2024.04.17 |
| 스탠퍼드 대학의 2024 AI 리포트 「AI Index Report 2024」 (67) | 2024.04.17 |
| Google이 AI로 무한 길이의 텍스트 처리 능력을 제공하는 기술 발표 (67) | 2024.04.16 |



