
지금까지 기계 학습 알고리즘을 공부해 왔습니다만, 이번에는 드디어 딥러닝 알고리즘에 들어갑니다. 처음에는 가장 대표적인 모델인 CNN(Convolutional neural network)에 대해 알아봅시다.
콘볼루션 신경망
CNN은 이미지 인식 등에 자주 사용되는 신경망의 구조이지만, 자연 언어 처리(NLP) 등 다른 용도로도 사용되고 있습니다. 이것은 한마디로 살인 현장에서 범인의 흔적과 특징을 찾아내어 추궁을 계속하여 마침내 범인을 찾아내는, 솜씨 좋고 민첩한 형사와 같습니다.
수학에 망원 급수(telescoping series)라는 것이 있습니다. 망원경이 겉의 통을 원하는 대로 죽 늘였다가 접을 수도 있듯이, 어떤 수열을 죽 늘였다가 중간의 항들을 다 삭제하여 끝의 항들, 또는 특정한 항들만 구하는 형태를 의미합니다. 위키에 따르면 '부분적 항들의 합이 소거 후에 결과적으로 고정된 값만이 남는 수열을 일컫는다'라고 되어 있습니다. telescoping(망원경), 즉 망원경의 통을 접은 것 같은 구조를 나타내고 있기 때문 Convolutional(주름)이라는 것입니다.

〇 입력 층 (Input Layer)
이미지 인식의 경우, 입력 층은 이미지 데이터입니다. 그림 1을 보면, 몇 개의 콘볼루션층의 뒤에 풀링층(Pooling layer)이 있고, 그것을 여러 번 반복한 후 전체 결합 층에서 결합된 다층 퍼셉트론이 배치되는 구성으로 되어 있습니다. 여기서는 변형된 층으로 나타내고 있지만, 각 층은 '[알기쉬운 AI - 18] 계층 신경망'에서 설명한 퍼셉트론 모델의 노드로 구성되어 있습니다(그림 2).
[알기쉬운 AI - 18] 계층 신경망
인간의 뇌는 뉴런(neuron)이라는 신경 세포의 네트워크 구조로 되어 있습니다. 뉴런에서 다른 뉴런에 신호를 전달하는 연결 부위를 시냅스라고 하고 뉴런은 시냅스에서 전기 및 화학 반응의 신호�
doooob.tistory.com

콘볼루션 층 (Convolutional layer)
콘볼루션 층은 원래의 이미지에서 필터에 의한 특징점을 응축하는 과정으로, 다음과 같은 특징이 있습니다.
· 콘볼루션 층은 원본 이미지에 필터를 걸어 특징 맵을 출력(구성성).
특징 맵의 크기는 원래 이미지보다 조금 작게(원래 이미지와 필터의 사이즈에 따라 크기가 달라진다).
· 전체 이미지를 필터로 슬라이드하기 때문에 특징이 어디에 있어도 추출할 수 있습니다(이동 불변성 또는 위치 불변성).
필터는 자동으로 생성된 학습을 통해 변함(오차 역전파).
· 필터의 수 만큼 특징 맵이 출력된다.
CNN의 설명은 이미지의 문자가 엑스(X)인지 판정하는 Rohrer 씨의 설명이 이해하기 쉽습니다. 이번에는 그것을 오마쥬 하여 오(O)를 분별하는 흐름으로 살펴보겠습니다(그림 3). OX 따위, 인간이라면 어린아이도 한눈에 알 수 있겠지요. 하지만 컴퓨터는 직관적인 인식이 어려우므로 픽셀 단위로 백(= -1)과 흑(1)의 화소를 인식할 수밖에 없습니다. 마치 "장님 코끼리 더듬기" 같네요
똑같은 크기와 모양의 문자라면, 픽셀의 전체 배치를 통째로 기록하고 그것과 비교하면 좋을 것입니다. 하지만 이 방법은 문자를 변형하거나 회전 또는 축소하면 다른 것으로 간주합니다.
그림 3에서는 원본 이미지 (9 × 9 픽셀)를 특징 = 필터(3 × 3 픽셀) 단위로 비교합니다. 이전에는 이러한 필터를 사람이 준비했습니다만, 딥러닝은 학습에 의해 자동 생성되며, 학습이 진행되면서 계속 변화합니다(파란색 필터는 O의 특징을 좋은 느낌으로 잡아내고 있군요). 원래 이미지가 각 필터의 특징과 일치하는지 여부를 수치로 계산하는 것이 컨볼루션 계산입니다. 원본 이미지 (9 × 9 픽셀)가 어떤 계산에 의해 오른쪽 특징 맵 (7 × 7 픽셀)의 수치가 되는지 그림 4로 나타냈습니다.
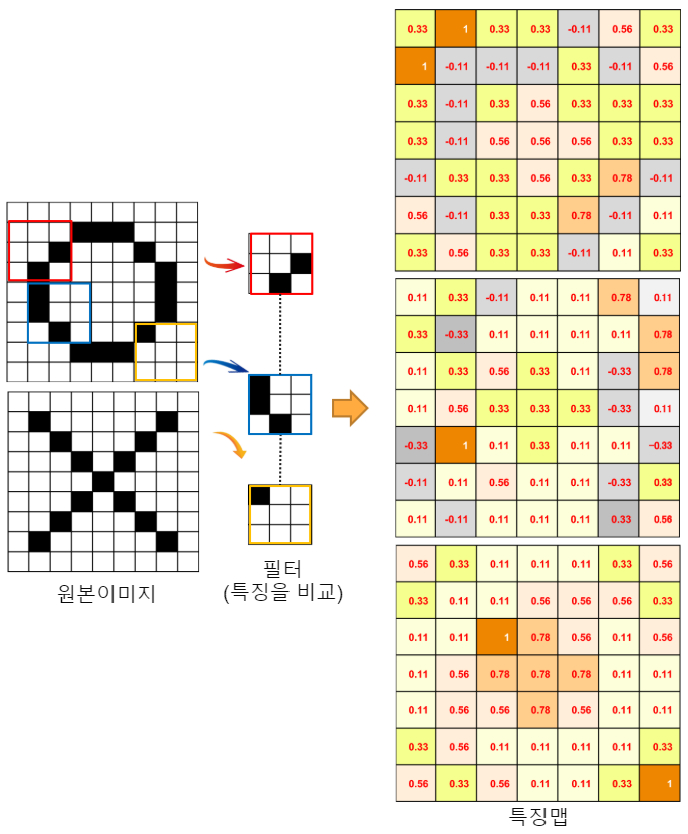

- 원본 이미지의 왼쪽에서 1픽셀마다 차례로 필터(특징)와 일치하는지 비교합니다.
- 흑이 1, 백이 -1이므로 숫자가 일치하면 흑은 1 × 1, 백은 -1 × -1으로 모두 1이며, 불일치하면 -1이 됩니다.
- 아홉 칸의 합계를 9로 나눈 수가 일치하도록 특징 맵으로 설정합니다.
예를 들어, 왼쪽 위의 필터와 비교하면 일치 5개, 불일치 4개 이므로 9개 조각, 총 (5 × 1) + (4 × -1) = 1이고 그것을 9로 나누어 0.11입니다. 이 수치가 1에 가까울수록 일치도가 높고, -1에 가까울수록 불일치라는 것입니다. 왼쪽부터 순서대로 해나가면, 9 × 9 조각이 7 × 7 조각으로 되는 것을 알 수 있습니다. 원본 이미지를 필터링한 것을 특징 맵이라고 합니다. 흑 1, 백 -1은 On / Off 숫자가 아닌 일치도를 나타내는 수치라는 것을 혼동하지 않도록 주의하십시오.
이러한 콘볼루션 계산은 단순 계산이지만 나름 양이 많습니다. 이 예는 흑백이기 때문에 채널은 1개이지만, 색상이라면 RGB로 표현되기 때문에 3 채널(원본 사진이 3장)이 되고, 그만큼 필터도 3배, 출력(특징 맵)도 3배가 됩니다. 보통의 사진을 분별한다고 가정하면, 특징 필터의 수와 딥러닝의 층의 깊이에서 엄청난 계산이 필요함을 쉽게 상상할 수 있습니다.
[알기쉬운 AI - 15] AI 관련 기술 전체상(Overview)과 하드웨어
먼저 AI를 지원하는 기술 기반은 어떻게 되어 있는지 큰 그림을 먼저 보겠습니다. 그림 1은 AI 관련 기술의 전체 상(Overview)입니다. 크게 4개의 층으로 구성되어 있습니다. (1) 하드웨어(칩과 서버) �
doooob.tistory.com
'[15] AI 관련 기술 전체상(Overview)과 하드웨어'의 AI칩에서 나왔던 일반적인 처리(if~ else~)에 적합한 CPU에 비해, 1개당 수십 ~ 수천 개의 코어를 가진 GPU는 간단한 처리(for ~ loop)에 적합하다고 설명했지만, 바로 이런 계산이 GPU에 적합합니다.
정규화 선형 단위 (ReLU : Rectified Linear Units)
이 계산을 좀 더 쉽게 해주는 것이 Rectified Linear Units라는 활성화 함수입니다. 이것은 x가 정 때는 F(x) = ax 부정인 때는 F(x) = 0 이 되는 함수로, 램프 함수라고 합니다.
콘볼루션 계산 결과 중 마이너스 수치는 일치도가 낮기 때문에 0으로 처리합니다. 활성화 함수는 입력 신호의 합을 어떻게 판정(활성화 = 발화)할지 계산하는 것으로, 전 결합층의 마지막에 OX를 판정하는 softmax도 활성화 함수입니다.
풀링 층 (Pooling layer)
그림 1을 다시 참조하십시오. 여러 번 콘볼루션 처리를 반복한 후에 풀링 층이 이어지고 있습니다. 풀링 층은 이전 이미지에 비해 그 크기가 상당히 작아지고 있습니다만, 무엇을 하는 것일까요?
풀링 층의 특징은 중요 정보를 유지하면서 원본 이미지를 축소합니다. 4개의 픽셀을 1픽셀에 응축하는 그림 5의 예에서 살펴보겠습니다. 콘볼루션 계산 결과를 왼쪽부터 순서대로 4픽셀씩 추출하여 이 4픽셀 중 최댓값을 대표로 선택하여 1픽셀의 이미지로 설정합니다. 왼쪽에서 4칸씩 추출하기 때문에 특징 맵이 홀수가 나오면 마지막이 조금 겹치지만 풀링 된 사진을 보면 제대로 원본 이미지의 특징을 가지고 있으며, 4분의 1로 응축되어 있는 느낌입니다. 이 풀링 된 이미지가 다음 콘볼루션 층의 입력 이미지로 되어 이전의 층과는 다른 새로운 필터 군과 비교될 것입니다.

특징을 유지하면서 정보량을 삭감한다는 것은 차원의 저주에서 탈출하기 위해 차원 감소를 했던 것과 같네요. 특징점을 추출하여 압축하는 처리를 반복하여 다운 스트림 컴퓨팅을 돕는 것이 CNN 딥러닝입니다.
풀링은 특징 위치 감도를 저하시켜 위치에 대한 안정성을 높이는 효과도 있습니다. 풀링 처리함으로써 이미지가 몇 픽셀 이동하거나 회전하거나 해도 그 차이를 흡수하여 거의 동일한 값을 출력해주는 것입니다.
전결합 층 (Fully Connected layer)
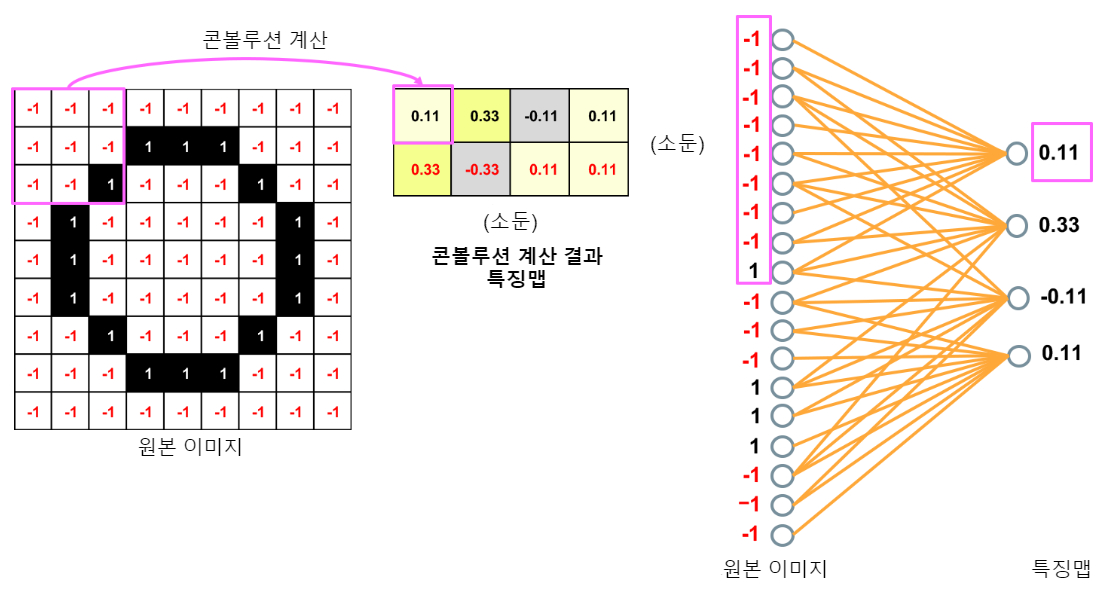
다층 퍼셉트론의 결합을 나타내면 그림 6과 같이 됩니다. 노드에서 노드에 모두 결합하는 것이 전 결합이고, 반대가 비(非)전결합입니다. 사실 콘볼루션 계층은 전체 결합을 계산하면 처리가 방대해져 버리기 때문에 비 전결합으로 처리하고 있습니다.

그러면 그림 5의 일부를 써서 노드로 표시해 봅시다. 그림 7을 보면 이제 아시겠죠. 인접한 9조각(9 노드) 마다 비껴가며 3 노드로 결합하는 비(非)전결합으로 처리하고 있었던 것입니다. 풀링 층에서도 동일합니다. 이쪽은 인접한 4 조각(4 노드)마다 1 노드에 결합하고 있었던 것입니다.
아직 데이터 압축이 충분하지 않은 단계에서 전결합 계산을 하면 계산 볼륨이 방대해지기 때문에 이런 식의 계산을 하고 있었던 것입니다. 9 × 9의 81 노드가 7 × 7의 49 노드에 전결합 되어있는 상태와 비교해 보면 크게 계산이 감소하는 것을 알 수 있습니다. 또한 결합마다 가중치를 부여하는 것은 어려워서 여러 결합 가중치를 공유하는 기술도 사용되고 있습니다.
이번에는 OX의 두 가지 이므로 출력 계층은 2 노드입니다. 설명의 편의상, 중간 과정은 생략하고 위 풀링의 3개의 결과 투표로 OX여부를 결정한다고 가정해 봅시다(그림 8). 투표라고 해도 단순한 다수결이 아니라 가중치에 차이가 있습니다. 예를 들어 파란색의 특징은 O밖에 없기 때문에 O에 대한 가중치가 크고, 붉은색과 노란색의 특징은 X도 있기 때문에 weight가 작다고 합시다. 파란색 자손의 의견이 강하고, 빨간색과 노란색의 의견이 약한 것은 그림 2와 동일한 원리입니다. 빨간색과 노란색이 몇 번쯤 X라고 착각해 버리고, 자신(필터 모양)을 바꾸고자 노력은 했지만 점점 신뢰(가중치)를 잃어 갔다는 슬픈 이야기에 관심이 있는 사람은, '[18] 계층 신경망'편의 오차 역 전파를 다시 읽어보십시오.

출력 레이어(Output layer)
그림 1의 출력 층에 softmax라는 설명이 있습니다. 이것도 활성화 함수로, 재판장과 같은 역할을 합니다. 나온 증거를 모두 음미하고 "그래, 본건은 0.93 대 0.07로 O로구나"라는 느낌으로 판결하는 확률 계산식입니다. 양자택일이라서 와 닿지 않을지도 모릅니다만, 예를 들면 257종류의 꽃의 이름을 맞추는 것 같은 경우에는 편리합니다.
정리
처음에, CNN을 솜씨 좋은 형사로 비유했습니다. 막연한 상황 속에서 단서(특징)를 찾아 그것을 추구하고 결국 확실한 증거를 잡아내는 모습이 조금은 비슷하지요? 그리고 '필터'는 형사의 조수로, 범인의 얼굴을 찾아내는 몽타주 화가입니다. 몽타주 화가는 그 사람의 특징을 잡아내는 천재입니다. 실제를 그대로 그리는 것이 아니라, '데포르메(대상을 사실적으로 묘사하지 않고 일부 변형, 축소, 왜곡을 가해서 표현하는 기법)'하기 때문에 더욱 유사합니다. 형사와 몽타주 화가가 한 팀으로 깊이 있게 다양한 가중치의 정황과 증거를 제시하여, 결국 "그래, 내가 죽였다"라고 자백을 받아내고야 마는 것입니다.
'AI · 인공지능 > 알기쉬운 AI' 카테고리의 다른 글
| [알기쉬운 AI - 32] 신경망은 만능인가...? (1) | 2021.10.24 |
|---|---|
| [알기쉬운 AI - 31] GAN (Generative Adversarial Networks) (3) | 2020.06.07 |
| [알기쉬운 AI - 30] LSTM (Long Short-Term Memory) (0) | 2020.05.29 |
| [알기쉬운 AI - 29] RNN(Recurrent Neural Network) (1) | 2020.05.23 |
| [알기쉬운 AI - 27] 클러스터링 (Clustering) (0) | 2020.05.07 |
| [알기쉬운 AI - 26] 분류 (Classification) (0) | 2020.04.26 |
| [알기쉬운 AI - 25] 회귀 (Regression) (0) | 2020.04.25 |
| [알기쉬운 AI - 24] Q 학습 (Q-Learning) (0) | 2020.04.04 |



