
데이터 분석 툴 등을 제공하는 기업인 Databricks가, 2024년 3월 27일에 오픈한 범용 대규모 언어 모델(LLM)인 「 DBRX 」 를 발표했습니다. 오픈 라이센스로 배포되며 월간 활성 사용자가 7억 명 이하인 기업은 무료로 상용 이용도 가능하다고 합니다.
Introducing DBRX: A New State-of-the-Art Open LLM | Databricks
Introducing DBRX: A New State-of-the-Art Open LLM | Databricks
www.databricks.com

DBRX는 트랜스포머 디코더를 사용하는 LLM으로 "mixture-of-experts(MoE)" 아키텍처가 채용되고 있습니다. 파라미터의 총수는 1320억으로 되어 있지만, 모든 입력에 반응하는 것은 360억 파라미터만으로, 나머지 파라미터는 「전문가」 로서의 수요에 따라 활성화됩니다. MoE(mixture-of-experts) 아키텍처를 채용하는 것으로, 사이즈를 억제해 고효율의 학습이나 추론을 가능하게 하여 성능을 높였다고 합니다.
마찬가지로 MoE 아키텍처를 채용한 Mixtral과 Grok-1이 8명의 전문가를 탑재하고 입력마다 2명을 활성화하는 반면 DBRX는 16명의 「전문가」 를 탑재하여 입력당 4명을 활성화합니다. 「전문가」 의 조합수가 65배가 됨으로써 모델의 품질이 향상되었다고 합니다.
또한 DBRX는 최대 콘텍스트 길이 32,000 토큰의 총 12조 토큰 데이터로 교육되었습니다. 「전문가」 가 혼재하는 MoE 모델을 트레이닝하는 것은 어려웠지만, 효율적인 방법으로 반복 트레이닝할 수 있는 견고한 파이프라인을 개발해, 누구라도 DBRX 레벨의 MoE 기초 모델을 처음부터 트레이닝할 수 있게 했다고 합니다.
아래 도표는 「 언어 이해 」, 「 프로그래밍 」, 「 수학 」 의 벤치마크 결과로, DBRX는 LLAMa2-70B나 Mixtral, Grok-1등의 모델보다 좋은 결과를 내고 있습니다. 또한 「전문가」 를 탑재함으로써 범용 성능을 확보하면서 프로그래밍 등 특화가 필요한 영역에서의 성능도 확보하고 있습니다.

또한 "GPT-3.5", "GPT-4", "Claude 3 시리즈", "Gemini 1.0 Pro", "Gemini 1.5 Pro", "Mistral"과 같은 클로즈드 소스의 LLM과 비교한 결과는 아래 표와 같습니다. DBRX Instruct는 Gemini 1.0 Pro나 Mistral Medium 등과 동등한 수준으로 보입니다.
| 모델 | DBRX Instruct |
GPT-3.5 | GPT-4 | Claude 3 Haiku | Claude 3 Sonnet | Claude 3 Opus | Gemini 1.0 Pro | Gemini 1.5 Pro | Mistral Medium | Mistral Large |
| MT Bench ( Inflection correctod , n=5) | 8.39±0.08 | — | — | 8.41±0.04 | 8.54±0.09 | 9.03±0.06 | 8.23±0.08 | — | 8.05±0.12 | 8.90±0.06 |
| MMLU 5-shot | 73.7% | 70.0% | 86.4% | 75.2% | 79.0% | 86.8% | 71.8% | 81.9% | 75.3% | 81.2% |
| HellaSwag 10-shot | 89.0% | 85.5% | 95.3% | 85.9% | 89.0% | 95.4% | 84.7% | 92.5% | 88.0% | 89.2% |
| HumanEval 0-Shot pass@1 (Programming) |
70.1% temp=0, N=1 |
48.1% | 67.0% | 75.9% | 73.0% | 84.9% | 67.7% | 71.9% | 38.4% | 45.1% |
| GSM8k CoT maj@1 | 72.8% (5-shot) | 57.1% (5-shot) | 92.0% (5-shot) | 88.9% | 92.3% | 95.0% | 86.5% (maj1@32) |
91.7% (11-shot) | 66.7% (5-shot) | 81.0% (5-shot) |
| WinoGrande 5-shot | 81.8% | 81.6% | 87.5% | — | — | — | — | — | 88.0% | 86.7% |
추론의 효율을 나타내는 「 1초 ・1 유저당의 출력 토큰수 」 는 아래 그림과 같습니다. 어느 유저 수에 대해서도, 보다 작은 모델인 Mixtral-8x7B가 최대 출력을 자랑하고 있습니다. 한편, 붉게 표시되어 있는 DBRX의 추론 효율은 LLaMa2-70B나 Dense-132B를 크게 웃돌았습니다.
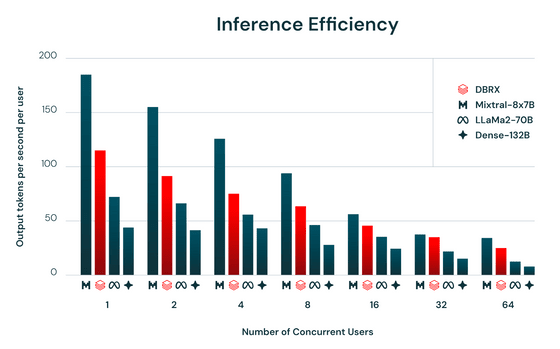
기본 모델인 DBRX Base와 파인 튜닝된 모델 DBRX Instruct는 모두 Hugging Face에서 오픈 라이센스로 배포되고 있으며 Databricks의 Foundation Model API 를 통해 쉽게 이용 가능하다고 합니다.
'AI · 인공지능 > AI 뉴스' 카테고리의 다른 글
| 무료로 1개월에 1200곡까지 AI 작곡이 가능한 「Udio」 퍼블릭 베타판이 공개 (52) | 2024.04.12 |
|---|---|
| OpenAI가 이미지를 읽을 수 있는 AI 「 GPT-4 Turbo with Vision」 을 일반에 공개 개시 (56) | 2024.04.11 |
| Hugging Face도 뚫렸다? 신뢰할 수 없는 AI 모델을 실행하면 AI를 통해 시스템에 침입할 수 있음을 경고 (5) | 2024.04.09 |
| 「Llama 2 70B」와 「Stable Diffusion XL」이 추가된 AI 벤치마크 테스트 「MLPerf Inference v4.0」 발표 (56) | 2024.03.29 |
| 30배나 빠른 AI 이미지 생성 기법을 매사추세츠 공과대학이 개발 (51) | 2024.03.28 |
| 「조기 사망률」,「다른 도시나 나라로 이사할 것인가」 등 인생을 예측하는 AI 개발 (51) | 2024.03.28 |
| 대규모 언어 모델의 계산 능력을 증강하는 커스터마이즈 하드웨어를 만드는 스타트업「MatX」 (51) | 2024.03.28 |
| OpenAI가 동영상 생성 AI 「 Sora 」의 동영상 샘플을 대량 공개 (52) | 2024.03.28 |



