
지금까지의 내용에서는「출력에 대한 설명의 생성」기법으로서, SHAP라고 불리는 기법을,「해석 가능한 모델의 추출」기법으로서 심층 학습 모델을 의사결정 트리로 옮겨놓거나, 모델의 예측 구조를 추출하는 GoldenEye라는 기술을 소개했습니다. 이어서 XAI 의 마지막 글인 이번 편에서는,「블랙박스 내용의 검사」에 관한 기법과「투명성 있는 학습기의 설계」에 관한 XAI 기법에 대해서 소개합니다.
XAI 기법의 분류를 다시 적어보면 다음과 같이 됩니다.
・출력에 대한 설명의 생성
・해석 가능한 모델의 추출
・블랙박스 내용의 검사(이번에 소개하는 부분)
・투명성 있는 학습기의 설계(이번에 소개하는 부분)
블랙박스 내용의 검사
블랙박스 내용을 검사하는 기법에서는 모델이 어떻게 작동하는지, 그리고 왜 그 예측을 수행하는지의 관점에서 모델을 설명합니다. 예를 들어, 이미지에 무슨 일이 일어나고 있는지 결정하는 이미지 분류 모델을 생각할 때, 이미지의 어떤 부분이 모델 예측에 기여하는지 설명합니다.
이 기술의 대표적인 것으로는 Integrated Gradient 라고 불리는 기술이 있습니다. Integrated Gradient 는 다음 두 가지 특성을 충족하도록 설계된 기술입니다.
· Sensitivity(감도) : 입력에 대한 출력이 베이스라인의 출력과 다른 경우, 베이스라인과 다른 값을 갖는 입력의 특징량의 기여도는 0이 아니다.
baseline과 input과의 차이가 오직 하나의 feature이고 baseline의 예측과 input의 예측이 다른 경우를 가정해 보겠습니다.
이런 상황에서는 차이나는 feature가 모델의 예측에 영향을 끼쳤다고 생각할 수 있습니다.
이렇게 차이나는 feature는 non-zero의 attribution의 값을 가져야 합니다.
그리고 이러한 조건이 만족된다면, sensitivity 조건을 만족하게 됩니다.
· Implementation Invariance(구현시의 불편성) : 구현 방법이 다르더라도, 동일한 입력에 대해 구해지는 기여도는 동일하다.
서로 다른 network이지만 같은 input ~ output 관계를 가진다면, 두 network는 동일한 attribution을 가져야 합니다.
이러한 특성을 implementation invariance라고 합니다.
gradient는 sensitivity하지는 않지만, chain rule이 성립하기 때문에,
implementation invariant하다는 장점을 가지고 있습니다.
직관적으로, 두 특성 모두 특징량의 기여도를 계산할 때 만족해야 할 것으로 보입니다. 상이한 입력(특징량)에 대해, 상이한 출력이 되었을 경우에는, 그 특징량은 모델의 예측에 기여하고 있다고 생각하는 것이 보통이며, 또한 구현에 의해 기여도가 같다고 하는 성질도 당연한 성질처럼 여겨집니다.
블랙박스의 내용을 검사하는 방법의 대표적인 접근법은 그라디언트 정보를 사용하는 것입니다.
그라디언트 정보는 입력이 약간 변경될 때 출력이 얼마나 변하는지에 대한 정보입니다. 직관적으로, 그라디언트 정보를 사용하여 입력 기여도를 확인할 수 있습니다. 그러나 그라디언트 정보는 Sensitivity 라는 특성을 충족시키지 못합니다. 이를 살펴보기 위해 다음과 같은 함수를 한번 봅시다.

여기서 베이스라인으로 x=0 을 입력 값으로 하고, x=2 를 위의 함수에 적용합니다. 다른 입력 값에 대해 다른 값이 출력되기 때문에 x 라는 특징량이 모델 예측에 기여하고 있음을 알 수 있습니다. 그러나, 위 함수의 기울기는 x=2일 때 0 이 되어 버리기 때문에, 특징량의 기여도를 그라디언트를 이용해 계산하면, 기여도는 0 이 되어 버립니다. 이러한 일이 일어나지 않도록 Sensitivity 라는 성질을 충족시키는 정보가 필요합니다.
Integrated Gradient 는 위의 두 가지 특성을 충족하도록 설계된 간단한 기술입니다.
이것을 식으로 나타내면 다음과 같이 됩니다.
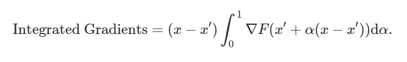
여기서 x 는 입력값,
x' 은 기준선,
F 는 신경망(즉, 입력을 제공할 때 예측값을 반환하는 함수),
α 는 0 에서 1 을 취하는 값,
▽는 기울기를 나타냅니다.
즉, Integrated Gradient 는 '입력'과 '베이스라인'간의 차와 그라디언트 정보를 누적한 것의 곱입니다.
오른쪽의 α를 0 에서 1 로 변경하면 기준선 x' 에서 입력 x 까지의 모든 기울기 정보를 더한 값이 계산됩니다.
위의 예에서 볼 수 있듯이 한 점의 기울기 정보만으로는 Sensitivity 라는 특성을 충족시킬 수 없었지만 베이스라인(입력과 다른 값)에서 입력까지의 기울기 정보를 더함으로써 , Integrated Gradient 는 0 이 아니게 됩니다. 이것을 이용하여, 이미지 분류 모델의 입력 기여도를 가시화해 본 것이 아래의 그림입니다.
또한 이미지 분류 모델의 베이스라인은 새까만 이미지가 사용됩니다.
왼쪽부터 차례대로
입력 이미지,
그 추론 결과,
Integrated Gradient를 가시화한 것,
Gradient 정보를 가시화한 것입니다.

단순히 그라디언트 정보만 고려하는 경우와 비교하면
Integrated Gradient 를 이용한 경우에는 인간이 주목하는 부분과 비슷한 부분에 주목하여 모델이 예측을 하고 있다는 것을 알 수 있습니다.
또한 아래는 텍스트 분류 모델에 Integrated Gradient 를 적용한 예입니다.
이 작업은 질문에 대한 답변이 어떤 종류의 답변인지 예측합니다. 예를 들어, 대답이 숫자인지, 날짜인지 또는 단순한 문자열인지를 예측합니다.

붉은 단어가 많을수록 모델 예측에 기여한다는 것을 나타냅니다. 확실히, how many 나 year 등에 주목하여 예측을 실시하고 있다는 것을 이 예로부터 알 수 있습니다.
또한, Integrated Gradient 는 범용적인 기법이며, 원논문에서는 기계어 번역이나 어느 분자가 활성화하는지 등의 문제에도 적용하고 있습니다.
흥미가 있으신 분들은 Integrated Gradient의 원논문을 읽어 보시길 권해드립니다.
투명한 학습기 설계
지금까지는, 내용물을 알 수 없는 블랙박스 모델을 어떻게 설명할 것인가 하는 관점에서 XAI 의 각 기법을 살펴보았습니다. 그러나 모델이 꼭 블랙박스일 필요성은 없으며, 처음부터 설명하기 쉬운 모델로 만들어 버리면, 그 추론 결과를 다양한 방법으로 설명할 필요도 없어집니다. 이러한 동기부터 투명성 있는 학습기를 설계하려는 연구가 이루어져 왔습니다.
XAI를 다룬 첫 글에서도 언급했듯이, 인간이 이해하기 쉬운 모델로는 의사결정 나무나 룰 베이스(규칙 기반) 모델 등이 있습니다. 이 중에서 가장 이해하기 쉬운 모델은 룰 베이스(규칙 기반) 알고리즘입니다. 이것은, X 라고 하는 입력이 주어지면 Y 라고 하는 예측을 돌려주는 것처럼, 룰을 미리 만들어 둔다는 것입니다.
그러나 여러분도 아시다시피, 룰 베이스의 알고리즘은 해석하기 쉬운 만큼, 정밀도가 나쁘다는 문제가 있습니다. 이 문제를 해결하는 유명한 기술로는 Interpretable Decision Sets(IDS)가 있습니다. IDS 제안 이전의 연구로서, decision lists 라고 불리는 것이 주류였습니다. 이것은 아래의 오른쪽 그림과 같이 if-else 구문으로 구성됩니다. 언뜻 보면, 딱히 문제가 없는 것처럼 보이는 decision lists 이지만 해석이 어렵다는 큰 문제가 있습니다. 첫 번째 규칙으로 입력이 걸리면 해석은 간단하지만, else 가 하나라도 끼게 되면 곧 해석이 어려워집니다.
한편, IDS 에서는 아래의 왼쪽 그림과 같이 if-then 구문으로 구성되어 있습니다.
즉, 1 개의 룰로 완결되므로, 해석성이 decision lists 에 비해 압도적으로 향상됩니다.

그렇다면 IDS 에서 어떻게 학습을 할 수 있을까요? IDS 에서는 해석성과 정밀도가 양립되도록 학습을 실시합니다.
해석성에 관해서는 아래의 4 가지 지표를 기준으로 해석성을 높입니다.
· size : 모델을 구축하는 규칙의 총 수. 하나의 if-then 을 일괄 처리한 총 수
· length : 하나의 if-then의 길이
· cover : 각 규칙이 얼마나 많은 데이터를 설명하는가
· overlap : 각 규칙이 얼마나 겹치는가
이 4 개의 지표 중에서 size · length · overlap 에 관해서는 최소화를 목표로 하고, cover 는 최대화를 목표로 학습을 실시합니다.
또한, 정밀도에 관해서는 이하의 2개의 지표를 기준으로 하여 정밀도를 높입니다.
· correct-cover : 특정 입력이 규칙을 충족하고 예측 라벨도 정확하다.
· incorrect-cover : 특정 입력이 규칙을 충족하지만 예측 라벨이 잘못되었다.
위의 기준을 바탕으로 모델을 구축합니다. 완성된 모델은 기존의 기법과 같은 정도의 정밀도이고, 해석성이 높다는 것이 실험으로부터 확인되었습니다.
요약
4 회에 걸쳐 설명 가능한 AI 에 대하여 알아보았습니다.
1 회에서는, 애당초 설명 가능한 AI가 왜 필요한가를 소개하였고, 나머지 3 회에 걸쳐서 대표적 XAI 기법에 대하여 소개하였습니다.
심층 학습 모델이 세상을 떠들썩하게 하고 있습니다만, 심층 학습 모델을 사용할 때에는 해석성이 희생되어 버립니다. 향후, 심층 학습 모델이 일반적으로 사용되기 위해서는 인간이 해석하기 쉽다는 성질을 높여가야 합니다. 그렇게 할 수 없다면, 고전적이긴 하지만, 보다 해석하기 쉬운 로지스틱 회귀 등의 모델이 계속 사용될 것입니다. 또한 이러한 현상을 바탕으로 심층 학습 모델뿐만 아니라 고전적 기법도 제대로 이해하고 최적의 모델을 선택하는 것이 매우 중요하다고 생각하고 있습니다.
인간과의 친화성을 높이는 설명 가능한 AI 에 대하여, 이 글을 통해 그 중요성을 이해하고, 흥미를 가져 주셨으면 좋겠습니다.
[알기쉬운 AI - 34] 설명 가능한 AI(XAI : Explainable AI) 1 - AI의 예측에 근거는 필요한가?
설명 가능한 AI( Explainable AI, 이후 XAI )라는 단어를 들어 보신 적 있습니까? XAI는 AI 예측의 근거를 예측과 함께 출력하는 AI입니다. 특히 최근 주목을 받고 있는 심층 학습이 대두된 후 XAI의 중요성
doooob.tistory.com
[알기쉬운 AI - 35] 설명 가능한 AI(XAI : Explainable AI) 2 - XAI의 적용 방법
이전 글에서는 설명 가능한 AI( XAI )란 무엇인가를 예를 들어서 설명하였습니다. XAI 에는 다음과 같은 네 가지 프레임워크가 있습니다. ・출력에 대한 설명의 생성 ・해석 가능 모델의 추출 ・블
doooob.tistory.com
[알기쉬운 AI - 36] 설명 가능한 AI(XAI : Explainable AI) 3 - 해석 가능한 모델의 추출
이전 글에서는「출력에 대한 설명의 생성」기법으로서, SHAP라고 불리는 기법을 소개했습니다. 이것은 경제학에서 사용되는 Shapley value 를 이용하여 각 특징량의 공헌도를 계산하고, 그것을 바탕
doooob.tistory.com
'AI · 인공지능 > 알기쉬운 AI' 카테고리의 다른 글
| [알기쉬운 AI - 39] AI 보안 2 - AI에 대한 공격 매커니즘 (3) | 2023.06.13 |
|---|---|
| [알기쉬운 AI - 38] AI 보안 1 - AI에 보안이 필요한가? (1) | 2023.03.17 |
| [알기쉬운 AI - 36] 설명 가능한 AI(XAI : Explainable AI) 3 - 해석 가능한 모델의 추출 (0) | 2023.02.02 |
| [알기쉬운 AI - 35] 설명 가능한 AI(XAI : Explainable AI) 2 - XAI의 적용 방법 (0) | 2023.01.20 |
| [알기쉬운 AI - 34] 설명 가능한 AI(XAI : Explainable AI) 1 - AI의 예측에 근거는 필요한가? (0) | 2022.11.06 |
| [알기쉬운 AI - 33] CNN이란 어떤 것인가? (0) | 2022.10.10 |
| [알기쉬운 AI - 32] 신경망은 만능인가...? (1) | 2021.10.24 |
| [알기쉬운 AI - 31] GAN (Generative Adversarial Networks) (3) | 2020.06.07 |



