
이전 글에서는 왜 AI에 보안이 필요한지 몇 가지 사례를 들어 알아봤습니다. 이번에는, 구체적으로 AI 공격에는 어떠한 기법이 있는지 알아보겠습니다. 보안 분야에서는, 공격 기법과 방어 기법 양쪽 다 알아두는 것이 중요하므로, 이 다음 글에서는 방어 기법에 대해 소개하겠습니다.
AI 모델에 대한 공격 설정
최근 여러 곳에서 AI가 활용되고 있습니다. 상황에 따라 실행 가능한 공격은 달라지므로, 먼저 그 점을 명확히 해야 합니다.
크게 나누어 AI에 대한 공격은 다음 두 가지로 나눌 수 있습니다.
・White Box 공격
・Black Box 공격
화이트 박스 공격은 공격자가 공격 대상 AI 모델에 관련된 모든 정보를 알 수 있는 상황에서의 공격입니다.
예를 들어, 모델의 파라미터, 입력에 대한 모델의 예측 확률, 정답이 있는 데이터에 대한 모델의 출력과 정답의 차이 등을 들 수 있습니다. 이것은 보통, AI 모델 개발자 및 내부자 밖에는 알 수 없는 정보입니다. 반대로 말하면 그다지 현실적이지 않은 공격이라고도 할 수 있습니다.
블랙박스 공격은 대상이 되는 AI 모델의 일부 정보 밖에 모르는 상황에서의 공격입니다.
예를 들어, Google이나 Microsoft가 공개하고 있는 API를 떠올려 주시면 알기 쉬울 것입니다. 공격자가 얻을 수 있는 이러한 모델의 정보는 입력에 대한 모델의 예측 확률뿐입니다. 경우에 따라서는 모델의 예측 라벨만을 얻을 수 있습니다. 그러나 이러한 상황에서도 AI 모델에 공격을 가할 수 있습니다.
이렇게 AI에 대한 공격 상황을 알았는데요,
그러면 White Box 공격, Black Box 공격의 대표적인 공격 기법 2가지를 알아보겠습니다.
화이트 박스 공격
■ Adversarial Attack(적대적 공격)
아래 그림을 보고 여러분은 무엇을 떠올리셨습니까? 중앙에는 노이즈 같은 것이 있고, 양 옆에는 팬더가 있다고 생각하셨을까요?
확실히 인간의 눈에는 양쪽 이미지가 팬더로 보입니다.
그러나 이미지 분류 모델에 오른쪽 이미지를 입력하면 '긴팔원숭이'라는 결과가 반환됩니다.

왜 이미지 분류 모델이 오른쪽 이미지를 "긴팔원숭이"라고 잘못 인식했을까요? 이는 이미지 분류 모델이 Adversarial Attack 이라는 공격을 받았기 때문입니다. 이 Adversarial Attack의 핵심은 중앙에 있는 랜덤 노이즈로 보이는 이미지입니다. 이 이미지를 왼쪽 이미지에 추가했기 때문에 AI 모델은 잘못된 판단을 해버립니다.
그렇다면 이러한 이미지를 어떻게 만드는지가 중요합니다. 여기서 공격자는 모든 정보에 액세스 할 수 있다고 가정합니다. 즉, White Box인 상황을 생각해 보십시오.
대답은 매우 간단합니다. 모든 정보에 액세스 할 수 있다면 원본 이미지를 변경할 때 출력이 어떻게 바뀔지 알 수 있습니다. 이 정보를 이용하여 원본 이미지를 점진적으로 변화시켜 이미지 분류기를 속이는 이미지를 생성할 수 있게 됩니다. 이때 가능한 한 작은 변화로 공격을 완성함으로써 인간은 구별이 어렵기 때문에 작은 변화량이라는 제약하에 이미지를 변화시켜 나갑니다.
■ 백도어 공격
최근 백도어 공격이라는 공격이 매우 주목을 받고 있습니다. 그 이유는 AI 모델에 미치는 영향이 매우 크다는 것입니다. 백도어란, 보안 분야에서 사용되는 말로, 공격자가 1번 공격을 성공한 후에 다시 공격을 쉽게 하기 위해 실시하는 작업입니다. AI 백도어 공격이란, AI 모델에 백도어를 내장하고, 그 후 공격자의 트리거를 더한 데이터를 입력하면 공격자의 의도대로 AI 모델이 예측한다는 것입니다.
이전 글에서도 소개했습니다만, 예를 들면, 얼굴 인증 시스템에 있어서 이 공격이 가해지면, 안경을 쓰고 있는 사람을 시스템 관리자라고 오인식해 버립니다. 안경처럼 물리적 트리거는 화각이나 빛의 반사로 보이는 방식에 거의 영향을 미치지 않기 때문에 매우 위험한 공격이 됩니다. 한편, 앞서 소개한 Adversarial Attack의 경우는 빛의 반사 방식에 따라서 오인식되지 않는 경우도 있다고 알려져 있습니다.

이제 백도어 공격 절차를 살펴보겠습니다. 여기에서도 White Box 상황을 가정합니다. 공격자는 먼저 트리거가 될 패턴을 결정합니다. 예를 들어, 아래 그림의 우측 하단에 찍힌 흰 점이 트리거가 되는 경우를 생각할 수 있습니다. 또는 점점이 이어진 모양이 트리거가 되는 등 다양한 트리거를 생각할 수 있습니다.

공격자는 원본 이미지와 트리거를 부여한 이미지를 모두 사용하여 모델을 학습합니다. 트리거를 부여한 이미지를 입력하면 실제 라벨과 다른 라벨(타깃 라벨)을 부여하여 학습합니다. 덧붙여 오리지널의 이미지도 함께 학습하는 이유는, 백도어를 설치한 것을 걸리지 않기 위함입니다. 트리거를 부여하지 않았을 때, 보통의 동작을 하지 않으면, 그 단계에서 이미 모델이 변경되었다고 의심을 받게 됩니다.

블랙박스 공격
■ GAN을 이용한 공격
GAN이라는 AI 업계에서 매우 유명한 알고리즘을 아십니까?
GAN은 Generative Adversarial Network의 약자로 '적대적 네트워크'라고도 불립니다. GAN이란, 간단히 말하자면 생성기(G)와 식별기(D)의 2개가 서로 적대적인 학습을 실시하는 것입니다.
G는 생성된 이미지를 가능한 한 원본에 가깝게 하고, D는 입력된 이미지가 진짜인지, 아니면 G가 생성한 가짜인지 높은 정밀도로 식별하도록 학습을 합니다. 이것을 나타내는 것이 아래 그림입니다.

G와 D 가 서로 정밀도를 높이려고 적대적으로 학습함으로써, 궁극적으로 G 가 생성하는 이미지는 인간으로서는 진짜인지 가짜인지 판별할 수 없는 것입니다. GAN에 대해 더 자세히 알고 싶으신 분은 아래를 참고하세요.
[알기쉬운 AI - 31] GAN (Generative Adversarial Networks)
시작하기 CNN, RNN, LSTM 등 3회에 걸쳐 딥러닝을 지원하는 대표적인 알고리즘을 알아봤습니다. 이번에는 적대적 생성 네트워크 GAN과 DCGAN을 소개합니다. 지금까지 봤던 식별과 회귀 등의 인공지능
doooob.tistory.com
이 GAN이라는 알고리즘을 사용하면 일부 정보만 얻을 수 있는 상황에서도 공격이 가능합니다. 이제 멀웨어 감지를 수행하는 AI 모델을 생각해 봅시다. 이 AI 모델은 데이터를 입력하면 데이터가 악성코드인지 아닌지 예측합니다. 이 예측 결과를 사용하여 멀웨어 감지를 수행하는 모델의 출력을 모방합니다. 이 모방 모델이 완성되면 GAN의 구조를 이용하여 멀웨어 감지 모델을 속이는 데이터를 생성할 수 있습니다. 아래 그림은 멀웨어 감지 모델을 속이는 메커니즘을 보여주는 그림입니다.

공격자는 생성기 G를 준비하고 모방 모델 D를 속이도록 적대적으로 학습합니다. 이렇게 하면 결국 생성기는 모델을 속이는 데이터를 생성할 수 있습니다.
■ 데이터 오염 공격
마지막으로 매우 흥미로운 공격을 소개합니다. 공격자는 모델 개발에 사용되는 데이터에만 액세스 할 수 있다고 가정합니다. 즉, 데이터에 라벨을 지정하거나 모델을 학습하는 과정에는 전혀 개입할 수 없습니다. 이러한 상황에서도 데이터를 오염시키면 모델에 공격을 가할 수 있습니다.
첫째, 공격자는 세 가지 데이터를 준비합니다.
· 입력 이미지 x
· 타겟 이미지 t
· 원본 이미지 b
그런 다음, 아래 공식을 사용하여 오염된 데이터를 생성합니다.
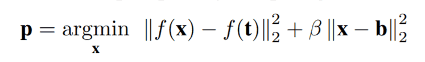
여기서 f는 사전 학습된 모델을 나타냅니다. 위의 방정식이 의미하는 바는, 사전 학습된 모델을 사용하여 x 와 t 로부터 특징량을 추출하고 그 특징량을 비슷하게 하여 x 와 b(원본 이미지의 외형)를 비슷하게 만든 데이터 p 를 생성합니다. 이렇게 생성된 데이터 p 는 특징량 레벨에서 타겟 이미지 t 와 유사하고, 외형은 원본 이미지 b 와 유사합니다.
이 데이터를 사용하여 사용자가 모델을 학습하려 하면 이상한 일이 벌어집니다. 사용자가 데이터 p 에 라벨을 붙일 때, 외형은 원본 이미지 b 와 유사하기 때문에 원본 이미지 클래스를 부여합니다. 그리고, 완성된 모델은 타겟 이미지 t 를 원본 이미지 b 의 클래스로 오분류해 버립니다. 이것은, 특징량 레벨에서는 t 에 가까운 이미지인데, b 클래스라고 라벨링해 버렸기 때문입니다. 이를 통해 공격자는 모델 학습 과정에 어떠한 개입도 없이 모델을 공격할 수 있습니다. 아래 그림은 타겟 이미지가 개이고 원본 이미지가 물고기인 경우를 보여줍니다. 이 때, 개의 이미지를 입력하면, 이 모델은 물고기라는 예측 결과를 출력해 버립니다.

요약
이번에는 AI 모델에 대한 공격으로 White Box 공격과 Black Box 공격이 있다는 것, 그리고 각각의 구체적인 공격을 2개씩 소개했습니다. 이번에 소개한 기법 외에도 많은 공격 기법들이 있어, 모든 공격을 막는다는 것은 불가능합니다. 그러나 어떤 공격이 있는지 파악하고 방어책을 세우면, 공격을 받을 위험을 줄일 수 있습니다. 다음에는 AI에 대한 공격을 방어하는 방법에 대해 알아보겠습니다.
'AI · 인공지능 > 알기쉬운 AI' 카테고리의 다른 글
| [알기쉬운 AI - 38] AI 보안 1 - AI에 보안이 필요한가? (1) | 2023.03.17 |
|---|---|
| [알기쉬운 AI - 37] 설명 가능한 AI(XAI : Explainable AI) 4 - 블랙 박스인가 투명성인가 (0) | 2023.03.07 |
| [알기쉬운 AI - 36] 설명 가능한 AI(XAI : Explainable AI) 3 - 해석 가능한 모델의 추출 (0) | 2023.02.02 |
| [알기쉬운 AI - 35] 설명 가능한 AI(XAI : Explainable AI) 2 - XAI의 적용 방법 (0) | 2023.01.20 |
| [알기쉬운 AI - 34] 설명 가능한 AI(XAI : Explainable AI) 1 - AI의 예측에 근거는 필요한가? (0) | 2022.11.06 |
| [알기쉬운 AI - 33] CNN이란 어떤 것인가? (0) | 2022.10.10 |
| [알기쉬운 AI - 32] 신경망은 만능인가...? (1) | 2021.10.24 |
| [알기쉬운 AI - 31] GAN (Generative Adversarial Networks) (3) | 2020.06.07 |



