5.8 통계
여기서는 몇 가지 자주 사용되는 통계를 설명합니다. 통계는 관측된 데이터의 특징을 요약한 수치를 말합니다. 대표적인 통계로는 평균, 분산, 표준편차가 있습니다.
5.8.1. 평균
평균(mean)은 관측된 수치를 합산하여 그 수치의 개수로 나눈 것을 말합니다. 예를 들어, 300원, 400원, 500원의 평균은
300 + 400 + 500 / 3 = 400입니다.
일반적으로 N개의 데이터 xi(i=1,…,N) 이 관측되었을 때, 그 평균은
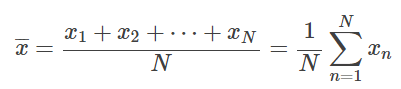
로 정의됩니다. 평균을 나타내는 기호로,

나

가
자주 사용됩니다. 데이터의 분포에서 평균은 그 중심에 해당하는 값입니다.
5.8.2. 분산
다음으로, 분산 (variance)을 소개합니다. 분산은 보통

로 표시되며,
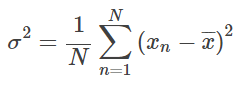
로 정의됩니다. 각 데이터 xi(i=1,…,N) 값에서 그 평균값
를 이끌어내어 제곱한 값

의 평균을 계산합니다. 이것은 "데이터가 자신의 평균보다 얼마나 흩어져 있는지"를 나타냅니다. 평균이 같은 데이터라도 많은 데이터가 평균 근처에 모여있으면 분산은 작고, 평균보다 매우 큰 데이터나 작은 데이터가 많으면 분산은 커집니다. 분산에는 또 다른 종류가 있습니다. 그것은 아래와 같습니다.

처음에 등장한
의 정의는 N분의 1이었던 부분이 N−1분의 1로 변해 있습니다.
전자는 표본 분산(sample variance)이라고 하고, 후자는 불편 분산(unbiased variance)이라고 합니다. 이러한 식의 도출 과정은 다른 문헌에 양보하기로 하고, 여기에서는 그 구분에 대하여 설명합니다.

예를 들어, 전국 초등학생의 신장 및 체중의 분산을 조사하고자 합니다. 이때 전국의 초등학생을 하나도 빠짐없이 조사했다면, 수집한 데이터는 모집단(population)이라고 합니다. 한편, 각 시마다 초등학생 100명씩 조사한 경우, 그 데이터는 표본집단 (sample population)이라고 합니다. 즉, 모집단이란 분석을 수행하고자 하는 데이터 전체 집합을 말하며, 표본집단이란 모집단에서 추출된 일부 데이터의 집합을 말합니다.
일반적으로 표본 집단의 데이터 수가 적으면 표본 분산은 모집단의 분산보다 작은 것으로 알려져 있습니다. 불편 분산은 그 차이를 보정하여 모집단의 분산을 보다 정확하게 추정하기 위해 사용합니다. 불편 분산 추출하는 데이터의 수(N)를 늘리면 결국 모집단의 분산과 일치합니다. 또한, N이 커지면 표본 분산과 편견 분산은 거의 일치하기 때문에 많은 데이터 수를 취할 수 있는 상황에서는 양자에 큰 차이가 없는 경우도 많습니다.
분산을 사용하면 데이터의 변화를 정량적으로 평가할 수 있게 됩니다. 예를 들어, 같은 현상을 여러 번 관찰하는 실험을 실시했을 때 결과의 차이가 크면, 그 관측 방법에 문제가 있을 수 있습니다. 혹은 같다고 생각했던 현상이 실은 관측마다 다른 현상이었을 가능성이 있습니다. 이처럼 다수의 시행 결과가 특정 값으로 귀결될 것으로 예상될 때, 그 변화의 정도를 정량 평가하는 것은 중요합니다.
5.8.3. 표준 편차
다음은 표준 편차(standard deviation)를 소개합니다. 분산은 데이터 평균의 차이를 제곱하여 평균을 낸 것입니다. 따라서 단위도 원래의 단위를 제곱한 것이 됩니다. 예를 들어 데이터의 단위가 kg이라면 분산의 단위는 kg제곱이 됩니다.
따라서, 분산
의 제곱근 σ를 계산하는 것으로, 데이터와 단위가 동등해지며 해석이 용이해집니다.
이 제곱근 σ를 표준 편차라고 합니다.
연습 문제를 통해 구체적인 계산절차를 확인해 봅시다.
다음의 ①과 ②의 데이터에 대한 평균, 분산, 표준 편차를 구하십시오.
단, 표본 분산을 사용하는 것으로 하겠습니다.

①의 해답은 다음과 같습니다.
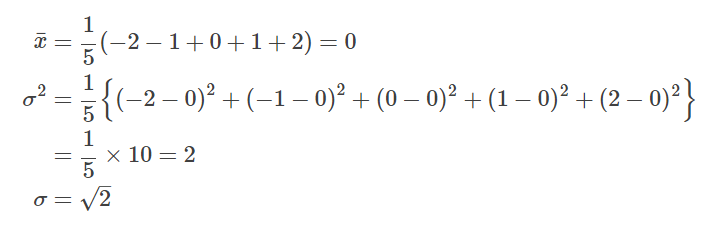
②의 해답은 다음과 같습니다.

이로부터, ②의 케이스가 분산이 크고, 데이터의 편차가 큰 것을 알 수 있습니다.
5.8.4. 상관 계수
마지막으로 상관 계수(correlation coefficient)를 소개합니다.
2종류의 데이터를 얻을 수 있는 상황에서 양자의 관계성 분석이 종종 필요합니다.
상관 계수는 양자의 관련 정도를 정량적으로 측정하는 데 사용합니다.
2 종류의 데이터가 스칼라 값 N개씩 있는 상황을 생각해 보겠습니다. 각각을

라고 하면, 상관 계수 중에서도 자주 사용되는 피어슨 상관 계수는 다음과 같이 정의됩니다.
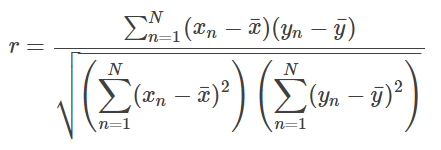
위 식과 같이 상관 계수를 나타내는 기호는 r을 사용하는 것이 일반적입니다. 상관 계수 r은 항상 −1 ≤ r ≤ 1 가 되어, 상관이 인정될 때, r값이 양수이면 긍정적인 상관관계가 있다고 말하며, 반대로 음수이면 음의 상관관계가 있다고 합니다.
2 종류의 데이터 사이의 상관관계가 강할수록 r의 절대 값은 커집니다. 하지만 「r이 몇 이상이면 상관이 있다고 여겨도 된다」고 여겨지는 임계 값은 태스크에 따라 다르며 예를 들어, r=0.2에서 상관관계가 있다고 판단해도 좋을지는 말할 수 없습니다. 본 문서에서 자세한 설명은 생략합니다만, 무(無) 상관 검정 등의 방법을 이용하면 객관적인 판단이 가능합니다.
'AI · 인공지능 > 딥러닝 Tutorial' 카테고리의 다른 글
| [딥러닝 입문 - 6] 단일 회귀 분석과 다중 회귀 분석(4/4) (0) | 2021.07.31 |
|---|---|
| [딥러닝 입문 - 6] 단일 회귀 분석과 다중 회귀 분석(3/4) (0) | 2021.06.19 |
| [딥러닝 입문 - 6] 단일 회귀 분석과 다중 회귀 분석(2/4) (0) | 2021.06.03 |
| [딥러닝 입문 - 6] 단일 회귀 분석과 다중 회귀 분석(1/4) (0) | 2021.05.30 |
| [딥러닝 입문 5] 확률·통계의 기초(4/5) (0) | 2021.03.09 |
| [딥러닝 입문 5] 확률·통계의 기초(3/5) (0) | 2021.02.22 |
| [딥러닝 입문 5] 확률·통계의 기초(2/5) (0) | 2021.02.12 |
| [딥러닝 입문 5] 확률·통계의 기초(1/5) (0) | 2021.01.18 |



